 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt Takes Two: A Duet of Periodicity and Directionality for Burst Flicker Removal
Mar 24, 2026Flicker artifacts, arising from unstable illumination and row-wise exposure inconsistencies, pose a significant challenge in short-exposure photography, severely degrading image quality. Unlike typical artifacts, e.g., noise and low-light, flicker is a structured degradation with specific spatial-temporal patterns, which are not accounted for in current generic restoration frameworks, leading to suboptimal flicker suppression and ghosting artifacts. In this work, we reveal that flicker artifacts exhibit two intrinsic characteristics, periodicity and directionality, and propose Flickerformer, a transformer-based architecture that effectively removes flicker without introducing ghosting. Specifically, Flickerformer comprises three key components: a phase-based fusion module (PFM), an autocorrelation feed-forward network (AFFN), and a wavelet-based directional attention module (WDAM). Based on the periodicity, PFM performs inter-frame phase correlation to adaptively aggregate burst features, while AFFN exploits intra-frame structural regularities through autocorrelation, jointly enhancing the network's ability to perceive spatially recurring patterns. Moreover, motivated by the directionality of flicker artifacts, WDAM leverages high-frequency variations in the wavelet domain to guide the restoration of low-frequency dark regions, yielding precise localization of flicker artifacts. Extensive experiments demonstrate that Flickerformer outperforms state-of-the-art approaches in both quantitative metrics and visual quality. The source code is available at https://github.com/qulishen/Flickerformer.
READ-Net: Clarifying Emotional Ambiguity via Adaptive Feature Recalibration for Audio-Visual Depression Detection
Jan 21, 2026Depression is a severe global mental health issue that impairs daily functioning and overall quality of life. Although recent audio-visual approaches have improved automatic depression detection, methods that ignore emotional cues often fail to capture subtle depressive signals hidden within emotional expressions. Conversely, those incorporating emotions frequently confuse transient emotional expressions with stable depressive symptoms in feature representations, a phenomenon termed \emph{Emotional Ambiguity}, thereby leading to detection errors. To address this critical issue, we propose READ-Net, the first audio-visual depression detection framework explicitly designed to resolve Emotional Ambiguity through Adaptive Feature Recalibration (AFR). The core insight of AFR is to dynamically adjust the weights of emotional features to enhance depression-related signals. Rather than merely overlooking or naively combining emotional information, READ-Net innovatively identifies and preserves depressive-relevant cues within emotional features, while adaptively filtering out irrelevant emotional noise. This recalibration strategy significantly clarifies feature representations, and effectively mitigates the persistent challenge of emotional interference. Additionally, READ-Net can be easily integrated into existing frameworks for improved performance. Extensive evaluations on three publicly available datasets show that READ-Net outperforms state-of-the-art methods, with average gains of 4.55\% in accuracy and 1.26\% in F1-score, demonstrating its robustness to emotional disturbances and improving audio-visual depression detection.
Deep Learning in Concealed Dense Prediction
Apr 15, 2025Deep learning is developing rapidly and handling common computer vision tasks well. It is time to pay attention to more complex vision tasks, as model size, knowledge, and reasoning capabilities continue to improve. In this paper, we introduce and review a family of complex tasks, termed Concealed Dense Prediction (CDP), which has great value in agriculture, industry, etc. CDP's intrinsic trait is that the targets are concealed in their surroundings, thus fully perceiving them requires fine-grained representations, prior knowledge, auxiliary reasoning, etc. The contributions of this review are three-fold: (i) We introduce the scope, characteristics, and challenges specific to CDP tasks and emphasize their essential differences from generic vision tasks. (ii) We develop a taxonomy based on concealment counteracting to summarize deep learning efforts in CDP through experiments on three tasks. We compare 25 state-of-the-art methods across 12 widely used concealed datasets. (iii) We discuss the potential applications of CDP in the large model era and summarize 6 potential research directions. We offer perspectives for the future development of CDP by constructing a large-scale multimodal instruction fine-tuning dataset, CvpINST, and a concealed visual perception agent, CvpAgent.
Devil is in the Uniformity: Exploring Diverse Learners within Transformer for Image Restoration
Mar 26, 2025Transformer-based approaches have gained significant attention in image restoration, where the core component, i.e, Multi-Head Attention (MHA), plays a crucial role in capturing diverse features and recovering high-quality results. In MHA, heads perform attention calculation independently from uniform split subspaces, and a redundancy issue is triggered to hinder the model from achieving satisfactory outputs. In this paper, we propose to improve MHA by exploring diverse learners and introducing various interactions between heads, which results in a Hierarchical multI-head atteNtion driven Transformer model, termed HINT, for image restoration. HINT contains two modules, i.e., the Hierarchical Multi-Head Attention (HMHA) and the Query-Key Cache Updating (QKCU) module, to address the redundancy problem that is rooted in vanilla MHA. Specifically, HMHA extracts diverse contextual features by employing heads to learn from subspaces of varying sizes and containing different information. Moreover, QKCU, comprising intra- and inter-layer schemes, further reduces the redundancy problem by facilitating enhanced interactions between attention heads within and across layers. Extensive experiments are conducted on 12 benchmarks across 5 image restoration tasks, including low-light enhancement, dehazing, desnowing, denoising, and deraining, to demonstrate the superiority of HINT. The source code is available in the supplementary materials.
ICFRNet: Image Complexity Prior Guided Feature Refinement for Real-time Semantic Segmentation
Aug 25, 2024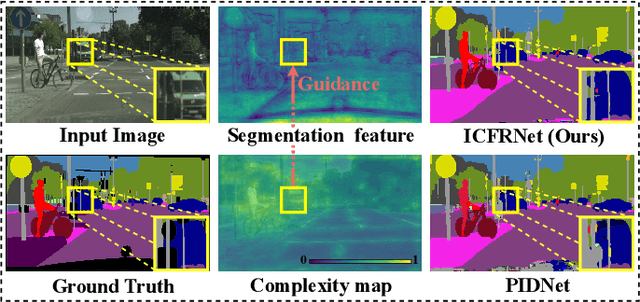
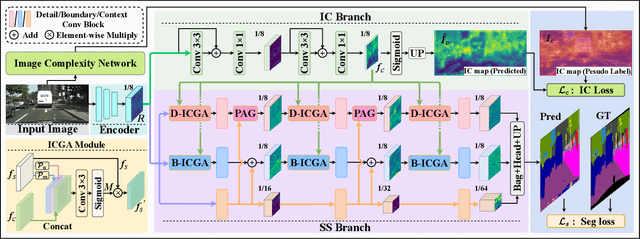
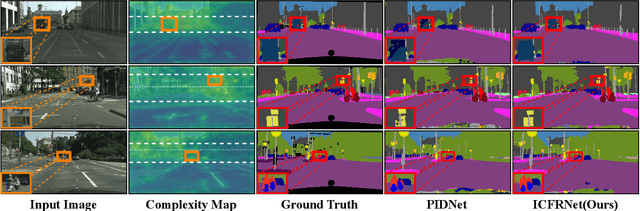
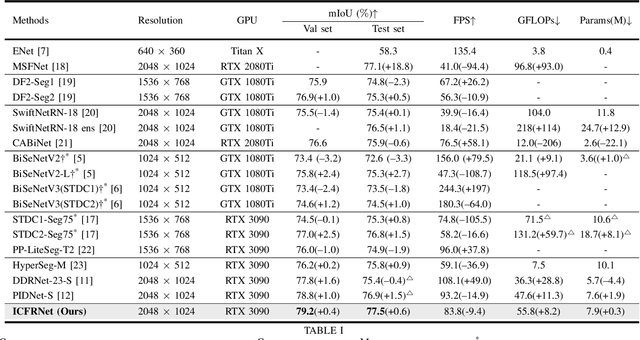
In this paper, we leverage image complexity as a prior for refining segmentation features to achieve accurate real-time semantic segmentation. The design philosophy is based on the observation that different pixel regions within an image exhibit varying levels of complexity, with higher complexities posing a greater challenge for accurate segmentation. We thus introduce image complexity as prior guidance and propose the Image Complexity prior-guided Feature Refinement Network (ICFRNet). This network aggregates both complexity and segmentation features to produce an attention map for refining segmentation features within an Image Complexity Guided Attention (ICGA) module. We optimize the network in terms of both segmentation and image complexity prediction tasks with a combined loss function. Experimental results on the Cityscapes and CamViD datasets have shown that our ICFRNet achieves higher accuracy with a competitive efficiency for real-time segmentation.
LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion
Apr 07, 2024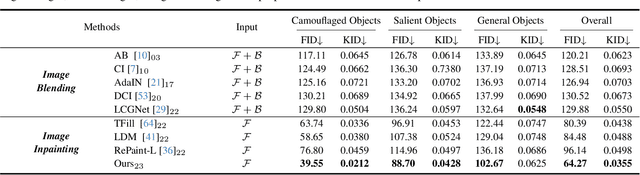
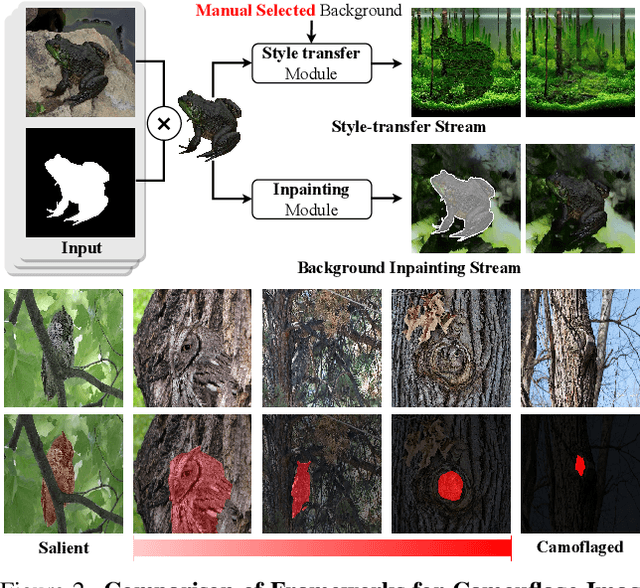
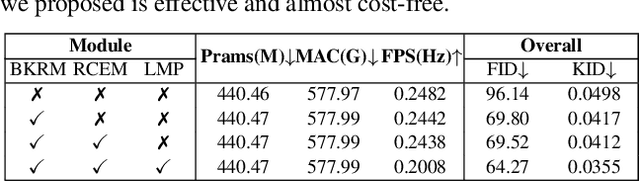
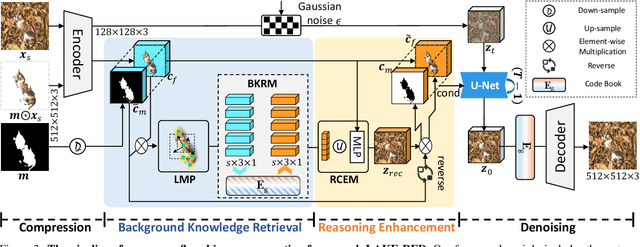
Camouflaged vision perception is an important vision task with numerous practical applications. Due to the expensive collection and labeling costs, this community struggles with a major bottleneck that the species category of its datasets is limited to a small number of object species. However, the existing camouflaged generation methods require specifying the background manually, thus failing to extend the camouflaged sample diversity in a low-cost manner. In this paper, we propose a Latent Background Knowledge Retrieval-Augmented Diffusion (LAKE-RED) for camouflaged image generation. To our knowledge, our contributions mainly include: (1) For the first time, we propose a camouflaged generation paradigm that does not need to receive any background inputs. (2) Our LAKE-RED is the first knowledge retrieval-augmented method with interpretability for camouflaged generation, in which we propose an idea that knowledge retrieval and reasoning enhancement are separated explicitly, to alleviate the task-specific challenges. Moreover, our method is not restricted to specific foreground targets or backgrounds, offering a potential for extending camouflaged vision perception to more diverse domains. (3) Experimental results demonstrate that our method outperforms the existing approaches, generating more realistic camouflage images.
Harmonizing Light and Darkness: A Symphony of Prior-guided Data Synthesis and Adaptive Focus for Nighttime Flare Removal
Mar 30, 2024


Intense light sources often produce flares in captured images at night, which deteriorates the visual quality and negatively affects downstream applications. In order to train an effective flare removal network, a reliable dataset is essential. The mainstream flare removal datasets are semi-synthetic to reduce human labour, but these datasets do not cover typical scenarios involving multiple scattering flares. To tackle this issue, we synthesize a prior-guided dataset named Flare7K*, which contains multi-flare images where the brightness of flares adheres to the laws of illumination. Besides, flares tend to occupy localized regions of the image but existing networks perform flare removal on the entire image and sometimes modify clean areas incorrectly. Therefore, we propose a plug-and-play Adaptive Focus Module (AFM) that can adaptively mask the clean background areas and assist models in focusing on the regions severely affected by flares. Extensive experiments demonstrate that our data synthesis method can better simulate real-world scenes and several models equipped with AFM achieve state-of-the-art performance on the real-world test dataset.
Spread Your Wings: A Radial Strip Transformer for Image Deblurring
Mar 30, 2024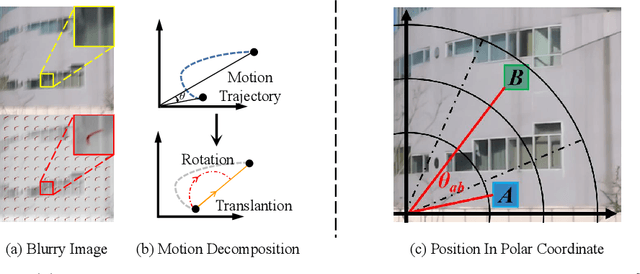
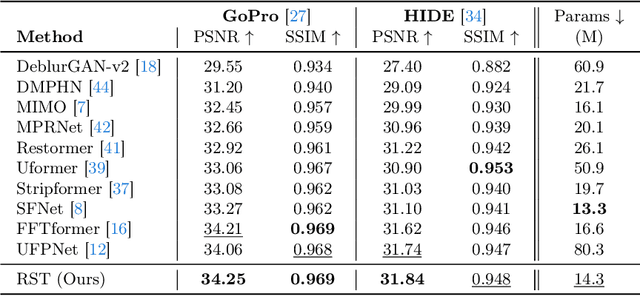
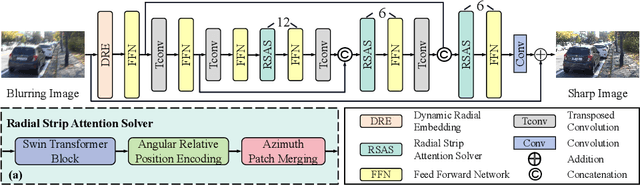
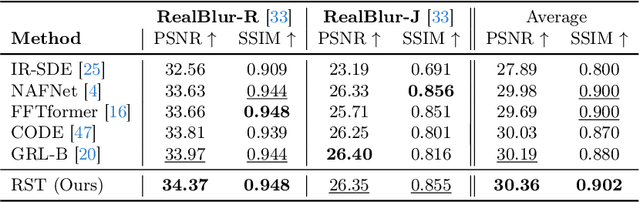
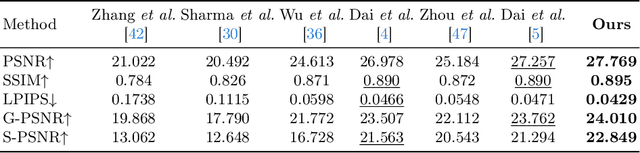
Exploring motion information is important for the motion deblurring task. Recent the window-based transformer approaches have achieved decent performance in image deblurring. Note that the motion causing blurry results is usually composed of translation and rotation movements and the window-shift operation in the Cartesian coordinate system by the window-based transformer approaches only directly explores translation motion in orthogonal directions. Thus, these methods have the limitation of modeling the rotation part. To alleviate this problem, we introduce the polar coordinate-based transformer, which has the angles and distance to explore rotation motion and translation information together. In this paper, we propose a Radial Strip Transformer (RST), which is a transformer-based architecture that restores the blur images in a polar coordinate system instead of a Cartesian one. RST contains a dynamic radial embedding module (DRE) to extract the shallow feature by a radial deformable convolution. We design a polar mask layer to generate the offsets for the deformable convolution, which can reshape the convolution kernel along the radius to better capture the rotation motion information. Furthermore, we proposed a radial strip attention solver (RSAS) as deep feature extraction, where the relationship of windows is organized by azimuth and radius. This attention module contains radial strip windows to reweight image features in the polar coordinate, which preserves more useful information in rotation and translation motion together for better recovering the sharp images. Experimental results on six synthesis and real-world datasets prove that our method performs favorably against other SOTA methods for the image deblurring task.
Look-Around Before You Leap: High-Frequency Injected Transformer for Image Restoration
Mar 30, 2024
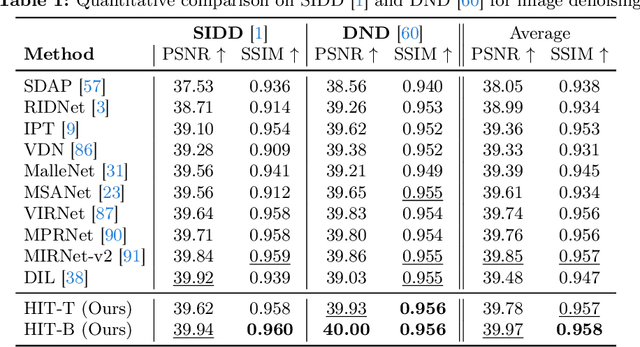
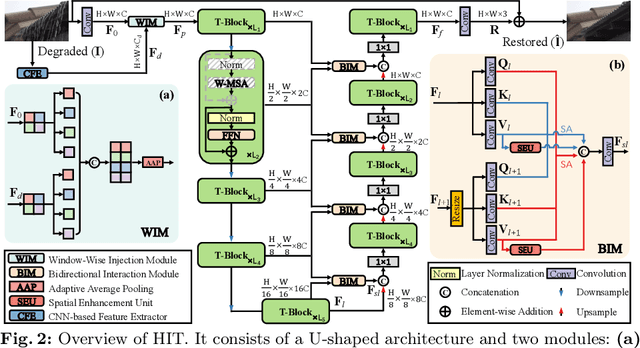
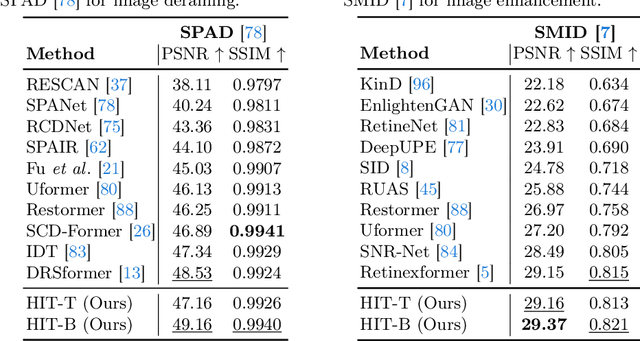
Transformer-based approaches have achieved superior performance in image restoration, since they can model long-term dependencies well. However, the limitation in capturing local information restricts their capacity to remove degradations. While existing approaches attempt to mitigate this issue by incorporating convolutional operations, the core component in Transformer, i.e., self-attention, which serves as a low-pass filter, could unintentionally dilute or even eliminate the acquired local patterns. In this paper, we propose HIT, a simple yet effective High-frequency Injected Transformer for image restoration. Specifically, we design a window-wise injection module (WIM), which incorporates abundant high-frequency details into the feature map, to provide reliable references for restoring high-quality images. We also develop a bidirectional interaction module (BIM) to aggregate features at different scales using a mutually reinforced paradigm, resulting in spatially and contextually improved representations. In addition, we introduce a spatial enhancement unit (SEU) to preserve essential spatial relationships that may be lost due to the computations carried out across channel dimensions in the BIM. Extensive experiments on 9 tasks (real noise, real rain streak, raindrop, motion blur, moir\'e, shadow, snow, haze, and low-light condition) demonstrate that HIT with linear computational complexity performs favorably against the state-of-the-art methods. The source code and pre-trained models will be available at https://github.com/joshyZhou/HIT.
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024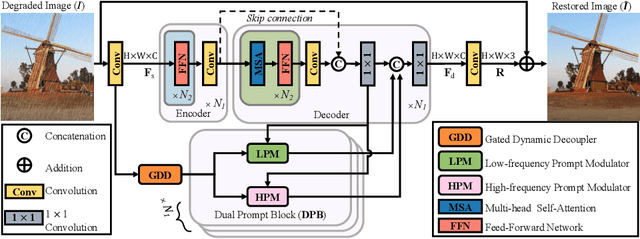
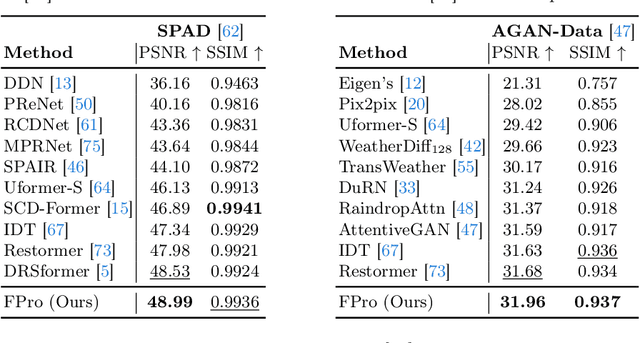
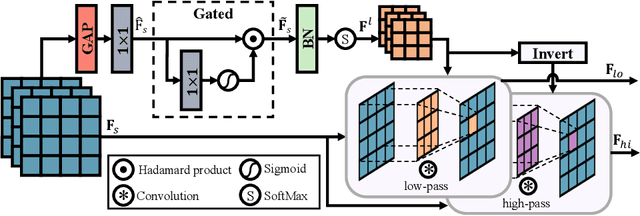
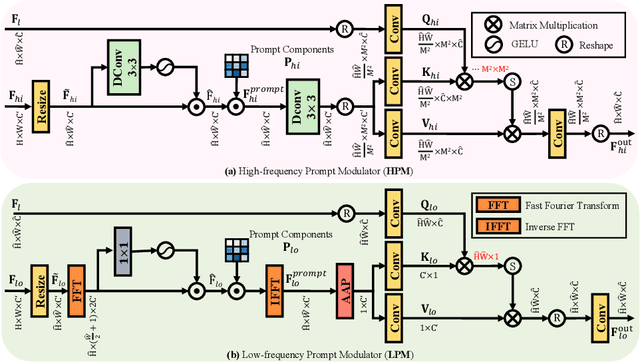
How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.