 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpread Your Wings: A Radial Strip Transformer for Image Deblurring
Mar 30, 2024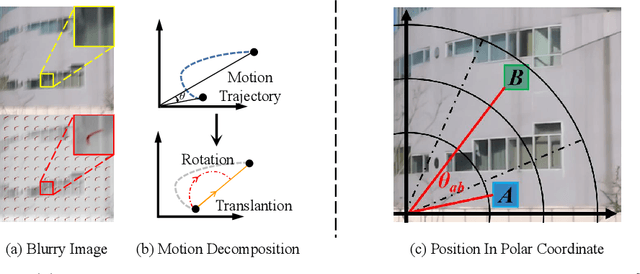
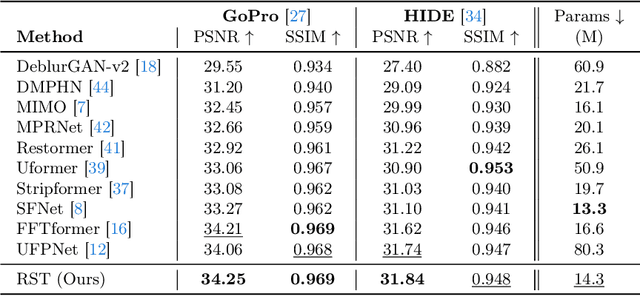
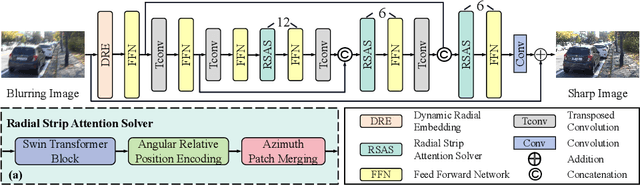
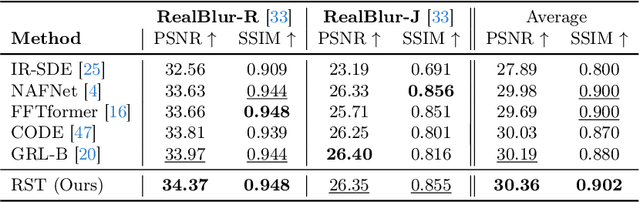
Exploring motion information is important for the motion deblurring task. Recent the window-based transformer approaches have achieved decent performance in image deblurring. Note that the motion causing blurry results is usually composed of translation and rotation movements and the window-shift operation in the Cartesian coordinate system by the window-based transformer approaches only directly explores translation motion in orthogonal directions. Thus, these methods have the limitation of modeling the rotation part. To alleviate this problem, we introduce the polar coordinate-based transformer, which has the angles and distance to explore rotation motion and translation information together. In this paper, we propose a Radial Strip Transformer (RST), which is a transformer-based architecture that restores the blur images in a polar coordinate system instead of a Cartesian one. RST contains a dynamic radial embedding module (DRE) to extract the shallow feature by a radial deformable convolution. We design a polar mask layer to generate the offsets for the deformable convolution, which can reshape the convolution kernel along the radius to better capture the rotation motion information. Furthermore, we proposed a radial strip attention solver (RSAS) as deep feature extraction, where the relationship of windows is organized by azimuth and radius. This attention module contains radial strip windows to reweight image features in the polar coordinate, which preserves more useful information in rotation and translation motion together for better recovering the sharp images. Experimental results on six synthesis and real-world datasets prove that our method performs favorably against other SOTA methods for the image deblurring task.
Look-Around Before You Leap: High-Frequency Injected Transformer for Image Restoration
Mar 30, 2024
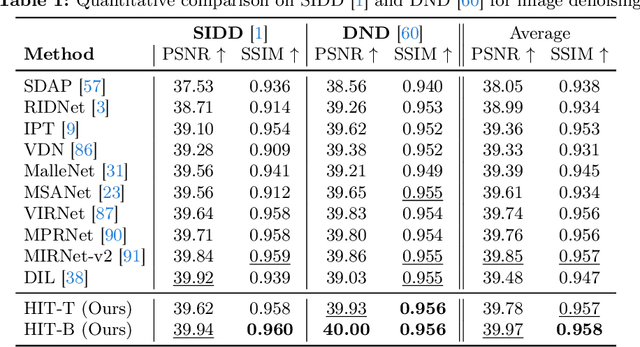
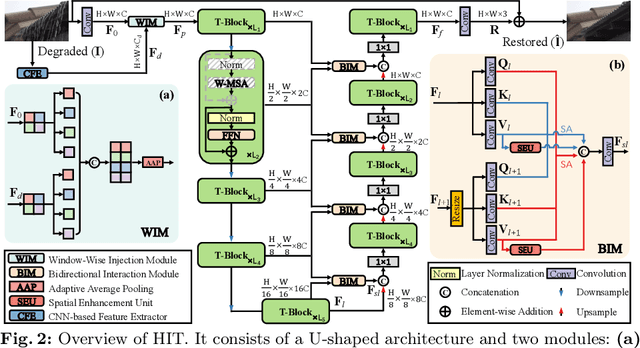
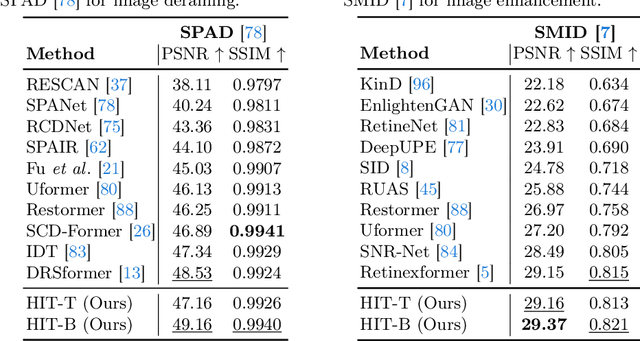
Transformer-based approaches have achieved superior performance in image restoration, since they can model long-term dependencies well. However, the limitation in capturing local information restricts their capacity to remove degradations. While existing approaches attempt to mitigate this issue by incorporating convolutional operations, the core component in Transformer, i.e., self-attention, which serves as a low-pass filter, could unintentionally dilute or even eliminate the acquired local patterns. In this paper, we propose HIT, a simple yet effective High-frequency Injected Transformer for image restoration. Specifically, we design a window-wise injection module (WIM), which incorporates abundant high-frequency details into the feature map, to provide reliable references for restoring high-quality images. We also develop a bidirectional interaction module (BIM) to aggregate features at different scales using a mutually reinforced paradigm, resulting in spatially and contextually improved representations. In addition, we introduce a spatial enhancement unit (SEU) to preserve essential spatial relationships that may be lost due to the computations carried out across channel dimensions in the BIM. Extensive experiments on 9 tasks (real noise, real rain streak, raindrop, motion blur, moir\'e, shadow, snow, haze, and low-light condition) demonstrate that HIT with linear computational complexity performs favorably against the state-of-the-art methods. The source code and pre-trained models will be available at https://github.com/joshyZhou/HIT.
Harmonizing Light and Darkness: A Symphony of Prior-guided Data Synthesis and Adaptive Focus for Nighttime Flare Removal
Mar 30, 2024
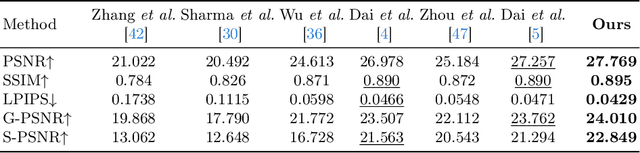


Intense light sources often produce flares in captured images at night, which deteriorates the visual quality and negatively affects downstream applications. In order to train an effective flare removal network, a reliable dataset is essential. The mainstream flare removal datasets are semi-synthetic to reduce human labour, but these datasets do not cover typical scenarios involving multiple scattering flares. To tackle this issue, we synthesize a prior-guided dataset named Flare7K*, which contains multi-flare images where the brightness of flares adheres to the laws of illumination. Besides, flares tend to occupy localized regions of the image but existing networks perform flare removal on the entire image and sometimes modify clean areas incorrectly. Therefore, we propose a plug-and-play Adaptive Focus Module (AFM) that can adaptively mask the clean background areas and assist models in focusing on the regions severely affected by flares. Extensive experiments demonstrate that our data synthesis method can better simulate real-world scenes and several models equipped with AFM achieve state-of-the-art performance on the real-world test dataset.
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024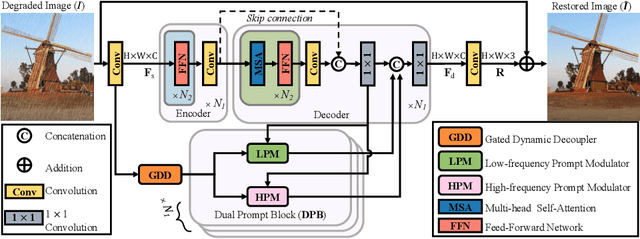
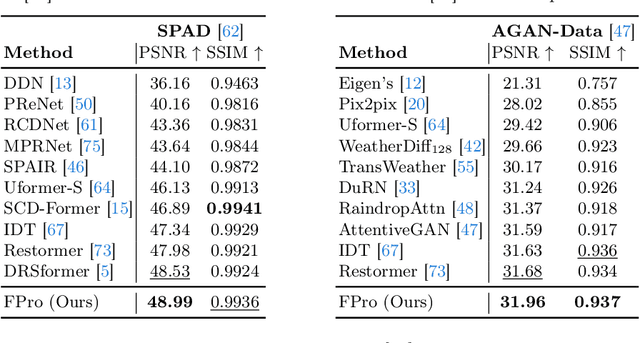
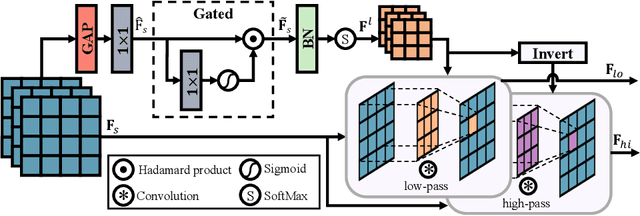
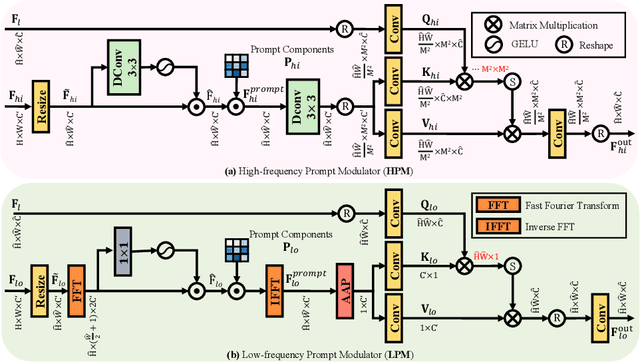
How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.