 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSTFormer: Hierarchical Spatial-Temporal Transformers for 3D Human Pose Estimation
Paper and Code
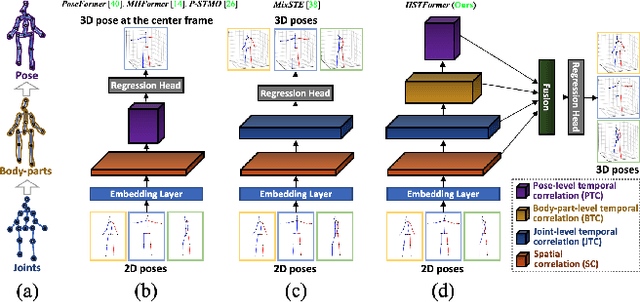
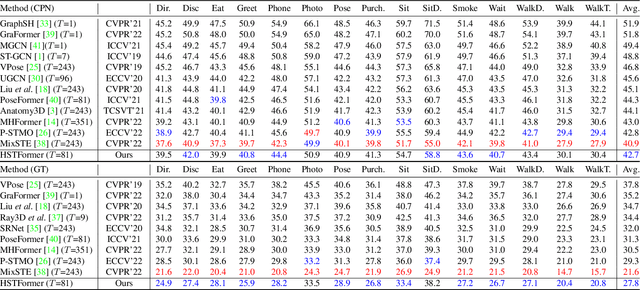
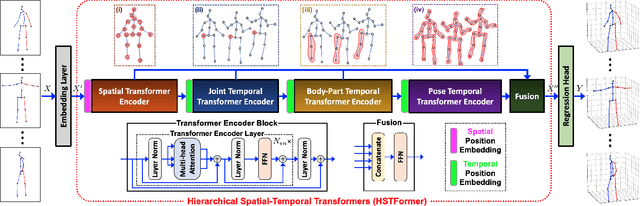
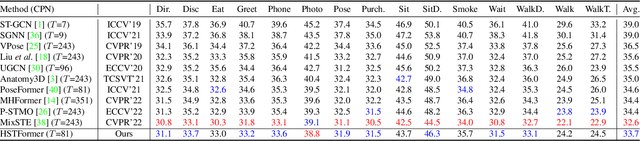
Transformer-based approaches have been successfully proposed for 3D human pose estimation (HPE) from 2D pose sequence and achieved state-of-the-art (SOTA) performance. However, current SOTAs have difficulties in modeling spatial-temporal correlations of joints at different levels simultaneously. This is due to the poses' spatial-temporal complexity. Poses move at various speeds temporarily with various joints and body-parts movement spatially. Hence, a cookie-cutter transformer is non-adaptable and can hardly meet the "in-the-wild" requirement. To mitigate this issue, we propose Hierarchical Spatial-Temporal transFormers (HSTFormer) to capture multi-level joints' spatial-temporal correlations from local to global gradually for accurate 3D HPE. HSTFormer consists of four transformer encoders (TEs) and a fusion module. To the best of our knowledge, HSTFormer is the first to study hierarchical TEs with multi-level fusion. Extensive experiments on three datasets (i.e., Human3.6M, MPI-INF-3DHP, and HumanEva) demonstrate that HSTFormer achieves competitive and consistent performance on benchmarks with various scales and difficulties. Specifically, it surpasses recent SOTAs on the challenging MPI-INF-3DHP dataset and small-scale HumanEva dataset, with a highly generalized systematic approach. The code is available at: https://github.com/qianxiaoye825/HSTFormer.