 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Learning-based Model for Cardiac Image Reconstruction: Summary of the CMRxRecon2024 Challenge
Mar 05, 2025Cardiovascular magnetic resonance (CMR) offers diverse imaging contrasts for assessment of cardiac function and tissue characterization. However, acquiring each single CMR modality is often time-consuming, and comprehensive clinical protocols require multiple modalities with various sampling patterns, further extending the overall acquisition time and increasing susceptibility to motion artifacts. Existing deep learning-based reconstruction methods are often designed for specific acquisition parameters, which limits their ability to generalize across a variety of scan scenarios. As part of the CMRxRecon Series, the CMRxRecon2024 challenge provides diverse datasets encompassing multi-modality multi-view imaging with various sampling patterns, and a platform for the international community to develop and benchmark reconstruction solutions in two well-crafted tasks. Task 1 is a modality-universal setting, evaluating the out-of-distribution generalization of the reconstructed model, while Task 2 follows sampling-universal setting assessing the one-for-all adaptability of the universal model. Main contributions include providing the first and largest publicly available multi-modality, multi-view cardiac k-space dataset; developing a benchmarking platform that simulates clinical acceleration protocols, with a shared code library and tutorial for various k-t undersampling patterns and data processing; giving technical insights of enhanced data consistency based on physic-informed networks and adaptive prompt-learning embedding to be versatile to different clinical settings; additional finding on evaluation metrics to address the limitations of conventional ground-truth references in universal reconstruction tasks.
PieTrack: An MOT solution based on synthetic data training and self-supervised domain adaptation
Jul 22, 2022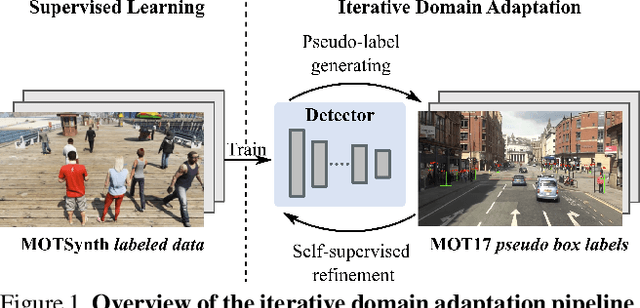
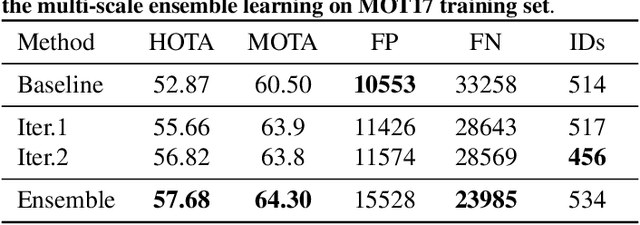
In order to cope with the increasing demand for labeling data and privacy issues with human detection, synthetic data has been used as a substitute and showing promising results in human detection and tracking tasks. We participate in the 7th Workshop on Benchmarking Multi-Target Tracking (BMTT), themed on "How Far Can Synthetic Data Take us"? Our solution, PieTrack, is developed based on synthetic data without using any pre-trained weights. We propose a self-supervised domain adaptation method that enables mitigating the domain shift issue between the synthetic (e.g., MOTSynth) and real data (e.g., MOT17) without involving extra human labels. By leveraging the proposed multi-scale ensemble inference, we achieved a final HOTA score of 58.7 on the MOT17 testing set, ranked third place in the challenge.