 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZALM3: Zero-Shot Enhancement of Vision-Language Alignment via In-Context Information in Multi-Turn Multimodal Medical Dialogue
Sep 26, 2024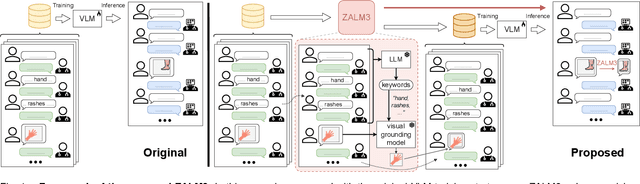
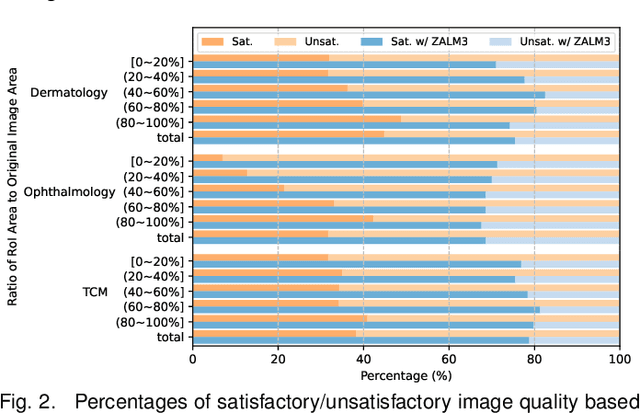
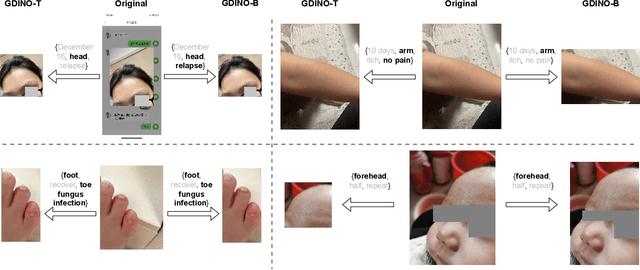
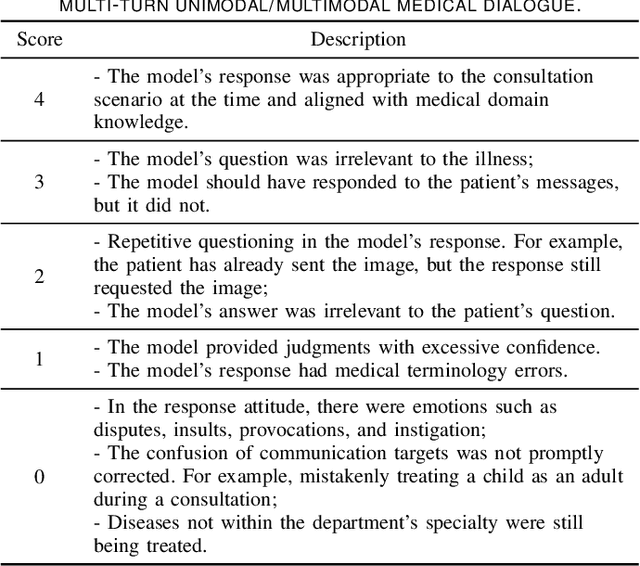
The rocketing prosperity of large language models (LLMs) in recent years has boosted the prevalence of vision-language models (VLMs) in the medical sector. In our online medical consultation scenario, a doctor responds to the texts and images provided by a patient in multiple rounds to diagnose her/his health condition, forming a multi-turn multimodal medical dialogue format. Unlike high-quality images captured by professional equipment in traditional medical visual question answering (Med-VQA), the images in our case are taken by patients' mobile phones. These images have poor quality control, with issues such as excessive background elements and the lesion area being significantly off-center, leading to degradation of vision-language alignment in the model training phase. In this paper, we propose ZALM3, a Zero-shot strategy to improve vision-language ALignment in Multi-turn Multimodal Medical dialogue. Since we observe that the preceding text conversations before an image can infer the regions of interest (RoIs) in the image, ZALM3 employs an LLM to summarize the keywords from the preceding context and a visual grounding model to extract the RoIs. The updated images eliminate unnecessary background noise and provide more effective vision-language alignment. To better evaluate our proposed method, we design a new subjective assessment metric for multi-turn unimodal/multimodal medical dialogue to provide a fine-grained performance comparison. Our experiments across three different clinical departments remarkably demonstrate the efficacy of ZALM3 with statistical significance.
SAGE-NDVI: A Stereotype-Breaking Evaluation Metric for Remote Sensing Image Dehazing Using Satellite-to-Ground NDVI Knowledge
Jun 09, 2023Image dehazing is a meaningful low-level computer vision task and can be applied to a variety of contexts. In our industrial deployment scenario based on remote sensing (RS) images, the quality of image dehazing directly affects the grade of our crop identification and growth monitoring products. However, the widely used peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) provide ambiguous visual interpretation. In this paper, we design a new objective metric for RS image dehazing evaluation. Our proposed metric leverages a ground-based phenology observation resource to calculate the vegetation index error between RS and ground images at a hazy date. Extensive experiments validate that our metric appropriately evaluates different dehazing models and is in line with human visual perception.
Agriculture-Vision Challenge 2022 -- The Runner-Up Solution for Agricultural Pattern Recognition via Transformer-based Models
Jun 23, 2022
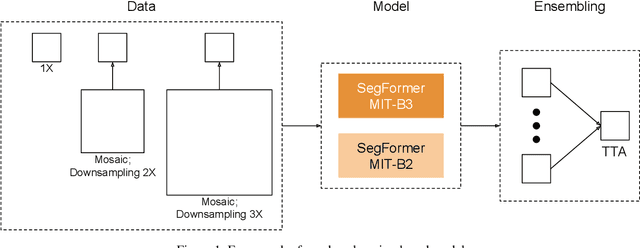
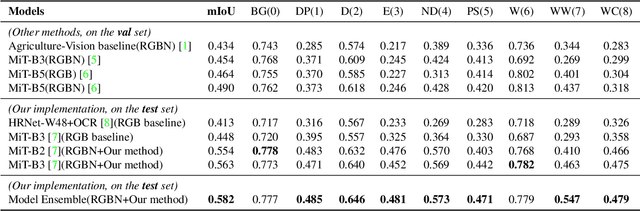
The Agriculture-Vision Challenge in CVPR is one of the most famous and competitive challenges for global researchers to break the boundary between computer vision and agriculture sectors, aiming at agricultural pattern recognition from aerial images. In this paper, we propose our solution to the third Agriculture-Vision Challenge in CVPR 2022. We leverage a data pre-processing scheme and several Transformer-based models as well as data augmentation techniques to achieve a mIoU of 0.582, accomplishing the 2nd place in this challenge.
MultiEarth 2022 -- The Champion Solution for the Matrix Completion Challenge via Multimodal Regression and Generation
Jun 17, 2022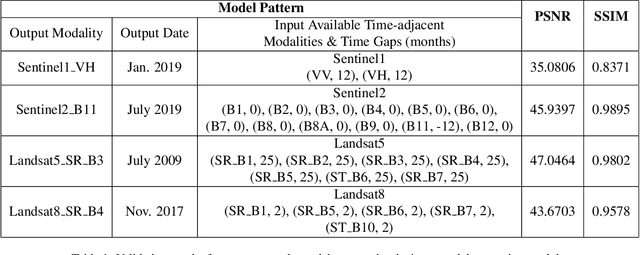


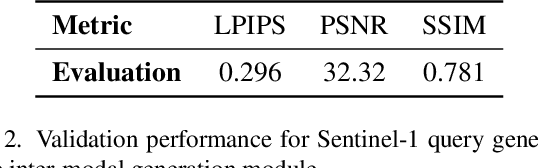
Earth observation satellites have been continuously monitoring the earth environment for years at different locations and spectral bands with different modalities. Due to complex satellite sensing conditions (e.g., weather, cloud, atmosphere, orbit), some observations for certain modalities, bands, locations, and times may not be available. The MultiEarth Matrix Completion Challenge in CVPR 2022 [1] provides the multimodal satellite data for addressing such data sparsity challenges with the Amazon Rainforest as the region of interest. This work proposes an adaptive real-time multimodal regression and generation framework and achieves superior performance on unseen test queries in this challenge with an LPIPS of 0.2226, a PSNR of 123.0372, and an SSIM of 0.6347.
Theme-Matters: Fashion Compatibility Learning via Theme Attention
Dec 26, 2019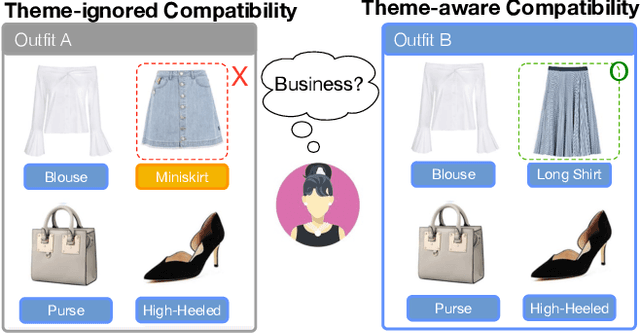
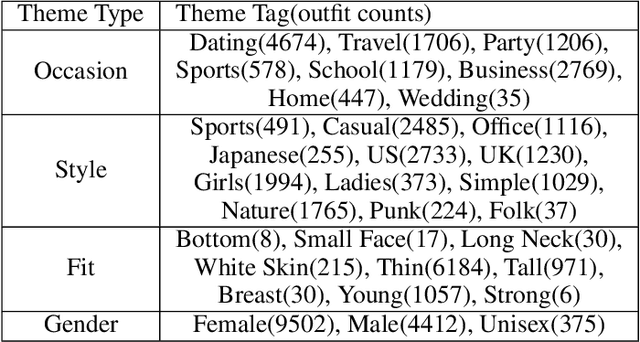
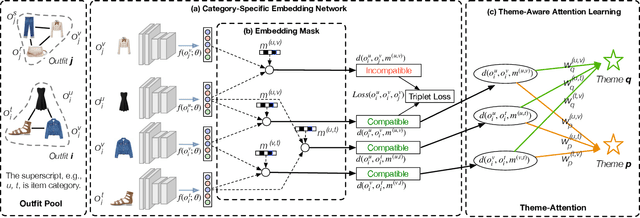
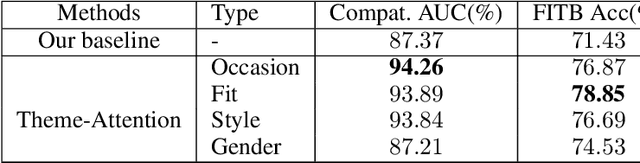
Fashion compatibility learning is important to many fashion markets such as outfit composition and online fashion recommendation. Unlike previous work, we argue that fashion compatibility is not only a visual appearance compatible problem but also a theme-matters problem. An outfit, which consists of a set of fashion items (e.g., shirt, suit, shoes, etc.), is considered to be compatible for a "dating" event, yet maybe not for a "business" occasion. In this paper, we aim at solving the fashion compatibility problem given specific themes. To this end, we built the first real-world theme-aware fashion dataset comprising 14K around outfits labeled with 32 themes. In this dataset, there are more than 40K fashion items labeled with 152 fine-grained categories. We also propose an attention model learning fashion compatibility given a specific theme. It starts with a category-specific subspace learning, which projects compatible outfit items in certain categories to be close in the subspace. Thanks to strong connections between fashion themes and categories, we then build a theme-attention model over the category-specific embedding space. This model associates themes with the pairwise compatibility with attention, and thus compute the outfit-wise compatibility. To the best of our knowledge, this is the first attempt to estimate outfit compatibility conditional on a theme. We conduct extensive qualitative and quantitative experiments on our new dataset. Our method outperforms the state-of-the-art approaches.
NISP: Pruning Networks using Neuron Importance Score Propagation
Mar 21, 2018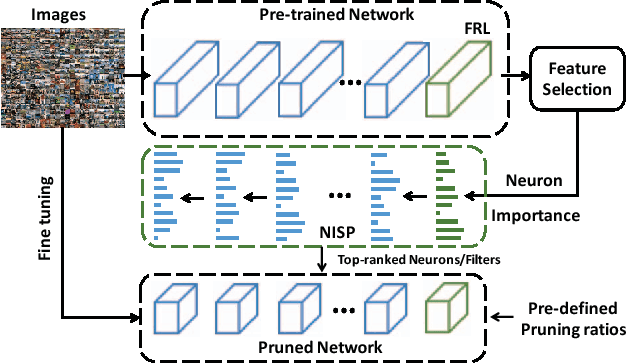

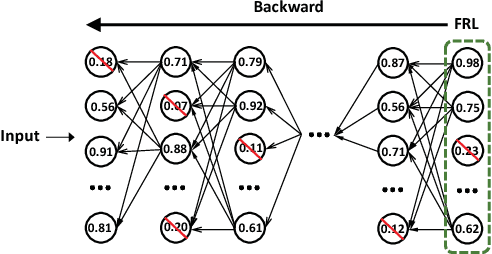
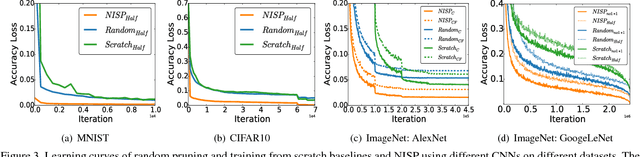
To reduce the significant redundancy in deep Convolutional Neural Networks (CNNs), most existing methods prune neurons by only considering statistics of an individual layer or two consecutive layers (e.g., prune one layer to minimize the reconstruction error of the next layer), ignoring the effect of error propagation in deep networks. In contrast, we argue that it is essential to prune neurons in the entire neuron network jointly based on a unified goal: minimizing the reconstruction error of important responses in the "final response layer" (FRL), which is the second-to-last layer before classification, for a pruned network to retrain its predictive power. Specifically, we apply feature ranking techniques to measure the importance of each neuron in the FRL, and formulate network pruning as a binary integer optimization problem and derive a closed-form solution to it for pruning neurons in earlier layers. Based on our theoretical analysis, we propose the Neuron Importance Score Propagation (NISP) algorithm to propagate the importance scores of final responses to every neuron in the network. The CNN is pruned by removing neurons with least importance, and then fine-tuned to retain its predictive power. NISP is evaluated on several datasets with multiple CNN models and demonstrated to achieve significant acceleration and compression with negligible accuracy loss.