 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiEarth 2022 -- The Champion Solution for the Matrix Completion Challenge via Multimodal Regression and Generation
Jun 17, 2022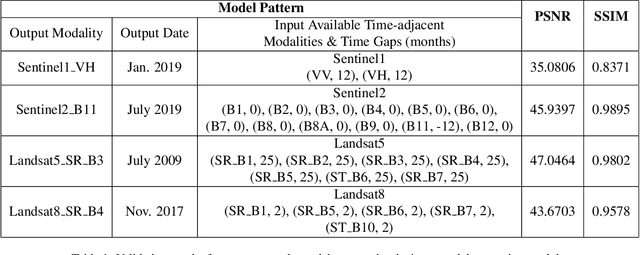


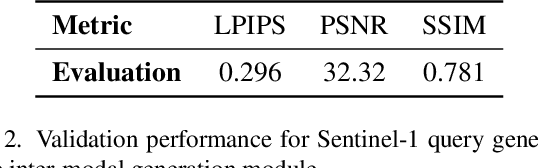
Earth observation satellites have been continuously monitoring the earth environment for years at different locations and spectral bands with different modalities. Due to complex satellite sensing conditions (e.g., weather, cloud, atmosphere, orbit), some observations for certain modalities, bands, locations, and times may not be available. The MultiEarth Matrix Completion Challenge in CVPR 2022 [1] provides the multimodal satellite data for addressing such data sparsity challenges with the Amazon Rainforest as the region of interest. This work proposes an adaptive real-time multimodal regression and generation framework and achieves superior performance on unseen test queries in this challenge with an LPIPS of 0.2226, a PSNR of 123.0372, and an SSIM of 0.6347.
SegAttnGAN: Text to Image Generation with Segmentation Attention
May 25, 2020
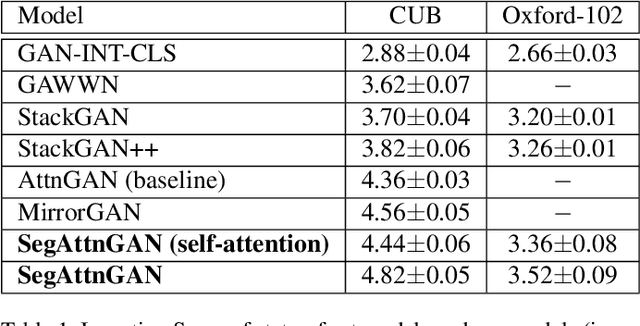
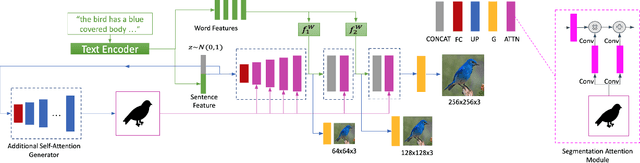

In this paper, we propose a novel generative network (SegAttnGAN) that utilizes additional segmentation information for the text-to-image synthesis task. As the segmentation data introduced to the model provides useful guidance on the generator training, the proposed model can generate images with better realism quality and higher quantitative measures compared with the previous state-of-art methods. We achieved Inception Score of 4.84 on the CUB dataset and 3.52 on the Oxford-102 dataset. Besides, we tested the self-attention SegAttnGAN which uses generated segmentation data instead of masks from datasets for attention and achieved similar high-quality results, suggesting that our model can be adapted for the text-to-image synthesis task.
Optimal Transport Based Generative Autoencoders
Oct 16, 2019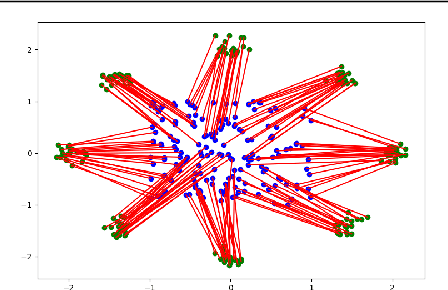
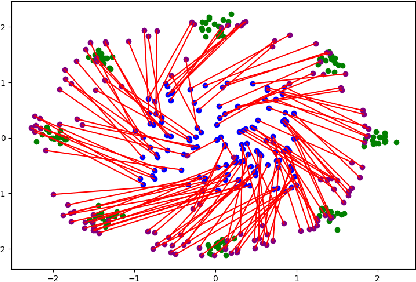
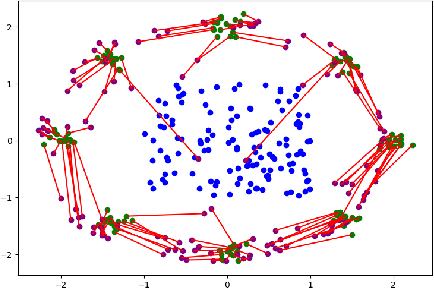

The field of deep generative modeling is dominated by generative adversarial networks (GANs). However, the training of GANs often lacks stability, fails to converge, and suffers from model collapse. It takes an assortment of tricks to solve these problems, which may be difficult to understand for those seeking to apply generative modeling. Instead, we propose two novel generative autoencoders, AE-OTtrans and AE-OTgen, which rely on optimal transport instead of adversarial training. AE-OTtrans and AEOTgen, unlike VAE and WAE, preserve the manifold of the data; they do not force the latent distribution to match a normal distribution, resulting in greater quality images. AEOTtrans and AE-OTgen also produce images of higher diversity compared to their predecessor, AE-OT. We show that AE-OTtrans and AE-OTgen surpass GANs in the MNIST and FashionMNIST datasets. Furthermore, We show that AE-OTtrans and AE-OTgen do state of the art on the MNIST, FashionMNIST, and CelebA image sets comapred to other non-adversarial generative models.