 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Point Cloud Completion based on Multi-View Augmentations of Single Partial Point Cloud
Sep 26, 2025Point cloud completion aims to reconstruct complete shapes from partial observations. Although current methods have achieved remarkable performance, they still have some limitations: Supervised methods heavily rely on ground truth, which limits their generalization to real-world datasets due to the synthetic-to-real domain gap. Unsupervised methods require complete point clouds to compose unpaired training data, and weakly-supervised methods need multi-view observations of the object. Existing self-supervised methods frequently produce unsatisfactory predictions due to the limited capabilities of their self-supervised signals. To overcome these challenges, we propose a novel self-supervised point cloud completion method. We design a set of novel self-supervised signals based on multi-view augmentations of the single partial point cloud. Additionally, to enhance the model's learning ability, we first incorporate Mamba into self-supervised point cloud completion task, encouraging the model to generate point clouds with better quality. Experiments on synthetic and real-world datasets demonstrate that our method achieves state-of-the-art results.
SAMv2: A Unified Framework for Learning Appearance, Semantic and Cross-Modality Anatomical Embeddings
Nov 28, 2023



Identifying anatomical structures (e.g., lesions or landmarks) in medical images plays a fundamental role in medical image analysis. As an exemplar-based landmark detection method, Self-supervised Anatomical eMbedding (SAM) learns a discriminative embedding for each voxel in the image and has shown promising results on various tasks. However, SAM still faces challenges in: (1) differentiating voxels with similar appearance but different semantic meanings (\textit{e.g.}, two adjacent structures without clear borders); (2) matching voxels with similar semantics but markedly different appearance (e.g., the same vessel before and after contrast injection); and (3) cross-modality matching (e.g., CT-MRI registration). To overcome these challenges, we propose SAMv2, which is a unified framework designed to learn appearance, semantic, and cross-modality anatomical embeddings. Specifically, SAMv2 incorporates three key innovations: (1) semantic embedding learning with prototypical contrastive loss; (2) a fixed-point-based matching strategy; and (3) an iterative approach for cross-modality embedding learning. We thoroughly evaluated SAMv2 across three tasks, including one-shot landmark detection, lesion tracking on longitudinal CT scans, and CT-MRI affine/rigid registration with varying field of view. Our results suggest that SAMv2 outperforms SAM and other state-of-the-art methods, offering a robust and versatile approach for landmark based medical image analysis tasks. Code and trained models are available at: https://github.com/alibaba-damo-academy/self-supervised-anatomical-embedding-v2
Matching in the Wild: Learning Anatomical Embeddings for Multi-Modality Images
Jul 07, 2023



Radiotherapists require accurate registration of MR/CT images to effectively use information from both modalities. In a typical registration pipeline, rigid or affine transformations are applied to roughly align the fixed and moving images before proceeding with the deformation step. While recent learning-based methods have shown promising results in the rigid/affine step, these methods often require images with similar field-of-view (FOV) for successful alignment. As a result, aligning images with different FOVs remains a challenging task. Self-supervised landmark detection methods like self-supervised Anatomical eMbedding (SAM) have emerged as a useful tool for mapping and cropping images to similar FOVs. However, these methods are currently limited to intra-modality use only. To address this limitation and enable cross-modality matching, we propose a new approach called Cross-SAM. Our approach utilizes a novel iterative process that alternates between embedding learning and CT-MRI registration. We start by applying aggressive contrast augmentation on both CT and MRI images to train a SAM model. We then use this SAM to identify corresponding regions on paired images using robust grid-points matching, followed by a point-set based affine/rigid registration, and a deformable fine-tuning step to produce registered paired images. We use these registered pairs to enhance the matching ability of SAM, which is then processed iteratively. We use the final model for cross-modality matching tasks. We evaluated our approach on two CT-MRI affine registration datasets and found that Cross-SAM achieved robust affine registration on both datasets, significantly outperforming other methods and achieving state-of-the-art performance.
Lesion Segmentation and RECIST Diameter Prediction via Click-driven Attention and Dual-path Connection
May 05, 2021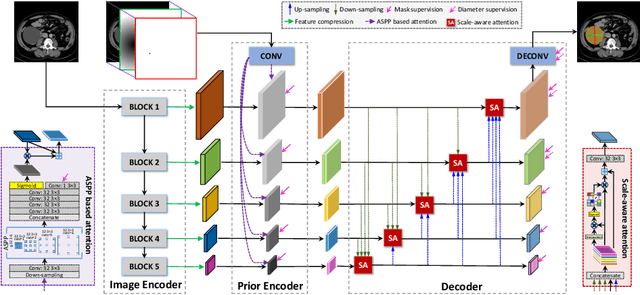
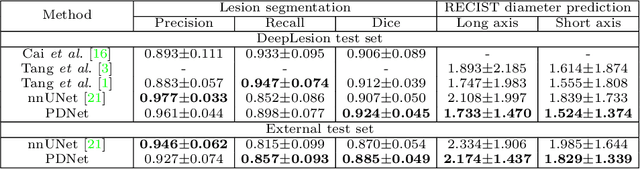
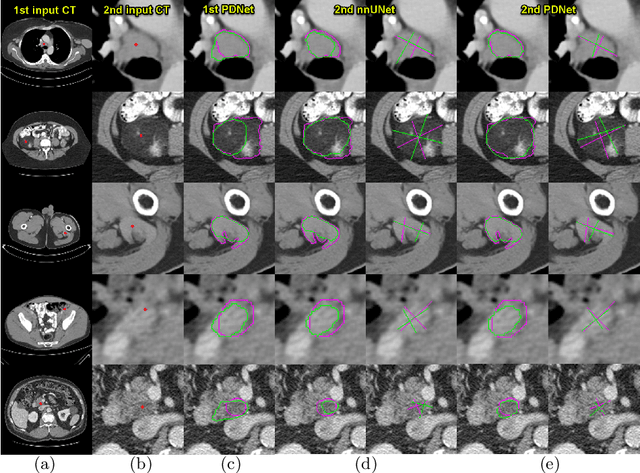
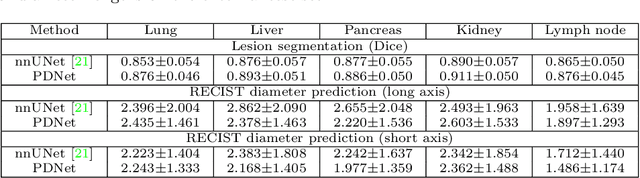
Measuring lesion size is an important step to assess tumor growth and monitor disease progression and therapy response in oncology image analysis. Although it is tedious and highly time-consuming, radiologists have to work on this task by using RECIST criteria (Response Evaluation Criteria In Solid Tumors) routinely and manually. Even though lesion segmentation may be the more accurate and clinically more valuable means, physicians can not manually segment lesions as now since much more heavy laboring will be required. In this paper, we present a prior-guided dual-path network (PDNet) to segment common types of lesions throughout the whole body and predict their RECIST diameters accurately and automatically. Similar to [1], a click guidance from radiologists is the only requirement. There are two key characteristics in PDNet: 1) Learning lesion-specific attention matrices in parallel from the click prior information by the proposed prior encoder, named click-driven attention; 2) Aggregating the extracted multi-scale features comprehensively by introducing top-down and bottom-up connections in the proposed decoder, named dual-path connection. Experiments show the superiority of our proposed PDNet in lesion segmentation and RECIST diameter prediction using the DeepLesion dataset and an external test set. PDNet learns comprehensive and representative deep image features for our tasks and produces more accurate results on both lesion segmentation and RECIST diameter prediction.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021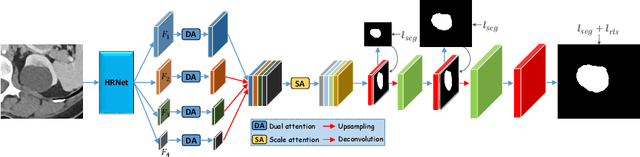
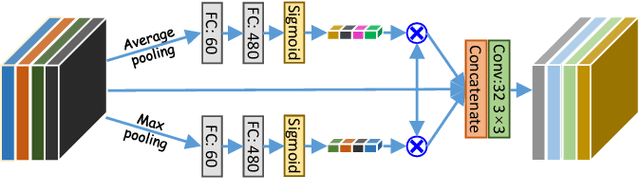
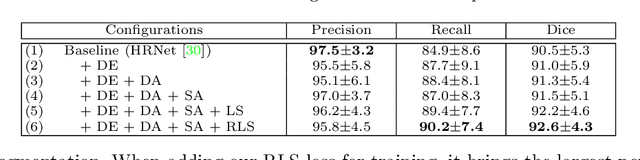
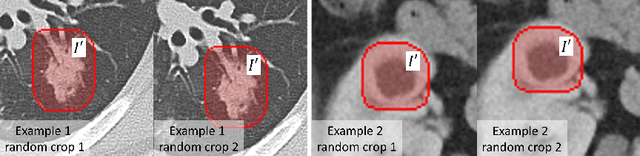
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.
Self-supervised Learning of Pixel-wise Anatomical Embeddings in Radiological Images
Dec 04, 2020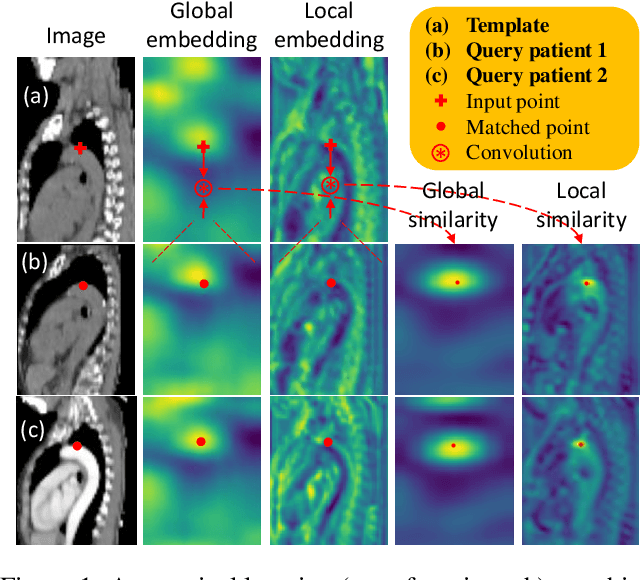
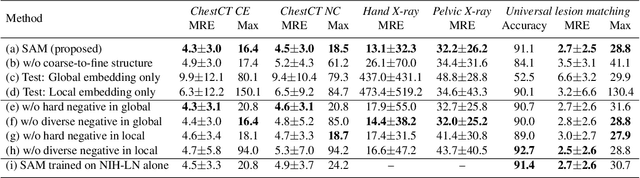
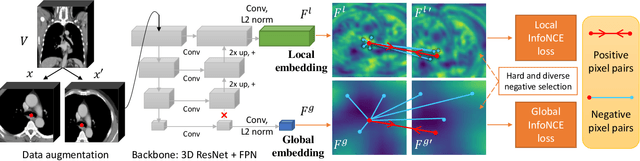
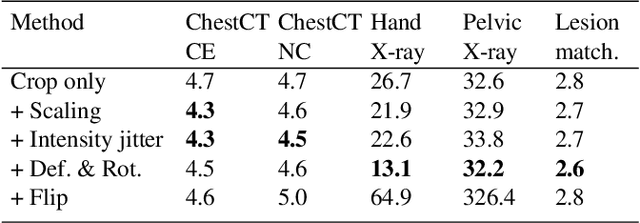
Radiological images such as computed tomography (CT) and X-rays render anatomy with intrinsic structures. Being able to reliably locate the same anatomical or semantic structure across varying images is a fundamental task in medical image analysis. In principle it is possible to use landmark detection or semantic segmentation for this task, but to work well these require large numbers of labeled data for each anatomical structure and sub-structure of interest. A more universal approach would discover the intrinsic structure from unlabeled images. We introduce such an approach, called Self-supervised Anatomical eMbedding (SAM). SAM generates semantic embeddings for each image pixel that describes its anatomical location or body part. To produce such embeddings, we propose a pixel-level contrastive learning framework. A coarse-to-fine strategy ensures both global and local anatomical information are encoded. Negative sample selection strategies are designed to enhance the discriminability among different body parts. Using SAM, one can label any point of interest on a template image, and then locate the same body part in other images by simple nearest neighbor searching. We demonstrate the effectiveness of SAM in multiple tasks with 2D and 3D image modalities. On a chest CT dataset with 19 landmarks, SAM outperforms widely-used registration algorithms while being 200 times faster. On two X-ray datasets, SAM, with only one labeled template image, outperforms supervised methods trained on 50 labeled images. We also apply SAM on whole-body follow-up lesion matching in CT and obtain an accuracy of 91%.
DuDoNet++: Encoding mask projection to reduce CT metal artifacts
Jan 18, 2020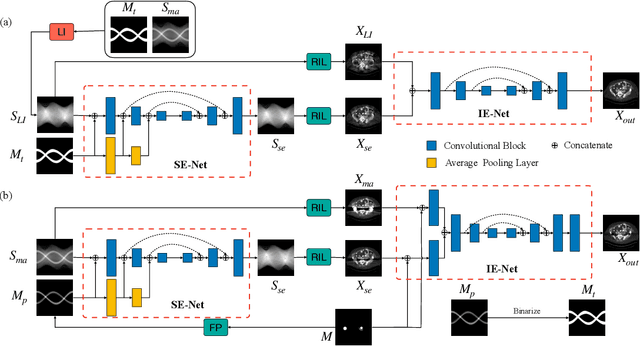

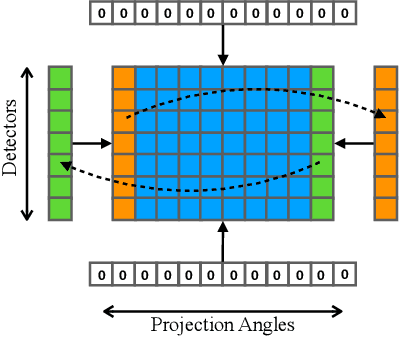

CT metal artifact reduction (MAR) is a notoriously challenging task because the artifacts are structured and non-local in the image domain. However, they are inherently local in the sinogram domain. DuDoNet is the state-of-the-art MAR algorithm which exploits the latter characteristic by learning to reduce artifacts in the sinogram and image domain jointly. By design, DuDoNet treats the metal-affected regions in sinogram as missing and replaces them with the surrogate data generated by a neural network. Since fine-grained details within the metal-affected regions are completely ignored, the artifact-reduced CT images by DuDoNet tend to be over-smoothed and distorted. In this work, we investigate the issue by theoretical derivation. We propose to address the problem by (1) retaining the metal-affected regions in sinogram and (2) replacing the binarized metal trace with the metal mask projection such that the geometry information of metal implants is encoded. Extensive experiments on simulated datasets and expert evaluations on clinical images demonstrate that our network called DuDoNet++ yields anatomically more precise artifact-reduced images than DuDoNet, especially when the metallic objects are large.