 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continual Learning-driven Model for Accurate and Generalizable Segmentation of Clinically Comprehensive and Fine-grained Whole-body Anatomies in CT
Mar 16, 2025Precision medicine in the quantitative management of chronic diseases and oncology would be greatly improved if the Computed Tomography (CT) scan of any patient could be segmented, parsed and analyzed in a precise and detailed way. However, there is no such fully annotated CT dataset with all anatomies delineated for training because of the exceptionally high manual cost, the need for specialized clinical expertise, and the time required to finish the task. To this end, we proposed a novel continual learning-driven CT model that can segment complete anatomies presented using dozens of previously partially labeled datasets, dynamically expanding its capacity to segment new ones without compromising previously learned organ knowledge. Existing multi-dataset approaches are not able to dynamically segment new anatomies without catastrophic forgetting and would encounter optimization difficulty or infeasibility when segmenting hundreds of anatomies across the whole range of body regions. Our single unified CT segmentation model, CL-Net, can highly accurately segment a clinically comprehensive set of 235 fine-grained whole-body anatomies. Composed of a universal encoder, multiple optimized and pruned decoders, CL-Net is developed using 13,952 CT scans from 20 public and 16 private high-quality partially labeled CT datasets of various vendors, different contrast phases, and pathologies. Extensive evaluation demonstrates that CL-Net consistently outperforms the upper limit of an ensemble of 36 specialist nnUNets trained per dataset with the complexity of 5% model size and significantly surpasses the segmentation accuracy of recent leading Segment Anything-style medical image foundation models by large margins. Our continual learning-driven CL-Net model would lay a solid foundation to facilitate many downstream tasks of oncology and chronic diseases using the most widely adopted CT imaging.
Leveraging Semantic Asymmetry for Precise Gross Tumor Volume Segmentation of Nasopharyngeal Carcinoma in Planning CT
Nov 27, 2024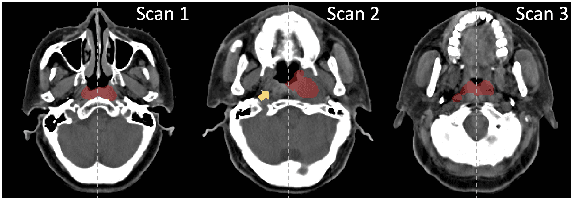
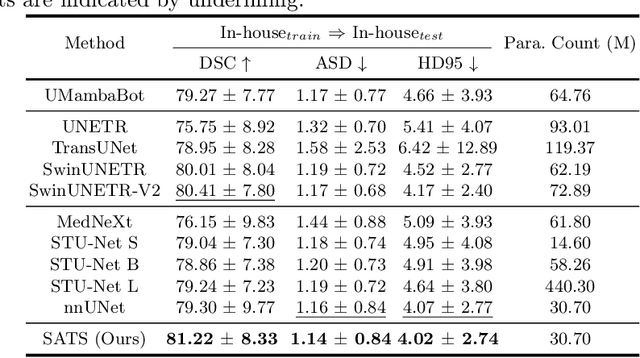
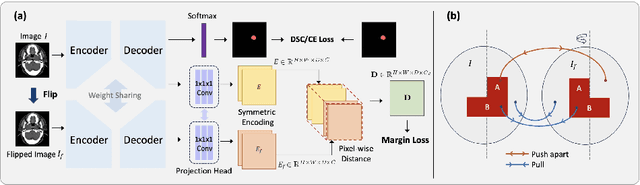
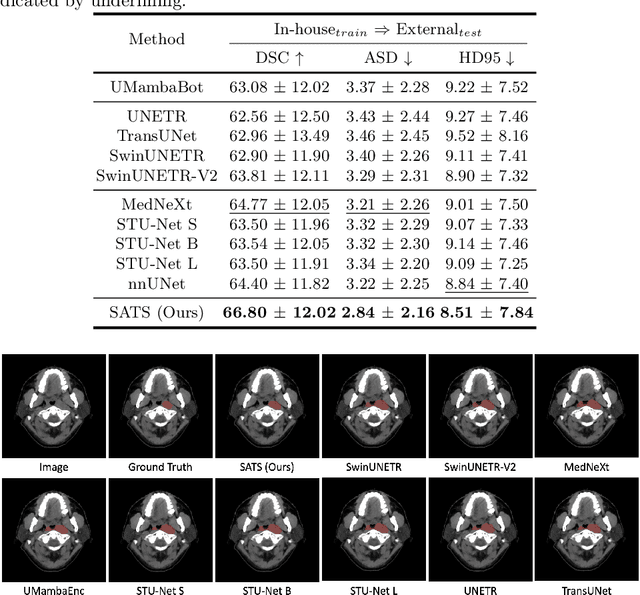
In the radiation therapy of nasopharyngeal carcinoma (NPC), clinicians typically delineate the gross tumor volume (GTV) using non-contrast planning computed tomography to ensure accurate radiation dose delivery. However, the low contrast between tumors and adjacent normal tissues necessitates that radiation oncologists manually delineate the tumors, often relying on diagnostic MRI for guidance. % In this study, we propose a novel approach to directly segment NPC gross tumors on non-contrast planning CT images, circumventing potential registration errors when aligning MRI or MRI-derived tumor masks to planning CT. To address the low contrast issues between tumors and adjacent normal structures in planning CT, we introduce a 3D Semantic Asymmetry Tumor segmentation (SATs) method. Specifically, we posit that a healthy nasopharyngeal region is characteristically bilaterally symmetric, whereas the emergence of nasopharyngeal carcinoma disrupts this symmetry. Then, we propose a Siamese contrastive learning segmentation framework that minimizes the voxel-wise distance between original and flipped areas without tumor and encourages a larger distance between original and flipped areas with tumor. Thus, our approach enhances the sensitivity of features to semantic asymmetries. % Extensive experiments demonstrate that the proposed SATs achieves the leading NPC GTV segmentation performance in both internal and external testing, \emph{e.g.}, with at least 2\% absolute Dice score improvement and 12\% average distance error reduction when compared to other state-of-the-art methods in the external testing.
SAMv2: A Unified Framework for Learning Appearance, Semantic and Cross-Modality Anatomical Embeddings
Nov 28, 2023



Identifying anatomical structures (e.g., lesions or landmarks) in medical images plays a fundamental role in medical image analysis. As an exemplar-based landmark detection method, Self-supervised Anatomical eMbedding (SAM) learns a discriminative embedding for each voxel in the image and has shown promising results on various tasks. However, SAM still faces challenges in: (1) differentiating voxels with similar appearance but different semantic meanings (\textit{e.g.}, two adjacent structures without clear borders); (2) matching voxels with similar semantics but markedly different appearance (e.g., the same vessel before and after contrast injection); and (3) cross-modality matching (e.g., CT-MRI registration). To overcome these challenges, we propose SAMv2, which is a unified framework designed to learn appearance, semantic, and cross-modality anatomical embeddings. Specifically, SAMv2 incorporates three key innovations: (1) semantic embedding learning with prototypical contrastive loss; (2) a fixed-point-based matching strategy; and (3) an iterative approach for cross-modality embedding learning. We thoroughly evaluated SAMv2 across three tasks, including one-shot landmark detection, lesion tracking on longitudinal CT scans, and CT-MRI affine/rigid registration with varying field of view. Our results suggest that SAMv2 outperforms SAM and other state-of-the-art methods, offering a robust and versatile approach for landmark based medical image analysis tasks. Code and trained models are available at: https://github.com/alibaba-damo-academy/self-supervised-anatomical-embedding-v2
SAME++: A Self-supervised Anatomical eMbeddings Enhanced medical image registration framework using stable sampling and regularized transformation
Nov 25, 2023Image registration is a fundamental medical image analysis task. Ideally, registration should focus on aligning semantically corresponding voxels, i.e., the same anatomical locations. However, existing methods often optimize similarity measures computed directly on intensities or on hand-crafted features, which lack anatomical semantic information. These similarity measures may lead to sub-optimal solutions where large deformations, complex anatomical differences, or cross-modality imagery exist. In this work, we introduce a fast and accurate method for unsupervised 3D medical image registration building on top of a Self-supervised Anatomical eMbedding (SAM) algorithm, which is capable of computing dense anatomical correspondences between two images at the voxel level. We name our approach SAM-Enhanced registration (SAME++), which decomposes image registration into four steps: affine transformation, coarse deformation, deep non-parametric transformation, and instance optimization. Using SAM embeddings, we enhance these steps by finding more coherent correspondence and providing features with better semantic guidance. We extensively evaluated SAME++ using more than 50 labeled organs on three challenging inter-subject registration tasks of different body parts. As a complete registration framework, SAME++ markedly outperforms leading methods by $4.2\%$ - $8.2\%$ in terms of Dice score while being orders of magnitude faster than numerical optimization-based methods. Code is available at \url{https://github.com/alibaba-damo-academy/same}.
SAMConvex: Fast Discrete Optimization for CT Registration using Self-supervised Anatomical Embedding and Correlation Pyramid
Jul 19, 2023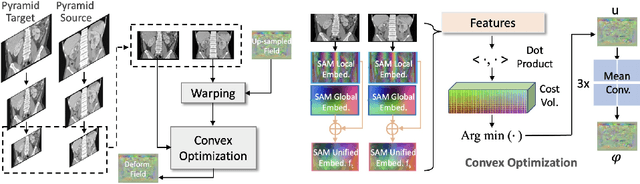
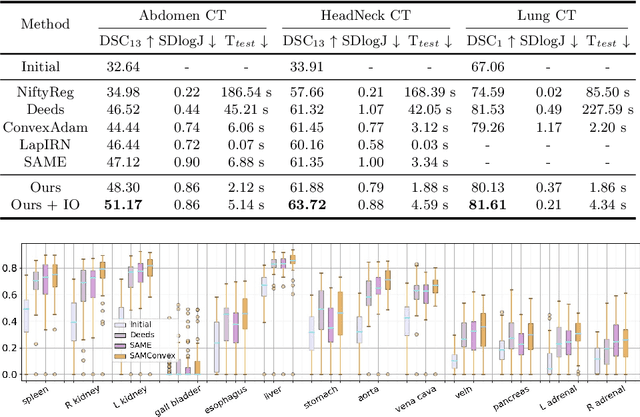
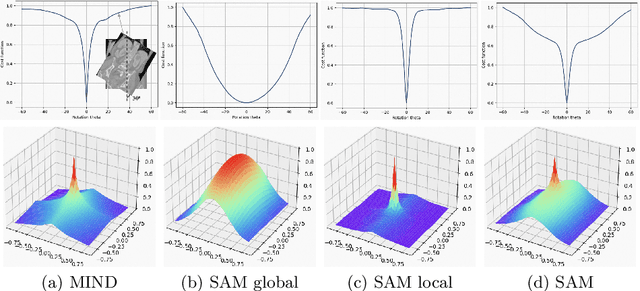

Estimating displacement vector field via a cost volume computed in the feature space has shown great success in image registration, but it suffers excessive computation burdens. Moreover, existing feature descriptors only extract local features incapable of representing the global semantic information, which is especially important for solving large transformations. To address the discussed issues, we propose SAMConvex, a fast coarse-to-fine discrete optimization method for CT registration that includes a decoupled convex optimization procedure to obtain deformation fields based on a self-supervised anatomical embedding (SAM) feature extractor that captures both local and global information. To be specific, SAMConvex extracts per-voxel features and builds 6D correlation volumes based on SAM features, and iteratively updates a flow field by performing lookups on the correlation volumes with a coarse-to-fine scheme. SAMConvex outperforms the state-of-the-art learning-based methods and optimization-based methods over two inter-patient registration datasets (Abdomen CT and HeadNeck CT) and one intra-patient registration dataset (Lung CT). Moreover, as an optimization-based method, SAMConvex only takes $\sim2$s ($\sim5s$ with instance optimization) for one paired images.
Matching in the Wild: Learning Anatomical Embeddings for Multi-Modality Images
Jul 07, 2023



Radiotherapists require accurate registration of MR/CT images to effectively use information from both modalities. In a typical registration pipeline, rigid or affine transformations are applied to roughly align the fixed and moving images before proceeding with the deformation step. While recent learning-based methods have shown promising results in the rigid/affine step, these methods often require images with similar field-of-view (FOV) for successful alignment. As a result, aligning images with different FOVs remains a challenging task. Self-supervised landmark detection methods like self-supervised Anatomical eMbedding (SAM) have emerged as a useful tool for mapping and cropping images to similar FOVs. However, these methods are currently limited to intra-modality use only. To address this limitation and enable cross-modality matching, we propose a new approach called Cross-SAM. Our approach utilizes a novel iterative process that alternates between embedding learning and CT-MRI registration. We start by applying aggressive contrast augmentation on both CT and MRI images to train a SAM model. We then use this SAM to identify corresponding regions on paired images using robust grid-points matching, followed by a point-set based affine/rigid registration, and a deformable fine-tuning step to produce registered paired images. We use these registered pairs to enhance the matching ability of SAM, which is then processed iteratively. We use the final model for cross-modality matching tasks. We evaluated our approach on two CT-MRI affine registration datasets and found that Cross-SAM achieved robust affine registration on both datasets, significantly outperforming other methods and achieving state-of-the-art performance.
Accurate Airway Tree Segmentation in CT Scans via Anatomy-aware Multi-class Segmentation and Topology-guided Iterative Learning
Jun 15, 2023



Intrathoracic airway segmentation in computed tomography (CT) is a prerequisite for various respiratory disease analyses such as chronic obstructive pulmonary disease (COPD), asthma and lung cancer. Unlike other organs with simpler shapes or topology, the airway's complex tree structure imposes an unbearable burden to generate the "ground truth" label (up to 7 or 3 hours of manual or semi-automatic annotation on each case). Most of the existing airway datasets are incompletely labeled/annotated, thus limiting the completeness of computer-segmented airway. In this paper, we propose a new anatomy-aware multi-class airway segmentation method enhanced by topology-guided iterative self-learning. Based on the natural airway anatomy, we formulate a simple yet highly effective anatomy-aware multi-class segmentation task to intuitively handle the severe intra-class imbalance of the airway. To solve the incomplete labeling issue, we propose a tailored self-iterative learning scheme to segment toward the complete airway tree. For generating pseudo-labels to achieve higher sensitivity , we introduce a novel breakage attention map and design a topology-guided pseudo-label refinement method by iteratively connecting breaking branches commonly existed from initial pseudo-labels. Extensive experiments have been conducted on four datasets including two public challenges. The proposed method ranked 1st in both EXACT'09 challenge using average score and ATM'22 challenge on weighted average score. In a public BAS dataset and a private lung cancer dataset, our method significantly improves previous leading approaches by extracting at least (absolute) 7.5% more detected tree length and 4.0% more tree branches, while maintaining similar precision.
Continual Segment: Towards a Single, Unified and Accessible Continual Segmentation Model of 143 Whole-body Organs in CT Scans
Feb 04, 2023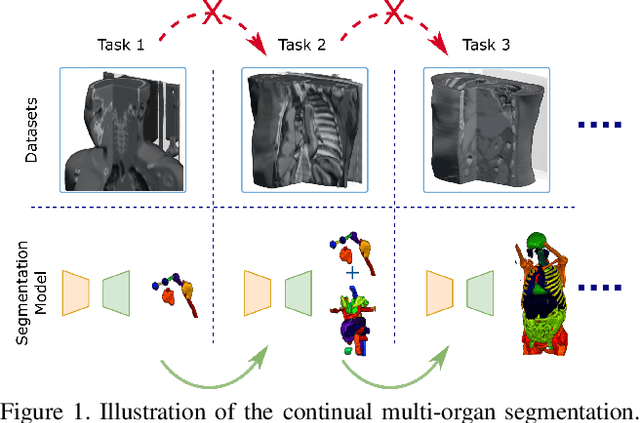
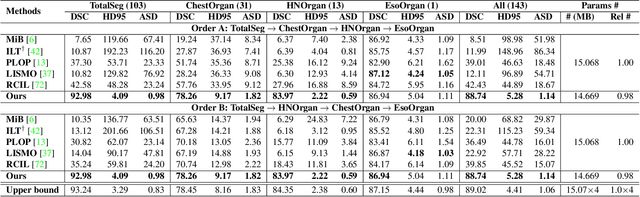
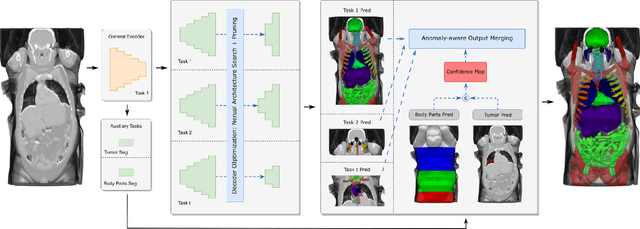
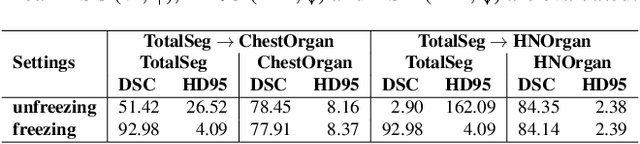
Deep learning empowers the mainstream medical image segmentation methods. Nevertheless current deep segmentation approaches are not capable of efficiently and effectively adapting and updating the trained models when new incremental segmentation classes (along with new training datasets or not) are required to be added. In real clinical environment, it can be preferred that segmentation models could be dynamically extended to segment new organs/tumors without the (re-)access to previous training datasets due to obstacles of patient privacy and data storage. This process can be viewed as a continual semantic segmentation (CSS) problem, being understudied for multi-organ segmentation. In this work, we propose a new architectural CSS learning framework to learn a single deep segmentation model for segmenting a total of 143 whole-body organs. Using the encoder/decoder network structure, we demonstrate that a continually-trained then frozen encoder coupled with incrementally-added decoders can extract and preserve sufficiently representative image features for new classes to be subsequently and validly segmented. To maintain a single network model complexity, we trim each decoder progressively using neural architecture search and teacher-student based knowledge distillation. To incorporate with both healthy and pathological organs appearing in different datasets, a novel anomaly-aware and confidence learning module is proposed to merge the overlapped organ predictions, originated from different decoders. Trained and validated on 3D CT scans of 2500+ patients from four datasets, our single network can segment total 143 whole-body organs with very high accuracy, closely reaching the upper bound performance level by training four separate segmentation models (i.e., one model per dataset/task).
Comprehensive and Clinically Accurate Head and Neck Organs at Risk Delineation via Stratified Deep Learning: A Large-scale Multi-Institutional Study
Nov 01, 2021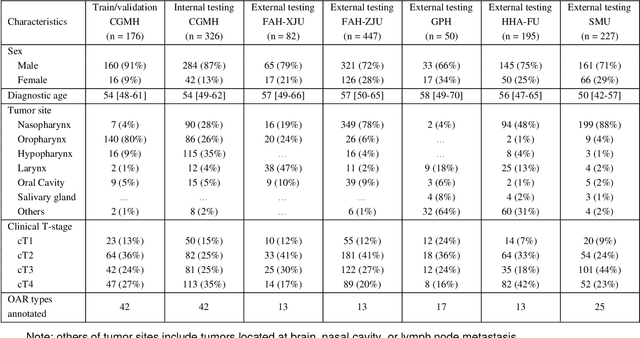
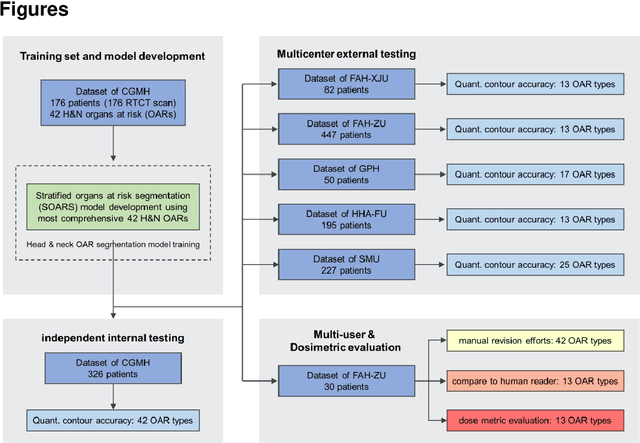
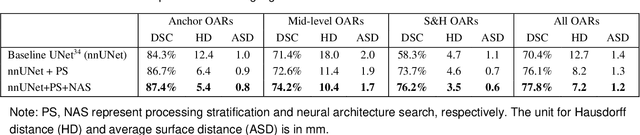
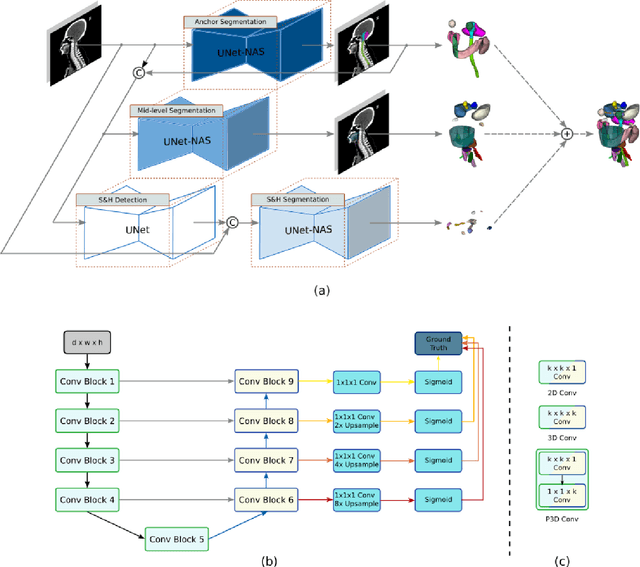
Accurate organ at risk (OAR) segmentation is critical to reduce the radiotherapy post-treatment complications. Consensus guidelines recommend a set of more than 40 OARs in the head and neck (H&N) region, however, due to the predictable prohibitive labor-cost of this task, most institutions choose a substantially simplified protocol by delineating a smaller subset of OARs and neglecting the dose distributions associated with other OARs. In this work we propose a novel, automated and highly effective stratified OAR segmentation (SOARS) system using deep learning to precisely delineate a comprehensive set of 42 H&N OARs. SOARS stratifies 42 OARs into anchor, mid-level, and small & hard subcategories, with specifically derived neural network architectures for each category by neural architecture search (NAS) principles. We built SOARS models using 176 training patients in an internal institution and independently evaluated on 1327 external patients across six different institutions. It consistently outperformed other state-of-the-art methods by at least 3-5% in Dice score for each institutional evaluation (up to 36% relative error reduction in other metrics). More importantly, extensive multi-user studies evidently demonstrated that 98% of the SOARS predictions need only very minor or no revisions for direct clinical acceptance (saving 90% radiation oncologists workload), and their segmentation and dosimetric accuracy are within or smaller than the inter-user variation. These findings confirmed the strong clinical applicability of SOARS for the OAR delineation process in H&N cancer radiotherapy workflows, with improved efficiency, comprehensiveness, and quality.
Multi-institutional Validation of Two-Streamed Deep Learning Method for Automated Delineation of Esophageal Gross Tumor Volume using planning-CT and FDG-PETCT
Oct 11, 2021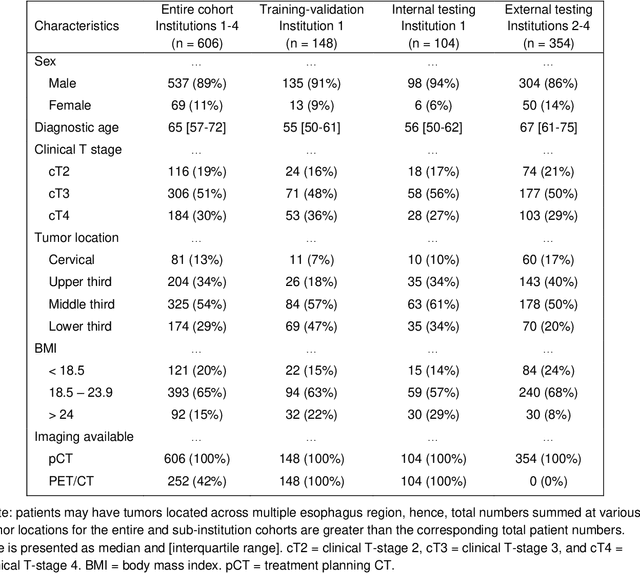
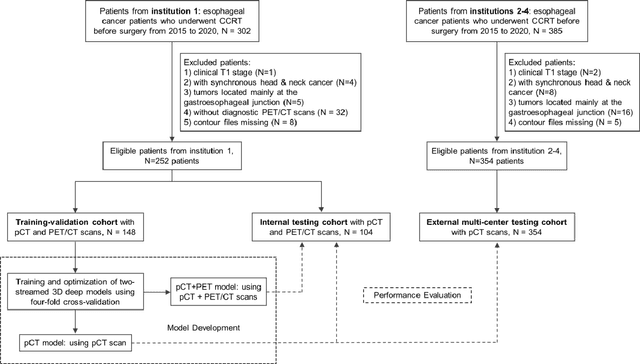
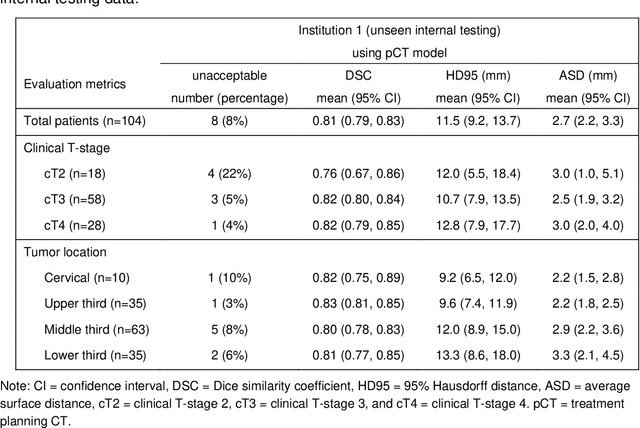
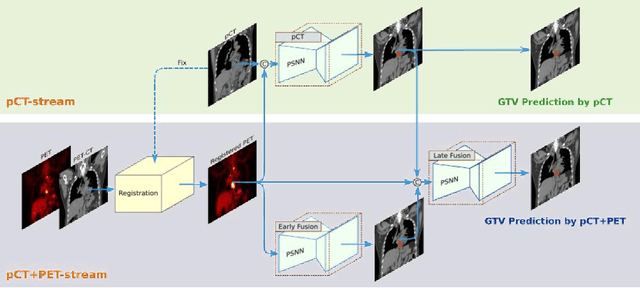
Background: The current clinical workflow for esophageal gross tumor volume (GTV) contouring relies on manual delineation of high labor-costs and interuser variability. Purpose: To validate the clinical applicability of a deep learning (DL) multi-modality esophageal GTV contouring model, developed at 1 institution whereas tested at multiple ones. Methods and Materials: We collected 606 esophageal cancer patients from four institutions. 252 institution-1 patients had a treatment planning-CT (pCT) and a pair of diagnostic FDG-PETCT; 354 patients from other 3 institutions had only pCT. A two-streamed DL model for GTV segmentation was developed using pCT and PETCT scans of a 148 patient institution-1 subset. This built model had the flexibility of segmenting GTVs via only pCT or pCT+PETCT combined. For independent evaluation, the rest 104 institution-1 patients behaved as unseen internal testing, and 354 institutions 2-4 patients were used for external testing. We evaluated manual revision degrees by human experts to assess the contour-editing effort. The performance of the deep model was compared against 4 radiation oncologists in a multiuser study with 20 random external patients. Contouring accuracy and time were recorded for the pre-and post-DL assisted delineation process. Results: Our model achieved high segmentation accuracy in internal testing (mean Dice score: 0.81 using pCT and 0.83 using pCT+PET) and generalized well to external evaluation (mean DSC: 0.80). Expert assessment showed that the predicted contours of 88% patients need only minor or no revision. In multi-user evaluation, with the assistance of a deep model, inter-observer variation and required contouring time were reduced by 37.6% and 48.0%, respectively. Conclusions: Deep learning predicted GTV contours were in close agreement with the ground truth and could be adopted clinically with mostly minor or no changes.