 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-institutional Validation of Two-Streamed Deep Learning Method for Automated Delineation of Esophageal Gross Tumor Volume using planning-CT and FDG-PETCT
Oct 11, 2021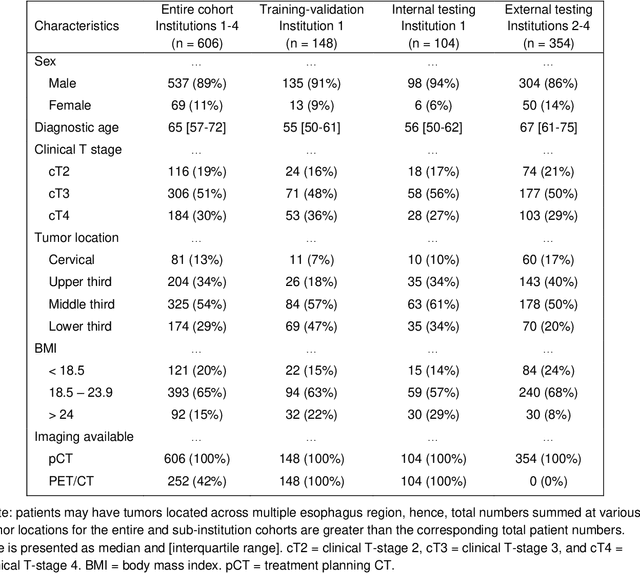
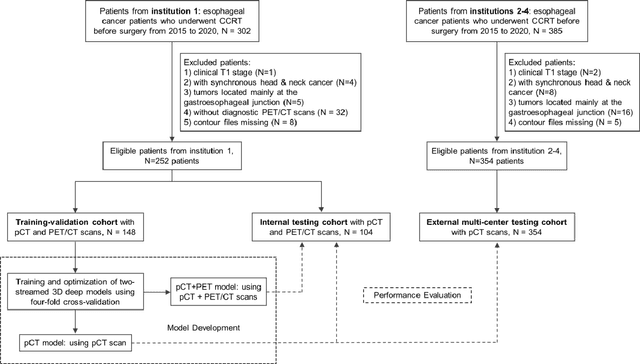
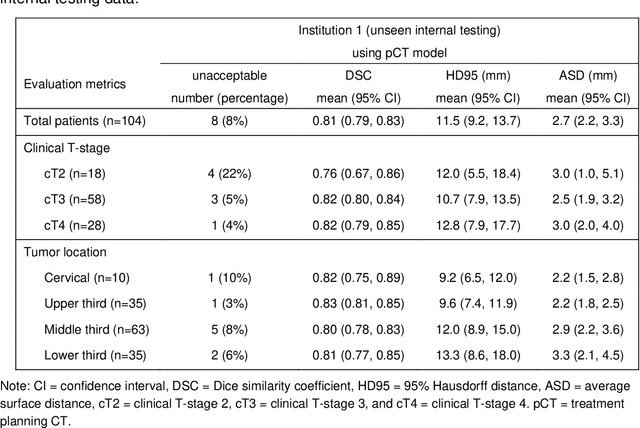
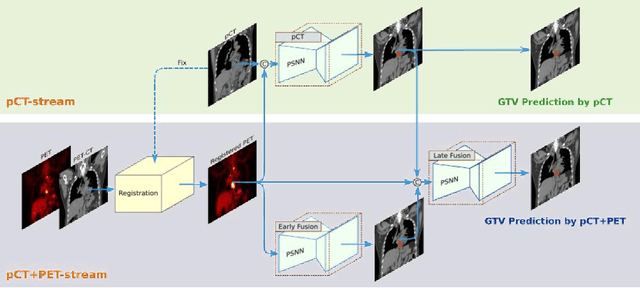
Background: The current clinical workflow for esophageal gross tumor volume (GTV) contouring relies on manual delineation of high labor-costs and interuser variability. Purpose: To validate the clinical applicability of a deep learning (DL) multi-modality esophageal GTV contouring model, developed at 1 institution whereas tested at multiple ones. Methods and Materials: We collected 606 esophageal cancer patients from four institutions. 252 institution-1 patients had a treatment planning-CT (pCT) and a pair of diagnostic FDG-PETCT; 354 patients from other 3 institutions had only pCT. A two-streamed DL model for GTV segmentation was developed using pCT and PETCT scans of a 148 patient institution-1 subset. This built model had the flexibility of segmenting GTVs via only pCT or pCT+PETCT combined. For independent evaluation, the rest 104 institution-1 patients behaved as unseen internal testing, and 354 institutions 2-4 patients were used for external testing. We evaluated manual revision degrees by human experts to assess the contour-editing effort. The performance of the deep model was compared against 4 radiation oncologists in a multiuser study with 20 random external patients. Contouring accuracy and time were recorded for the pre-and post-DL assisted delineation process. Results: Our model achieved high segmentation accuracy in internal testing (mean Dice score: 0.81 using pCT and 0.83 using pCT+PET) and generalized well to external evaluation (mean DSC: 0.80). Expert assessment showed that the predicted contours of 88% patients need only minor or no revision. In multi-user evaluation, with the assistance of a deep model, inter-observer variation and required contouring time were reduced by 37.6% and 48.0%, respectively. Conclusions: Deep learning predicted GTV contours were in close agreement with the ground truth and could be adopted clinically with mostly minor or no changes.
Deep Esophageal Clinical Target Volume Delineation using Encoded 3D Spatial Context of Tumors, Lymph Nodes, and Organs At Risk
Sep 06, 2019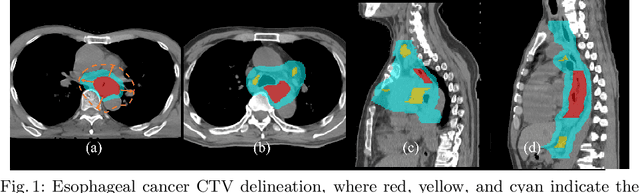

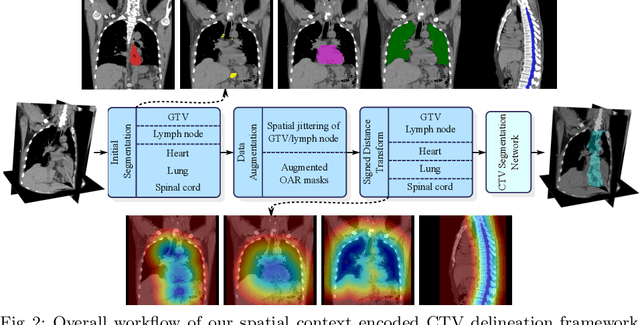

Clinical target volume (CTV) delineation from radiotherapy computed tomography (RTCT) images is used to define the treatment areas containing the gross tumor volume (GTV) and/or sub-clinical malignant disease for radiotherapy (RT). High intra- and inter-user variability makes this a particularly difficult task for esophageal cancer. This motivates automated solutions, which is the aim of our work. Because CTV delineation is highly context-dependent--it must encompass the GTV and regional lymph nodes (LNs) while also avoiding excessive exposure to the organs at risk (OARs)--we formulate it as a deep contextual appearance-based problem using encoded spatial contexts of these anatomical structures. This allows the deep network to better learn from and emulate the margin- and appearance-based delineation performed by human physicians. Additionally, we develop domain-specific data augmentation to inject robustness to our system. Finally, we show that a simple 3D progressive holistically nested network (PHNN), which avoids computationally heavy decoding paths while still aggregating features at different levels of context, can outperform more complicated networks. Cross-validated experiments on a dataset of 135 esophageal cancer patients demonstrate that our encoded spatial context approach can produce concrete performance improvements, with an average Dice score of 83.9% and an average surface distance of 4.2 mm, representing improvements of 3.8% and 2.4 mm, respectively, over the state-of-the-art approach.
Accurate Esophageal Gross Tumor Volume Segmentation in PET/CT using Two-Stream Chained 3D Deep Network Fusion
Sep 06, 2019
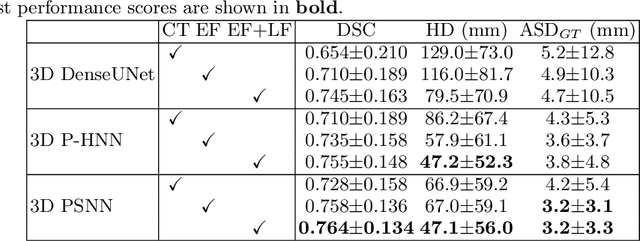
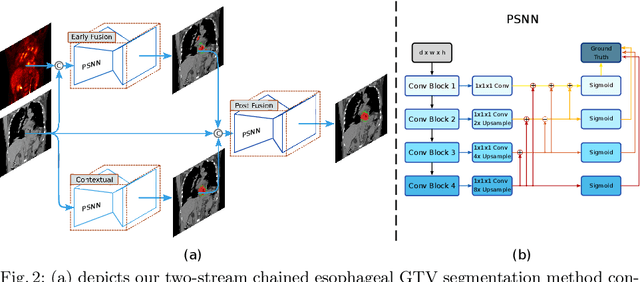

Gross tumor volume (GTV) segmentation is a critical step in esophageal cancer radiotherapy treatment planning. Inconsistencies across oncologists and prohibitive labor costs motivate automated approaches for this task. However, leading approaches are only applied to radiotherapy computed tomography (RTCT) images taken prior to treatment. This limits the performance as RTCT suffers from low contrast between the esophagus, tumor, and surrounding tissues. In this paper, we aim to exploit both RTCT and positron emission tomography (PET) imaging modalities to facilitate more accurate GTV segmentation. By utilizing PET, we emulate medical professionals who frequently delineate GTV boundaries through observation of the RTCT images obtained after prescribing radiotherapy and PET/CT images acquired earlier for cancer staging. To take advantage of both modalities, we present a two-stream chained segmentation approach that effectively fuses the CT and PET modalities via early and late 3D deep-network-based fusion. Furthermore, to effect the fusion and segmentation we propose a simple yet effective progressive semantically nested network (PSNN) model that outperforms more complicated models. Extensive 5-fold cross-validation on 110 esophageal cancer patients, the largest analysis to date, demonstrates that both the proposed two-stream chained segmentation pipeline and the PSNN model can significantly improve the quantitative performance over the previous state-of-the-art work by 11% in absolute Dice score (DSC) (from 0.654 to 0.764) and, at the same time, reducing the Hausdorff distance from 129 mm to 47 mm.