 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Polyglot Harmony: On Multilingual Data Allocation for Large Language Models Pretraining
Sep 19, 2025Large language models (LLMs) have become integral to a wide range of applications worldwide, driving an unprecedented global demand for effective multilingual capabilities. Central to achieving robust multilingual performance is the strategic allocation of language proportions within training corpora. However, determining optimal language ratios is highly challenging due to intricate cross-lingual interactions and sensitivity to dataset scale. This paper introduces Climb (Cross-Lingual Interaction-aware Multilingual Balancing), a novel framework designed to systematically optimize multilingual data allocation. At its core, Climb introduces a cross-lingual interaction-aware language ratio, explicitly quantifying each language's effective allocation by capturing inter-language dependencies. Leveraging this ratio, Climb proposes a principled two-step optimization procedure--first equalizing marginal benefits across languages, then maximizing the magnitude of the resulting language allocation vectors--significantly simplifying the inherently complex multilingual optimization problem. Extensive experiments confirm that Climb can accurately measure cross-lingual interactions across various multilingual settings. LLMs trained with Climb-derived proportions consistently achieve state-of-the-art multilingual performance, even achieving competitive performance with open-sourced LLMs trained with more tokens.
TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training
Aug 25, 2025The data mixture used in the pre-training of a language model is a cornerstone of its final performance. However, a static mixing strategy is suboptimal, as the model's learning preferences for various data domains shift dynamically throughout training. Crucially, observing these evolving preferences in a computationally efficient manner remains a significant challenge. To address this, we propose TiKMiX, a method that dynamically adjusts the data mixture according to the model's evolving preferences. TiKMiX introduces Group Influence, an efficient metric for evaluating the impact of data domains on the model. This metric enables the formulation of the data mixing problem as a search for an optimal, influence-maximizing distribution. We solve this via two approaches: TiKMiX-D for direct optimization, and TiKMiX-M, which uses a regression model to predict a superior mixture. We trained models with different numbers of parameters, on up to 1 trillion tokens. TiKMiX-D exceeds the performance of state-of-the-art methods like REGMIX while using just 20% of the computational resources. TiKMiX-M leads to an average performance gain of 2% across 9 downstream benchmarks. Our experiments reveal that a model's data preferences evolve with training progress and scale, and we demonstrate that dynamically adjusting the data mixture based on Group Influence, a direct measure of these preferences, significantly improves performance by mitigating the underdigestion of data seen with static ratios.
MuRating: A High Quality Data Selecting Approach to Multilingual Large Language Model Pretraining
Jul 02, 2025Data quality is a critical driver of large language model performance, yet existing model-based selection methods focus almost exclusively on English. We introduce MuRating, a scalable framework that transfers high-quality English data-quality signals into a single rater for 17 target languages. MuRating aggregates multiple English "raters" via pairwise comparisons to learn unified document-quality scores,then projects these judgments through translation to train a multilingual evaluator on monolingual, cross-lingual, and parallel text pairs. Applied to web data, MuRating selects balanced subsets of English and multilingual content to pretrain a 1.2 B-parameter LLaMA model. Compared to strong baselines, including QuRater, AskLLM, DCLM and so on, our approach boosts average accuracy on both English benchmarks and multilingual evaluations, with especially large gains on knowledge-intensive tasks. We further analyze translation fidelity, selection biases, and underrepresentation of narrative material, outlining directions for future work.
AUTOCT: Automating Interpretable Clinical Trial Prediction with LLM Agents
Jun 04, 2025



Clinical trials are critical for advancing medical treatments but remain prohibitively expensive and time-consuming. Accurate prediction of clinical trial outcomes can significantly reduce research and development costs and accelerate drug discovery. While recent deep learning models have shown promise by leveraging unstructured data, their black-box nature, lack of interpretability, and vulnerability to label leakage limit their practical use in high-stakes biomedical contexts. In this work, we propose AutoCT, a novel framework that combines the reasoning capabilities of large language models with the explainability of classical machine learning. AutoCT autonomously generates, evaluates, and refines tabular features based on public information without human input. Our method uses Monte Carlo Tree Search to iteratively optimize predictive performance. Experimental results show that AutoCT performs on par with or better than SOTA methods on clinical trial prediction tasks within only a limited number of self-refinement iterations, establishing a new paradigm for scalable, interpretable, and cost-efficient clinical trial prediction.
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
Apr 23, 2025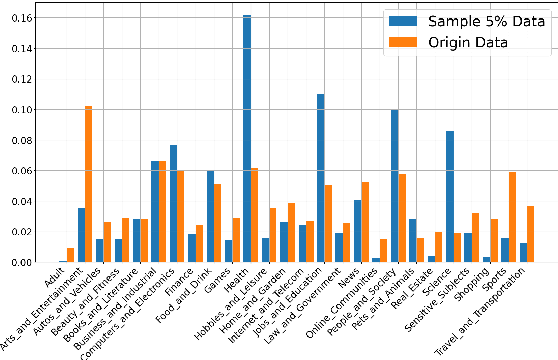
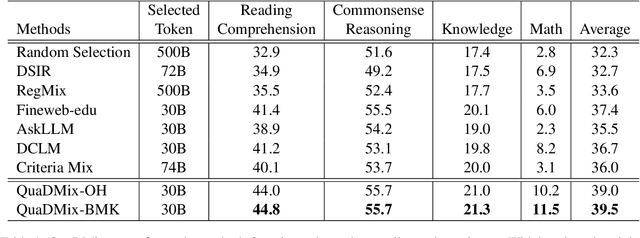
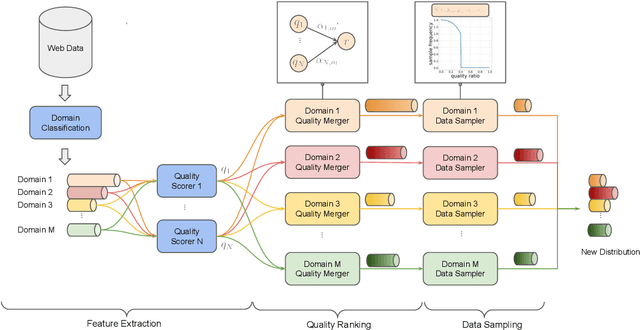

Quality and diversity are two critical metrics for the training data of large language models (LLMs), positively impacting performance. Existing studies often optimize these metrics separately, typically by first applying quality filtering and then adjusting data proportions. However, these approaches overlook the inherent trade-off between quality and diversity, necessitating their joint consideration. Given a fixed training quota, it is essential to evaluate both the quality of each data point and its complementary effect on the overall dataset. In this paper, we introduce a unified data selection framework called QuaDMix, which automatically optimizes the data distribution for LLM pretraining while balancing both quality and diversity. Specifically, we first propose multiple criteria to measure data quality and employ domain classification to distinguish data points, thereby measuring overall diversity. QuaDMix then employs a unified parameterized data sampling function that determines the sampling probability of each data point based on these quality and diversity related labels. To accelerate the search for the optimal parameters involved in the QuaDMix framework, we conduct simulated experiments on smaller models and use LightGBM for parameters searching, inspired by the RegMix method. Our experiments across diverse models and datasets demonstrate that QuaDMix achieves an average performance improvement of 7.2% across multiple benchmarks. These results outperform the independent strategies for quality and diversity, highlighting the necessity and ability to balance data quality and diversity.
SAME++: A Self-supervised Anatomical eMbeddings Enhanced medical image registration framework using stable sampling and regularized transformation
Nov 25, 2023Image registration is a fundamental medical image analysis task. Ideally, registration should focus on aligning semantically corresponding voxels, i.e., the same anatomical locations. However, existing methods often optimize similarity measures computed directly on intensities or on hand-crafted features, which lack anatomical semantic information. These similarity measures may lead to sub-optimal solutions where large deformations, complex anatomical differences, or cross-modality imagery exist. In this work, we introduce a fast and accurate method for unsupervised 3D medical image registration building on top of a Self-supervised Anatomical eMbedding (SAM) algorithm, which is capable of computing dense anatomical correspondences between two images at the voxel level. We name our approach SAM-Enhanced registration (SAME++), which decomposes image registration into four steps: affine transformation, coarse deformation, deep non-parametric transformation, and instance optimization. Using SAM embeddings, we enhance these steps by finding more coherent correspondence and providing features with better semantic guidance. We extensively evaluated SAME++ using more than 50 labeled organs on three challenging inter-subject registration tasks of different body parts. As a complete registration framework, SAME++ markedly outperforms leading methods by $4.2\%$ - $8.2\%$ in terms of Dice score while being orders of magnitude faster than numerical optimization-based methods. Code is available at \url{https://github.com/alibaba-damo-academy/same}.
Unsupervised Domain Adaptation through Shape Modeling for Medical Image Segmentation
Jul 06, 2022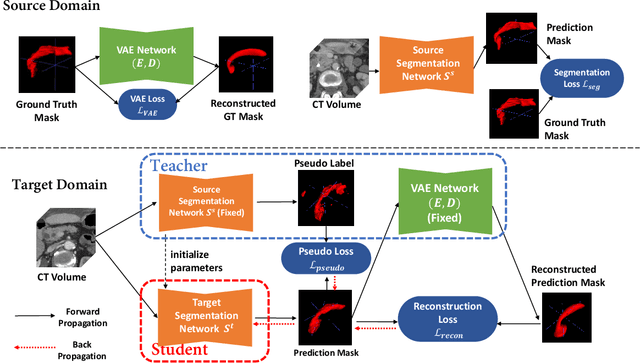
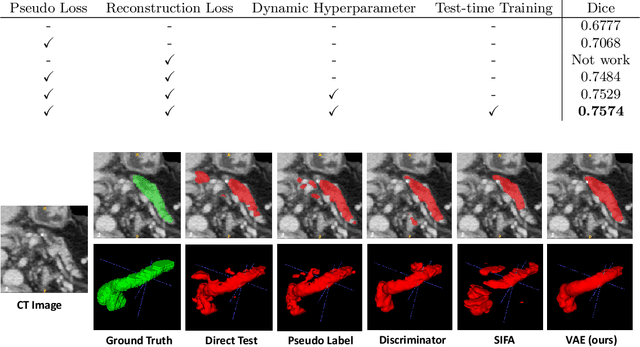
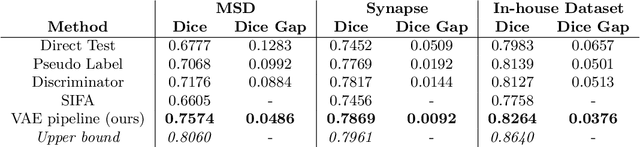
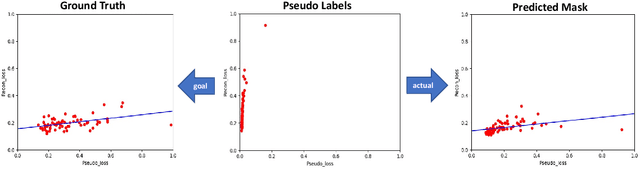
Shape information is a strong and valuable prior in segmenting organs in medical images. However, most current deep learning based segmentation algorithms have not taken shape information into consideration, which can lead to bias towards texture. We aim at modeling shape explicitly and using it to help medical image segmentation. Previous methods proposed Variational Autoencoder (VAE) based models to learn the distribution of shape for a particular organ and used it to automatically evaluate the quality of a segmentation prediction by fitting it into the learned shape distribution. Based on which we aim at incorporating VAE into current segmentation pipelines. Specifically, we propose a new unsupervised domain adaptation pipeline based on a pseudo loss and a VAE reconstruction loss under a teacher-student learning paradigm. Both losses are optimized simultaneously and, in return, boost the segmentation task performance. Extensive experiments on three public Pancreas segmentation datasets as well as two in-house Pancreas segmentation datasets show consistent improvements with at least 2.8 points gain in the Dice score, demonstrating the effectiveness of our method in challenging unsupervised domain adaptation scenarios for medical image segmentation. We hope this work will advance shape analysis and geometric learning in medical imaging.
Learning to Bootstrap for Combating Label Noise
Feb 09, 2022
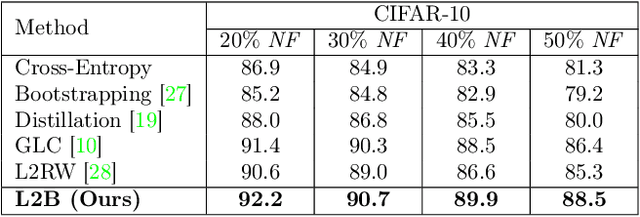
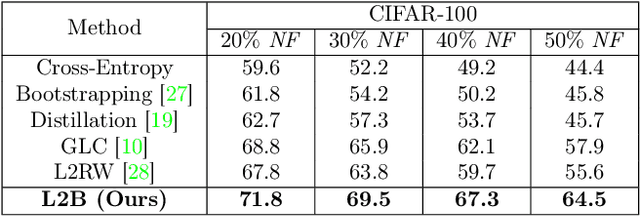
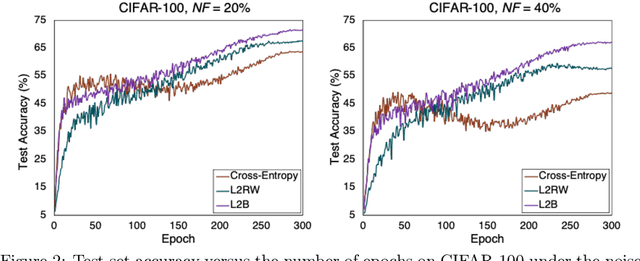
Deep neural networks are powerful tools for representation learning, but can easily overfit to noisy labels which are prevalent in many real-world scenarios. Generally, noisy supervision could stem from variation among labelers, label corruption by adversaries, etc. To combat such label noises, one popular line of approach is to apply customized weights to the training instances, so that the corrupted examples contribute less to the model learning. However, such learning mechanisms potentially erase important information about the data distribution and therefore yield suboptimal results. To leverage useful information from the corrupted instances, an alternative is the bootstrapping loss, which reconstructs new training targets on-the-fly by incorporating the network's own predictions (i.e., pseudo-labels). In this paper, we propose a more generic learnable loss objective which enables a joint reweighting of instances and labels at once. Specifically, our method dynamically adjusts the per-sample importance weight between the real observed labels and pseudo-labels, where the weights are efficiently determined in a meta process. Compared to the previous instance reweighting methods, our approach concurrently conducts implicit relabeling, and thereby yield substantial improvements with almost no extra cost. Extensive experimental results demonstrated the strengths of our approach over existing methods on multiple natural and medical image benchmark datasets, including CIFAR-10, CIFAR-100, ISIC2019 and Clothing 1M. The code is publicly available at https://github.com/yuyinzhou/L2B.
External Attention Assisted Multi-Phase Splenic Vascular Injury Segmentation with Limited Data
Jan 04, 2022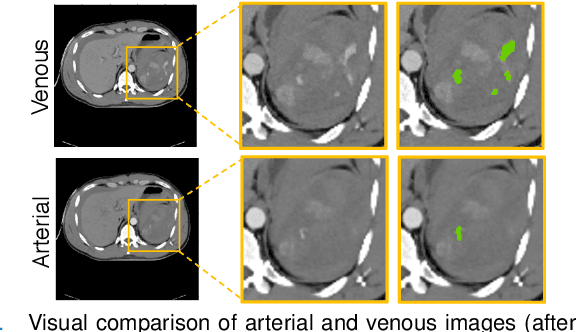
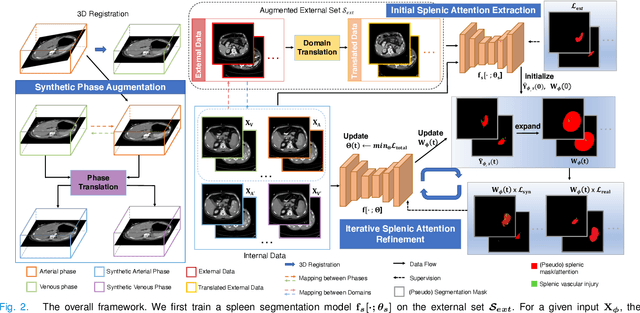
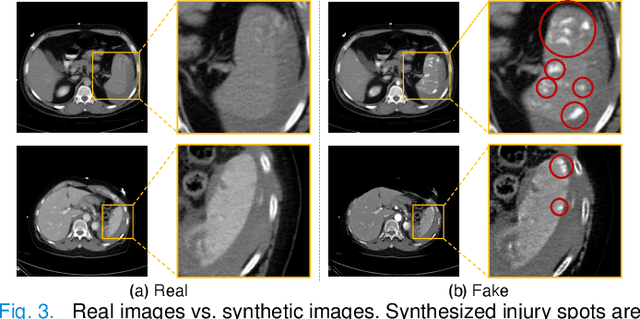
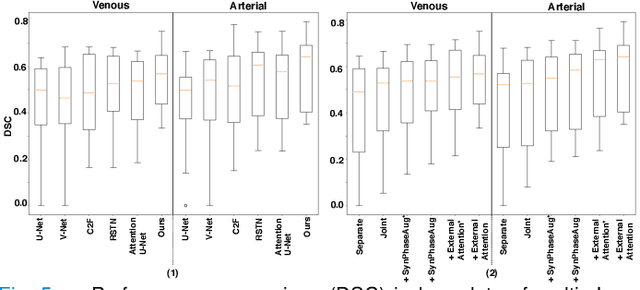
The spleen is one of the most commonly injured solid organs in blunt abdominal trauma. The development of automatic segmentation systems from multi-phase CT for splenic vascular injury can augment severity grading for improving clinical decision support and outcome prediction. However, accurate segmentation of splenic vascular injury is challenging for the following reasons: 1) Splenic vascular injury can be highly variant in shape, texture, size, and overall appearance; and 2) Data acquisition is a complex and expensive procedure that requires intensive efforts from both data scientists and radiologists, which makes large-scale well-annotated datasets hard to acquire in general. In light of these challenges, we hereby design a novel framework for multi-phase splenic vascular injury segmentation, especially with limited data. On the one hand, we propose to leverage external data to mine pseudo splenic masks as the spatial attention, dubbed external attention, for guiding the segmentation of splenic vascular injury. On the other hand, we develop a synthetic phase augmentation module, which builds upon generative adversarial networks, for populating the internal data by fully leveraging the relation between different phases. By jointly enforcing external attention and populating internal data representation during training, our proposed method outperforms other competing methods and substantially improves the popular DeepLab-v3+ baseline by more than 7% in terms of average DSC, which confirms its effectiveness.
SAME: Deformable Image Registration based on Self-supervised Anatomical Embeddings
Sep 23, 2021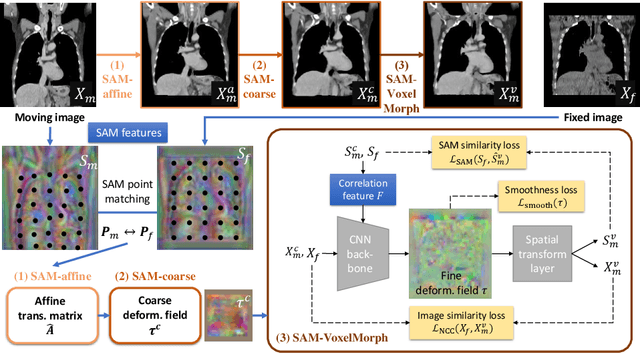
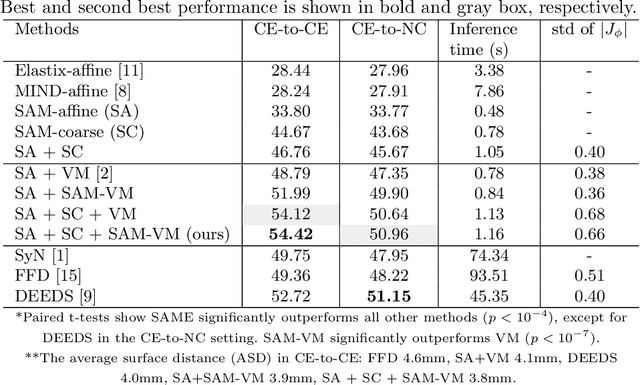


In this work, we introduce a fast and accurate method for unsupervised 3D medical image registration. This work is built on top of a recent algorithm SAM, which is capable of computing dense anatomical/semantic correspondences between two images at the pixel level. Our method is named SAME, which breaks down image registration into three steps: affine transformation, coarse deformation, and deep deformable registration. Using SAM embeddings, we enhance these steps by finding more coherent correspondences, and providing features and a loss function with better semantic guidance. We collect a multi-phase chest computed tomography dataset with 35 annotated organs for each patient and conduct inter-subject registration for quantitative evaluation. Results show that SAME outperforms widely-used traditional registration techniques (Elastix FFD, ANTs SyN) and learning based VoxelMorph method by at least 4.7% and 2.7% in Dice scores for two separate tasks of within-contrast-phase and across-contrast-phase registration, respectively. SAME achieves the comparable performance to the best traditional registration method, DEEDS (from our evaluation), while being orders of magnitude faster (from 45 seconds to 1.2 seconds).