 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastSAM-3DSlicer: A 3D-Slicer Extension for 3D Volumetric Segment Anything Model with Uncertainty Quantification
Jul 17, 2024Accurate segmentation of anatomical structures and pathological regions in medical images is crucial for diagnosis, treatment planning, and disease monitoring. While the Segment Anything Model (SAM) and its variants have demonstrated impressive interactive segmentation capabilities on image types not seen during training without the need for domain adaptation or retraining, their practical application in volumetric 3D medical imaging workflows has been hindered by the lack of a user-friendly interface. To address this challenge, we introduce FastSAM-3DSlicer, a 3D Slicer extension that integrates both 2D and 3D SAM models, including SAM-Med2D, MedSAM, SAM-Med3D, and FastSAM-3D. Building on the well-established open-source 3D Slicer platform, our extension enables efficient, real-time segmentation of 3D volumetric medical images, with seamless interaction and visualization. By automating the handling of raw image data, user prompts, and segmented masks, FastSAM-3DSlicer provides a streamlined, user-friendly interface that can be easily incorporated into medical image analysis workflows. Performance evaluations reveal that the FastSAM-3DSlicer extension running FastSAM-3D achieves low inference times of only 1.09 seconds per volume on CPU and 0.73 seconds per volume on GPU, making it well-suited for real-time interactive segmentation. Moreover, we introduce an uncertainty quantification scheme that leverages the rapid inference capabilities of FastSAM-3D for practical implementation, further enhancing its reliability and applicability in medical settings. FastSAM-3DSlicer offers an interactive platform and user interface for 2D and 3D interactive volumetric medical image segmentation, offering a powerful combination of efficiency, precision, and ease of use with SAMs. The source code and a video demonstration are publicly available at https://github.com/arcadelab/FastSAM3D_slicer.
FastSAM3D: An Efficient Segment Anything Model for 3D Volumetric Medical Images
Mar 14, 2024
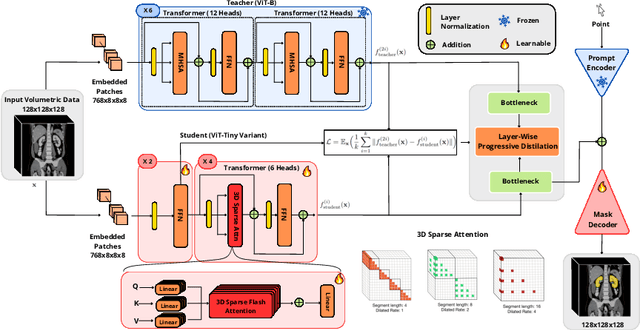


Segment anything models (SAMs) are gaining attention for their zero-shot generalization capability in segmenting objects of unseen classes and in unseen domains when properly prompted. Interactivity is a key strength of SAMs, allowing users to iteratively provide prompts that specify objects of interest to refine outputs. However, to realize the interactive use of SAMs for 3D medical imaging tasks, rapid inference times are necessary. High memory requirements and long processing delays remain constraints that hinder the adoption of SAMs for this purpose. Specifically, while 2D SAMs applied to 3D volumes contend with repetitive computation to process all slices independently, 3D SAMs suffer from an exponential increase in model parameters and FLOPS. To address these challenges, we present FastSAM3D which accelerates SAM inference to 8 milliseconds per 128*128*128 3D volumetric image on an NVIDIA A100 GPU. This speedup is accomplished through 1) a novel layer-wise progressive distillation scheme that enables knowledge transfer from a complex 12-layer ViT-B to a lightweight 6-layer ViT-Tiny variant encoder without training from scratch; and 2) a novel 3D sparse flash attention to replace vanilla attention operators, substantially reducing memory needs and improving parallelization. Experiments on three diverse datasets reveal that FastSAM3D achieves a remarkable speedup of 527.38x compared to 2D SAMs and 8.75x compared to 3D SAMs on the same volumes without significant performance decline. Thus, FastSAM3D opens the door for low-cost truly interactive SAM-based 3D medical imaging segmentation with commonly used GPU hardware. Code is available at https://github.com/arcadelab/FastSAM3D.
External Attention Assisted Multi-Phase Splenic Vascular Injury Segmentation with Limited Data
Jan 04, 2022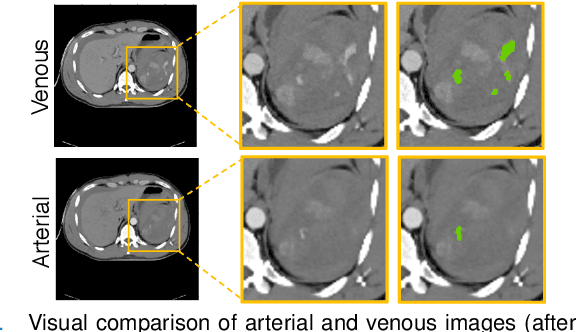
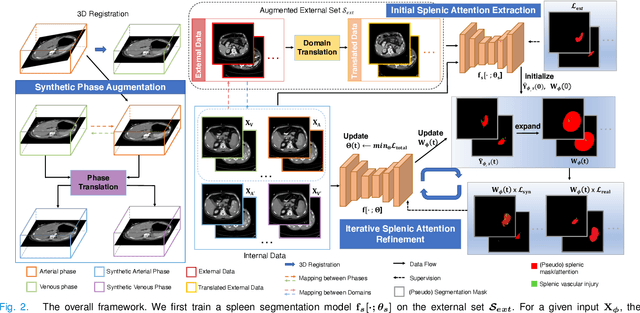
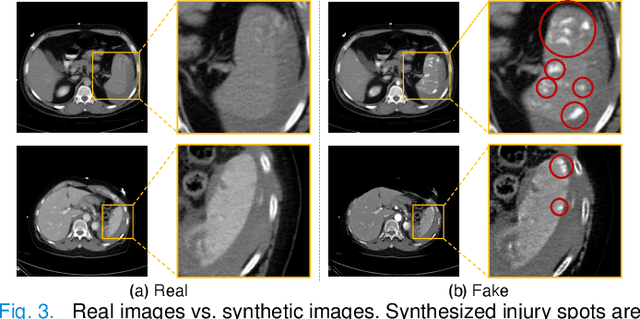
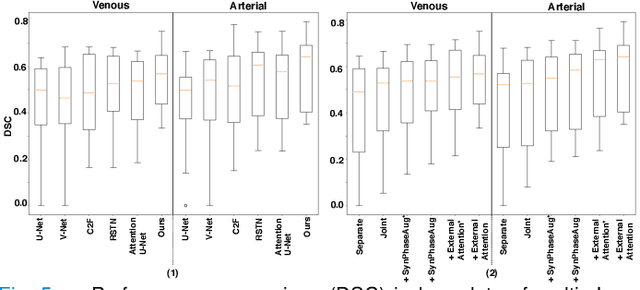
The spleen is one of the most commonly injured solid organs in blunt abdominal trauma. The development of automatic segmentation systems from multi-phase CT for splenic vascular injury can augment severity grading for improving clinical decision support and outcome prediction. However, accurate segmentation of splenic vascular injury is challenging for the following reasons: 1) Splenic vascular injury can be highly variant in shape, texture, size, and overall appearance; and 2) Data acquisition is a complex and expensive procedure that requires intensive efforts from both data scientists and radiologists, which makes large-scale well-annotated datasets hard to acquire in general. In light of these challenges, we hereby design a novel framework for multi-phase splenic vascular injury segmentation, especially with limited data. On the one hand, we propose to leverage external data to mine pseudo splenic masks as the spatial attention, dubbed external attention, for guiding the segmentation of splenic vascular injury. On the other hand, we develop a synthetic phase augmentation module, which builds upon generative adversarial networks, for populating the internal data by fully leveraging the relation between different phases. By jointly enforcing external attention and populating internal data representation during training, our proposed method outperforms other competing methods and substantially improves the popular DeepLab-v3+ baseline by more than 7% in terms of average DSC, which confirms its effectiveness.
An Interpretable Approach to Automated Severity Scoring in Pelvic Trauma
May 21, 2021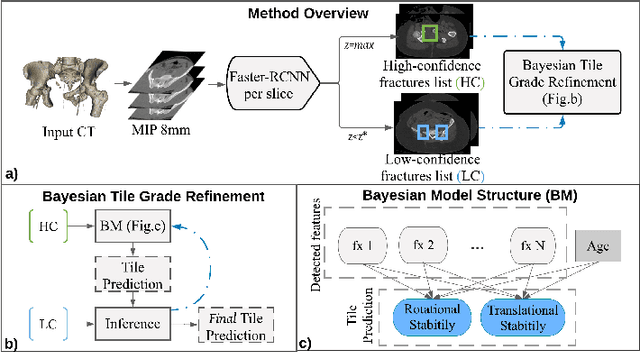

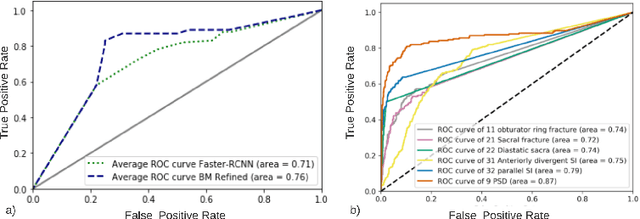
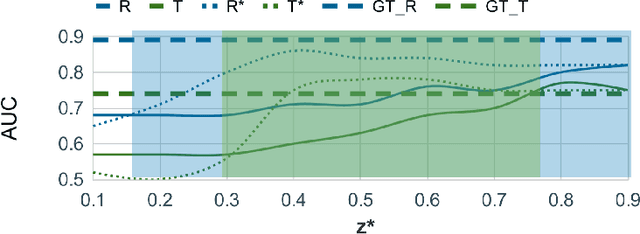
Pelvic ring disruptions result from blunt injury mechanisms and are often found in patients with multi-system trauma. To grade pelvic fracture severity in trauma victims based on whole-body CT, the Tile AO/OTA classification is frequently used. Due to the high volume of whole-body trauma CTs generated in busy trauma centers, an automated approach to Tile classification would provide substantial value, e.,g., to prioritize the reading queue of the attending trauma radiologist. In such scenario, an automated method should perform grading based on a transparent process and based on interpretable features to enable interaction with human readers and lower their workload by offering insights from a first automated read of the scan. This paper introduces an automated yet interpretable pelvic trauma decision support system to assist radiologists in fracture detection and Tile grade classification. The method operates similarly to human interpretation of CT scans and first detects distinct pelvic fractures on CT with high specificity using a Faster-RCNN model that are then interpreted using a structural causal model based on clinical best practices to infer an initial Tile grade. The Bayesian causal model and finally, the object detector are then queried for likely co-occurring fractures that may have been rejected initially due to the highly specific operating point of the detector, resulting in an updated list of detected fractures and corresponding final Tile grade. Our method is transparent in that it provides finding location and type using the object detector, as well as information on important counterfactuals that would invalidate the system's recommendation and achieves an AUC of 83.3%/85.1% for translational/rotational instability. Despite being designed for human-machine teaming, our approach does not compromise on performance compared to previous black-box approaches.
Multi-Scale Attentional Network for Multi-Focal Segmentation of Active Bleed after Pelvic Fractures
Jun 23, 2019

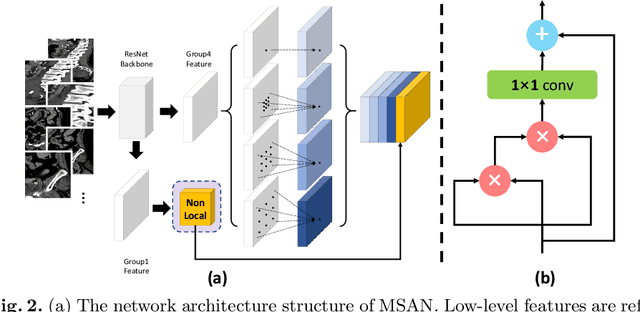
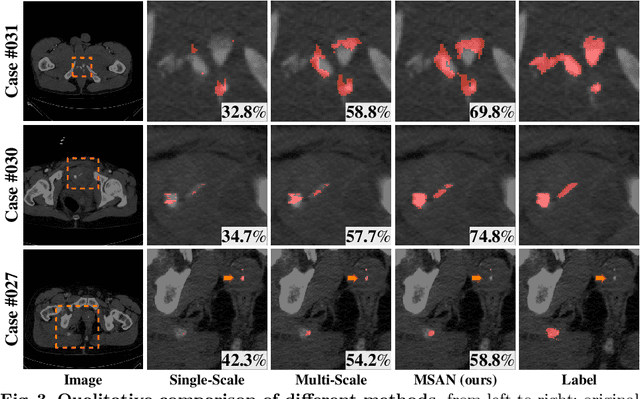
Trauma is the worldwide leading cause of death and disability in those younger than 45 years, and pelvic fractures are a major source of morbidity and mortality. Automated segmentation of multiple foci of arterial bleeding from abdominopelvic trauma CT could provide rapid objective measurements of the total extent of active bleeding, potentially augmenting outcome prediction at the point of care, while improving patient triage, allocation of appropriate resources, and time to definitive intervention. In spite of the importance of active bleeding in the quick tempo of trauma care, the task is still quite challenging due to the variable contrast, intensity, location, size, shape, and multiplicity of bleeding foci. Existing work [4] presents a heuristic rule-based segmentation technique which requires multiple stages and cannot be efficiently optimized end-to-end. To this end, we present, Multi-Scale Attentional Network (MSAN), the first yet reliable end-to-end network, for automated segmentation of active hemorrhage from contrast-enhanced trauma CT scans. MSAN consists of the following components: 1) an encoder which fully integrates the global contextual information from holistic 2D slices; 2) a multi-scale strategy applied both in the training stage and the inference stage to handle the challenges induced by variation of target sizes; 3) an attentional module to further refine the deep features, leading to better segmentation quality; and 4) a multi-view mechanism to fully leverage the 3D information. Our MSAN reports a significant improvement of more than 7% compared to prior arts in terms of DSC.