 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeedy MASt3R
Mar 13, 2025Image matching is a key component of modern 3D vision algorithms, essential for accurate scene reconstruction and localization. MASt3R redefines image matching as a 3D task by leveraging DUSt3R and introducing a fast reciprocal matching scheme that accelerates matching by orders of magnitude while preserving theoretical guarantees. This approach has gained strong traction, with DUSt3R and MASt3R collectively cited over 250 times in a short span, underscoring their impact. However, despite its accuracy, MASt3R's inference speed remains a bottleneck. On an A40 GPU, latency per image pair is 198.16 ms, mainly due to computational overhead from the ViT encoder-decoder and Fast Reciprocal Nearest Neighbor (FastNN) matching. To address this, we introduce Speedy MASt3R, a post-training optimization framework that enhances inference efficiency while maintaining accuracy. It integrates multiple optimization techniques, including FlashMatch-an approach leveraging FlashAttention v2 with tiling strategies for improved efficiency, computation graph optimization via layer and tensor fusion having kernel auto-tuning with TensorRT (GraphFusion), and a streamlined FastNN pipeline that reduces memory access time from quadratic to linear while accelerating block-wise correlation scoring through vectorized computation (FastNN-Lite). Additionally, it employs mixed-precision inference with FP16/FP32 hybrid computations (HybridCast), achieving speedup while preserving numerical precision. Evaluated on Aachen Day-Night, InLoc, 7-Scenes, ScanNet1500, and MegaDepth1500, Speedy MASt3R achieves a 54% reduction in inference time (198 ms to 91 ms per image pair) without sacrificing accuracy. This advancement enables real-time 3D understanding, benefiting applications like mixed reality navigation and large-scale 3D scene reconstruction.
FastSAM3D: An Efficient Segment Anything Model for 3D Volumetric Medical Images
Mar 14, 2024
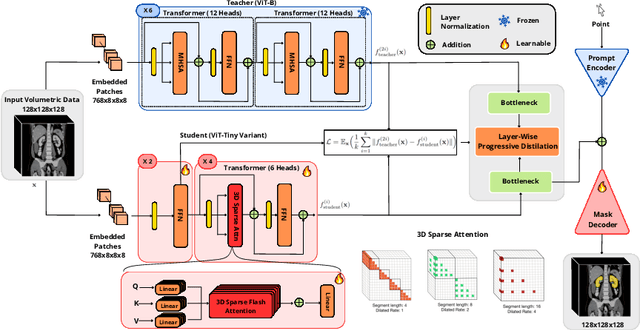


Segment anything models (SAMs) are gaining attention for their zero-shot generalization capability in segmenting objects of unseen classes and in unseen domains when properly prompted. Interactivity is a key strength of SAMs, allowing users to iteratively provide prompts that specify objects of interest to refine outputs. However, to realize the interactive use of SAMs for 3D medical imaging tasks, rapid inference times are necessary. High memory requirements and long processing delays remain constraints that hinder the adoption of SAMs for this purpose. Specifically, while 2D SAMs applied to 3D volumes contend with repetitive computation to process all slices independently, 3D SAMs suffer from an exponential increase in model parameters and FLOPS. To address these challenges, we present FastSAM3D which accelerates SAM inference to 8 milliseconds per 128*128*128 3D volumetric image on an NVIDIA A100 GPU. This speedup is accomplished through 1) a novel layer-wise progressive distillation scheme that enables knowledge transfer from a complex 12-layer ViT-B to a lightweight 6-layer ViT-Tiny variant encoder without training from scratch; and 2) a novel 3D sparse flash attention to replace vanilla attention operators, substantially reducing memory needs and improving parallelization. Experiments on three diverse datasets reveal that FastSAM3D achieves a remarkable speedup of 527.38x compared to 2D SAMs and 8.75x compared to 3D SAMs on the same volumes without significant performance decline. Thus, FastSAM3D opens the door for low-cost truly interactive SAM-based 3D medical imaging segmentation with commonly used GPU hardware. Code is available at https://github.com/arcadelab/FastSAM3D.