 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
SAGE: Scalable Agentic 3D Scene Generation for Embodied AI
Feb 10, 2026Real-world data collection for embodied agents remains costly and unsafe, calling for scalable, realistic, and simulator-ready 3D environments. However, existing scene-generation systems often rely on rule-based or task-specific pipelines, yielding artifacts and physically invalid scenes. We present SAGE, an agentic framework that, given a user-specified embodied task (e.g., "pick up a bowl and place it on the table"), understands the intent and automatically generates simulation-ready environments at scale. The agent couples multiple generators for layout and object composition with critics that evaluate semantic plausibility, visual realism, and physical stability. Through iterative reasoning and adaptive tool selection, it self-refines the scenes until meeting user intent and physical validity. The resulting environments are realistic, diverse, and directly deployable in modern simulators for policy training. Policies trained purely on this data exhibit clear scaling trends and generalize to unseen objects and layouts, demonstrating the promise of simulation-driven scaling for embodied AI. Code, demos, and the SAGE-10k dataset can be found on the project page here: https://nvlabs.github.io/sage.
DuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling
Dec 30, 2025Data scarcity remains a fundamental barrier to achieving fully autonomous surgical robots. While large scale vision language action (VLA) models have shown impressive generalization in household and industrial manipulation by leveraging paired video action data from diverse domains, surgical robotics suffers from the paucity of datasets that include both visual observations and accurate robot kinematics. In contrast, vast corpora of surgical videos exist, but they lack corresponding action labels, preventing direct application of imitation learning or VLA training. In this work, we aim to alleviate this problem by learning policy models from SurgWorld, a world model designed for surgical physical AI. We curated the Surgical Action Text Alignment (SATA) dataset with detailed action description specifically for surgical robots. Then we built SurgeWorld based on the most advanced physical AI world model and SATA. It's able to generate diverse, generalizable and realistic surgery videos. We are also the first to use an inverse dynamics model to infer pseudokinematics from synthetic surgical videos, producing synthetic paired video action data. We demonstrate that a surgical VLA policy trained with these augmented data significantly outperforms models trained only on real demonstrations on a real surgical robot platform. Our approach offers a scalable path toward autonomous surgical skill acquisition by leveraging the abundance of unlabeled surgical video and generative world modeling, thus opening the door to generalizable and data efficient surgical robot policies.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
Efficient Part-level 3D Object Generation via Dual Volume Packing
Jun 11, 2025Recent progress in 3D object generation has greatly improved both the quality and efficiency. However, most existing methods generate a single mesh with all parts fused together, which limits the ability to edit or manipulate individual parts. A key challenge is that different objects may have a varying number of parts. To address this, we propose a new end-to-end framework for part-level 3D object generation. Given a single input image, our method generates high-quality 3D objects with an arbitrary number of complete and semantically meaningful parts. We introduce a dual volume packing strategy that organizes all parts into two complementary volumes, allowing for the creation of complete and interleaved parts that assemble into the final object. Experiments show that our model achieves better quality, diversity, and generalization than previous image-based part-level generation methods.
Scenethesis: A Language and Vision Agentic Framework for 3D Scene Generation
May 05, 2025Synthesizing interactive 3D scenes from text is essential for gaming, virtual reality, and embodied AI. However, existing methods face several challenges. Learning-based approaches depend on small-scale indoor datasets, limiting the scene diversity and layout complexity. While large language models (LLMs) can leverage diverse text-domain knowledge, they struggle with spatial realism, often producing unnatural object placements that fail to respect common sense. Our key insight is that vision perception can bridge this gap by providing realistic spatial guidance that LLMs lack. To this end, we introduce Scenethesis, a training-free agentic framework that integrates LLM-based scene planning with vision-guided layout refinement. Given a text prompt, Scenethesis first employs an LLM to draft a coarse layout. A vision module then refines it by generating an image guidance and extracting scene structure to capture inter-object relations. Next, an optimization module iteratively enforces accurate pose alignment and physical plausibility, preventing artifacts like object penetration and instability. Finally, a judge module verifies spatial coherence. Comprehensive experiments show that Scenethesis generates diverse, realistic, and physically plausible 3D interactive scenes, making it valuable for virtual content creation, simulation environments, and embodied AI research.
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025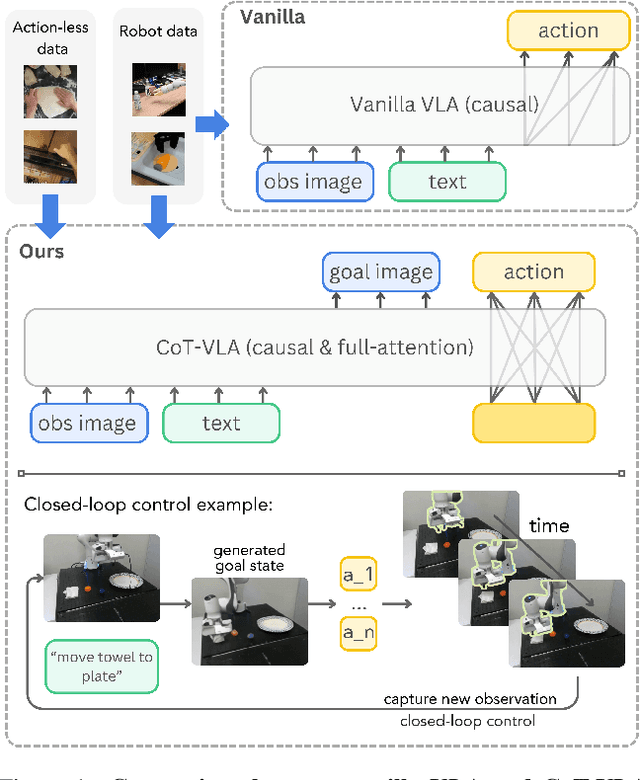

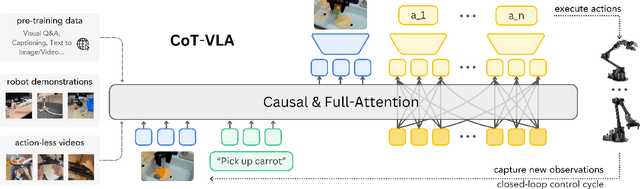
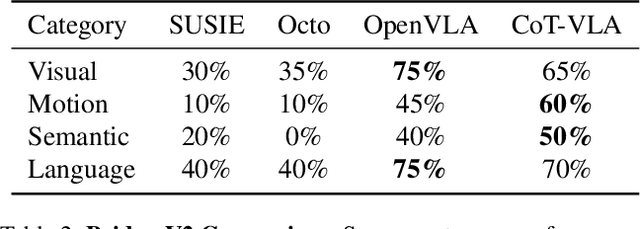
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.