 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Policy Evaluation with Video World Models
Nov 17, 2025Training generalist policies for robotic manipulation has shown great promise, as they enable language-conditioned, multi-task behaviors across diverse scenarios. However, evaluating these policies remains difficult because real-world testing is expensive, time-consuming, and labor-intensive. It also requires frequent environment resets and carries safety risks when deploying unproven policies on physical robots. Manually creating and populating simulation environments with assets for robotic manipulation has not addressed these issues, primarily due to the significant engineering effort required and the often substantial sim-to-real gap, both in terms of physics and rendering. In this paper, we explore the use of action-conditional video generation models as a scalable way to learn world models for policy evaluation. We demonstrate how to incorporate action conditioning into existing pre-trained video generation models. This allows leveraging internet-scale in-the-wild online videos during the pre-training stage, and alleviates the need for a large dataset of paired video-action data, which is expensive to collect for robotic manipulation. Our paper examines the effect of dataset diversity, pre-trained weight and common failure cases for the proposed evaluation pipeline. Our experiments demonstrate that, across various metrics, including policy ranking and the correlation between actual policy values and predicted policy values, these models offer a promising approach for evaluating policies without requiring real-world interactions.
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Sep 19, 2025Online reinforcement learning (RL) has been central to post-training language models, but its extension to diffusion models remains challenging due to intractable likelihoods. Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forward-reverse inconsistency, and complicated integration with classifier-free guidance (CFG). We introduce Diffusion Negative-aware FineTuning (DiffusionNFT), a new online RL paradigm that optimizes diffusion models directly on the forward process via flow matching. DiffusionNFT contrasts positive and negative generations to define an implicit policy improvement direction, naturally incorporating reinforcement signals into the supervised learning objective. This formulation enables training with arbitrary black-box solvers, eliminates the need for likelihood estimation, and requires only clean images rather than sampling trajectories for policy optimization. DiffusionNFT is up to $25\times$ more efficient than FlowGRPO in head-to-head comparisons, while being CFG-free. For instance, DiffusionNFT improves the GenEval score from 0.24 to 0.98 within 1k steps, while FlowGRPO achieves 0.95 with over 5k steps and additional CFG employment. By leveraging multiple reward models, DiffusionNFT significantly boosts the performance of SD3.5-Medium in every benchmark tested.
Bridging Supervised Learning and Reinforcement Learning in Math Reasoning
May 23, 2025Reinforcement Learning (RL) has played a central role in the recent surge of LLMs' math abilities by enabling self-improvement through binary verifier signals. In contrast, Supervised Learning (SL) is rarely considered for such verification-driven training, largely due to its heavy reliance on reference answers and inability to reflect on mistakes. In this work, we challenge the prevailing notion that self-improvement is exclusive to RL and propose Negative-aware Fine-Tuning (NFT) -- a supervised approach that enables LLMs to reflect on their failures and improve autonomously with no external teachers. In online training, instead of throwing away self-generated negative answers, NFT constructs an implicit negative policy to model them. This implicit policy is parameterized with the same positive LLM we target to optimize on positive data, enabling direct policy optimization on all LLMs' generations. We conduct experiments on 7B and 32B models in math reasoning tasks. Results consistently show that through the additional leverage of negative feedback, NFT significantly improves over SL baselines like Rejection sampling Fine-Tuning, matching or even surpassing leading RL algorithms like GRPO and DAPO. Furthermore, we demonstrate that NFT and GRPO are actually equivalent in strict-on-policy training, even though they originate from entirely different theoretical foundations. Our experiments and theoretical findings bridge the gap between SL and RL methods in binary-feedback learning systems.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
Mar 03, 2025While likelihood-based generative models, particularly diffusion and autoregressive models, have achieved remarkable fidelity in visual generation, the maximum likelihood estimation (MLE) objective inherently suffers from a mode-covering tendency that limits the generation quality under limited model capacity. In this work, we propose Direct Discriminative Optimization (DDO) as a unified framework that bridges likelihood-based generative training and the GAN objective to bypass this fundamental constraint. Our key insight is to parameterize a discriminator implicitly using the likelihood ratio between a learnable target model and a fixed reference model, drawing parallels with the philosophy of Direct Preference Optimization (DPO). Unlike GANs, this parameterization eliminates the need for joint training of generator and discriminator networks, allowing for direct, efficient, and effective finetuning of a well-trained model to its full potential beyond the limits of MLE. DDO can be performed iteratively in a self-play manner for progressive model refinement, with each round requiring less than 1% of pretraining epochs. Our experiments demonstrate the effectiveness of DDO by significantly advancing the previous SOTA diffusion model EDM, reducing FID scores from 1.79/1.58 to new records of 1.30/0.97 on CIFAR-10/ImageNet-64 datasets, and by consistently improving both guidance-free and CFG-enhanced FIDs of visual autoregressive models on ImageNet 256$\times$256.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
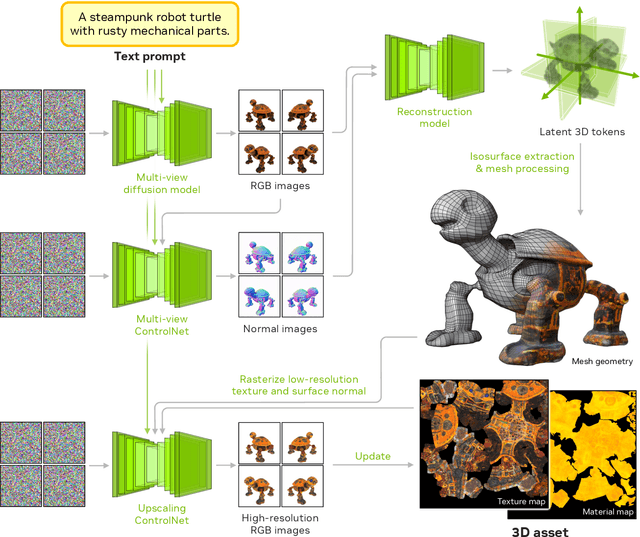
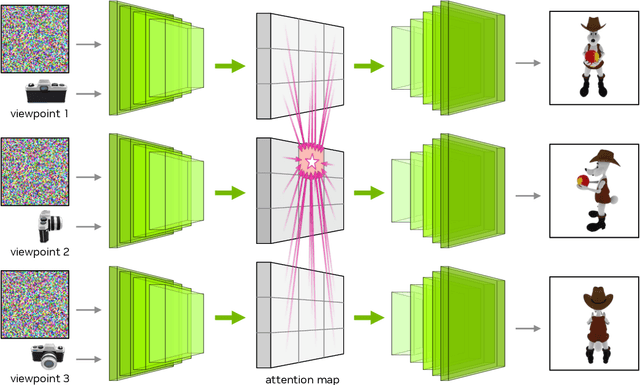

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
EdgeRunner: Auto-regressive Auto-encoder for Artistic Mesh Generation
Sep 26, 2024



Current auto-regressive mesh generation methods suffer from issues such as incompleteness, insufficient detail, and poor generalization. In this paper, we propose an Auto-regressive Auto-encoder (ArAE) model capable of generating high-quality 3D meshes with up to 4,000 faces at a spatial resolution of $512^3$. We introduce a novel mesh tokenization algorithm that efficiently compresses triangular meshes into 1D token sequences, significantly enhancing training efficiency. Furthermore, our model compresses variable-length triangular meshes into a fixed-length latent space, enabling training latent diffusion models for better generalization. Extensive experiments demonstrate the superior quality, diversity, and generalization capabilities of our model in both point cloud and image-conditioned mesh generation tasks.
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling
Sep 04, 2024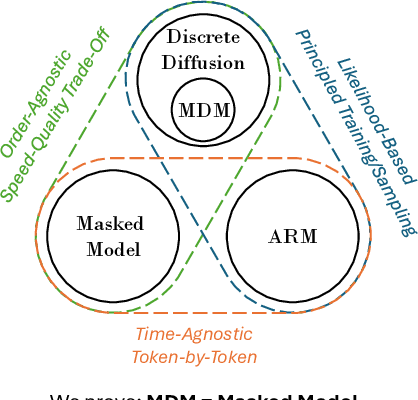

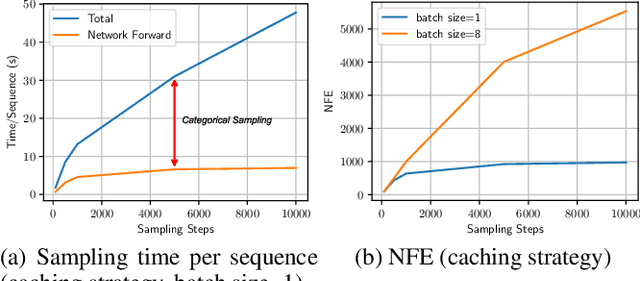

Masked diffusion models (MDMs) have emerged as a popular research topic for generative modeling of discrete data, thanks to their superior performance over other discrete diffusion models, and are rivaling the auto-regressive models (ARMs) for language modeling tasks. The recent effort in simplifying the masked diffusion framework further leads to alignment with continuous-space diffusion models and more principled training and sampling recipes. In this paper, however, we reveal that both training and sampling of MDMs are theoretically free from the time variable, arguably the key signature of diffusion models, and are instead equivalent to masked models. The connection on the sampling aspect is drawn by our proposed first-hitting sampler (FHS). Specifically, we show that the FHS is theoretically equivalent to MDMs' original generation process while significantly alleviating the time-consuming categorical sampling and achieving a 20$\times$ speedup. In addition, our investigation challenges previous claims that MDMs can surpass ARMs in generative perplexity. We identify, for the first time, an underlying numerical issue, even with the 32-bit floating-point precision, which results in inaccurate categorical sampling. We show that the numerical issue lowers the effective temperature both theoretically and empirically, leading to unfair assessments of MDMs' generation results in the previous literature.