 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniCT: Towards a Unified Slice-Volume LVLM for Comprehensive CT Analysis
Feb 18, 2026Computed Tomography (CT) is one of the most widely used and diagnostically information-dense imaging modalities, covering critical organs such as the heart, lungs, liver, and colon. Clinical interpretation relies on both slice-driven local features (e.g., sub-centimeter nodules, lesion boundaries) and volume-driven spatial representations (e.g., tumor infiltration, inter-organ anatomical relations). However, existing Large Vision-Language Models (LVLMs) remain fragmented in CT slice versus volumetric understanding: slice-driven LVLMs show strong generalization but lack cross-slice spatial consistency, while volume-driven LVLMs explicitly capture volumetric semantics but suffer from coarse granularity and poor compatibility with slice inputs. The absence of a unified modeling paradigm constitutes a major bottleneck for the clinical translation of medical LVLMs. We present OmniCT, a powerful unified slice-volume LVLM for CT scenarios, which makes three contributions: (i) Spatial Consistency Enhancement (SCE): volumetric slice composition combined with tri-axial positional embedding that introduces volumetric consistency, and an MoE hybrid projection enables efficient slice-volume adaptation; (ii) Organ-level Semantic Enhancement (OSE): segmentation and ROI localization explicitly align anatomical regions, emphasizing lesion- and organ-level semantics; (iii) MedEval-CT: the largest slice-volume CT dataset and hybrid benchmark integrates comprehensive metrics for unified evaluation. OmniCT consistently outperforms existing methods with a substantial margin across diverse clinical tasks and satisfies both micro-level detail sensitivity and macro-level spatial reasoning. More importantly, it establishes a new paradigm for cross-modal medical imaging understanding.
Low-Rank Continual Pyramid Vision Transformer: Incrementally Segment Whole-Body Organs in CT with Light-Weighted Adaptation
Oct 07, 2024Deep segmentation networks achieve high performance when trained on specific datasets. However, in clinical practice, it is often desirable that pretrained segmentation models can be dynamically extended to enable segmenting new organs without access to previous training datasets or without training from scratch. This would ensure a much more efficient model development and deployment paradigm accounting for the patient privacy and data storage issues. This clinically preferred process can be viewed as a continual semantic segmentation (CSS) problem. Previous CSS works would either experience catastrophic forgetting or lead to unaffordable memory costs as models expand. In this work, we propose a new continual whole-body organ segmentation model with light-weighted low-rank adaptation (LoRA). We first train and freeze a pyramid vision transformer (PVT) base segmentation model on the initial task, then continually add light-weighted trainable LoRA parameters to the frozen model for each new learning task. Through a holistically exploration of the architecture modification, we identify three most important layers (i.e., patch-embedding, multi-head attention and feed forward layers) that are critical in adapting to the new segmentation tasks, while retaining the majority of the pretrained parameters fixed. Our proposed model continually segments new organs without catastrophic forgetting and meanwhile maintaining a low parameter increasing rate. Continually trained and tested on four datasets covering different body parts of a total of 121 organs, results show that our model achieves high segmentation accuracy, closely reaching the PVT and nnUNet upper bounds, and significantly outperforms other regularization-based CSS methods. When comparing to the leading architecture-based CSS method, our model has a substantial lower parameter increasing rate while achieving comparable performance.
FS-MedSAM2: Exploring the Potential of SAM2 for Few-Shot Medical Image Segmentation without Fine-tuning
Sep 06, 2024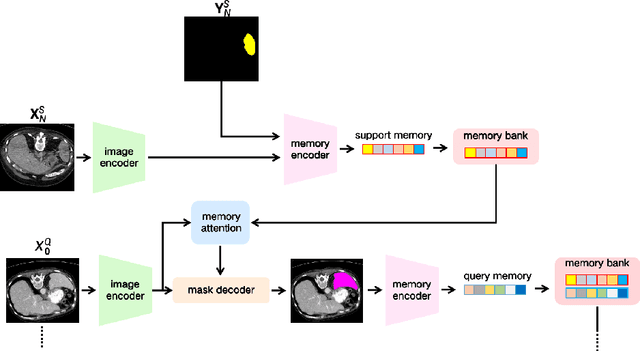

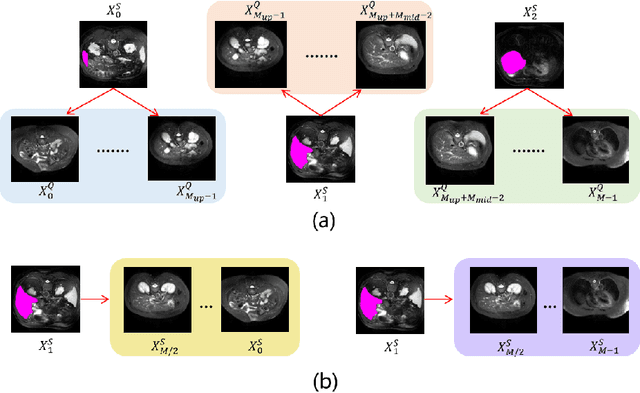

The Segment Anything Model 2 (SAM2) has recently demonstrated exceptional performance in zero-shot prompt segmentation for natural images and videos. However, it faces significant challenges when applied to medical images. Since its release, many attempts have been made to adapt SAM2's segmentation capabilities to the medical imaging domain. These efforts typically involve using a substantial amount of labeled data to fine-tune the model's weights. In this paper, we explore SAM2 from a different perspective via making the full use of its trained memory attention module and its ability of processing mask prompts. We introduce FS-MedSAM2, a simple yet effective framework that enables SAM2 to achieve superior medical image segmentation in a few-shot setting, without the need for fine-tuning. Our framework outperforms the current state-of-the-arts on two publicly available medical image datasets. The code is available at https://github.com/DeepMed-Lab-ECNU/FS_MedSAM2.
Boosting Medical Image-based Cancer Detection via Text-guided Supervision from Reports
May 23, 2024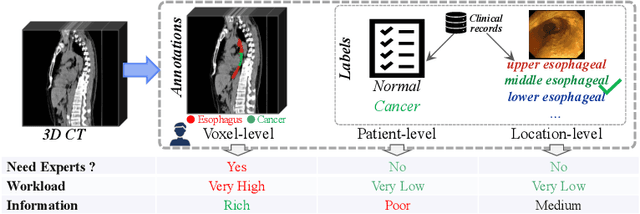
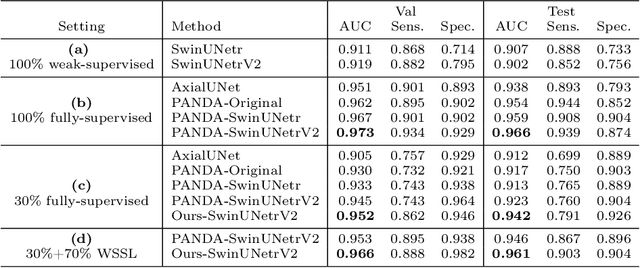
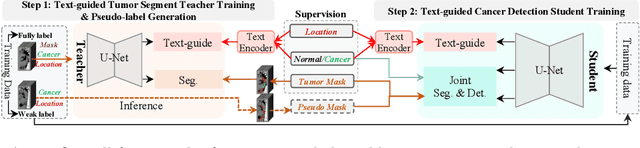
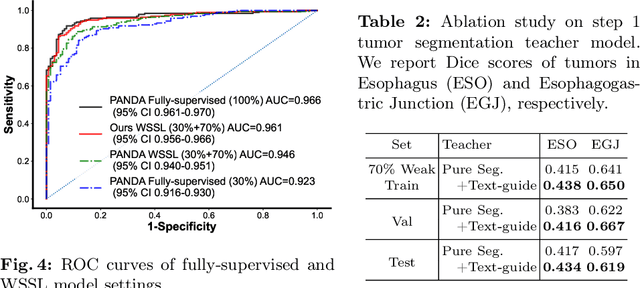
The absence of adequately sufficient expert-level tumor annotations hinders the effectiveness of supervised learning based opportunistic cancer screening on medical imaging. Clinical reports (that are rich in descriptive textual details) can offer a "free lunch'' supervision information and provide tumor location as a type of weak label to cope with screening tasks, thus saving human labeling workloads, if properly leveraged. However, predicting cancer only using such weak labels can be very changeling since tumors are usually presented in small anatomical regions compared to the whole 3D medical scans. Weakly semi-supervised learning (WSSL) utilizes a limited set of voxel-level tumor annotations and incorporates alongside a substantial number of medical images that have only off-the-shelf clinical reports, which may strike a good balance between minimizing expert annotation workload and optimizing screening efficacy. In this paper, we propose a novel text-guided learning method to achieve highly accurate cancer detection results. Through integrating diagnostic and tumor location text prompts into the text encoder of a vision-language model (VLM), optimization of weakly supervised learning can be effectively performed in the latent space of VLM, thereby enhancing the stability of training. Our approach can leverage clinical knowledge by large-scale pre-trained VLM to enhance generalization ability, and produce reliable pseudo tumor masks to improve cancer detection. Our extensive quantitative experimental results on a large-scale cancer dataset, including 1,651 unique patients, validate that our approach can reduce human annotation efforts by at least 70% while maintaining comparable cancer detection accuracy to competing fully supervised methods (AUC value 0.961 versus 0.966).
CT-GLIP: 3D Grounded Language-Image Pretraining with CT Scans and Radiology Reports for Full-Body Scenarios
Apr 29, 2024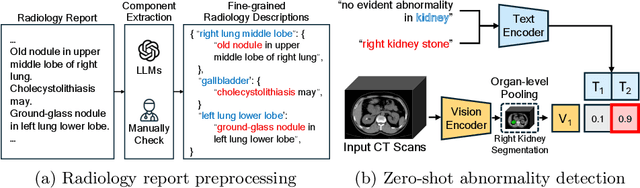
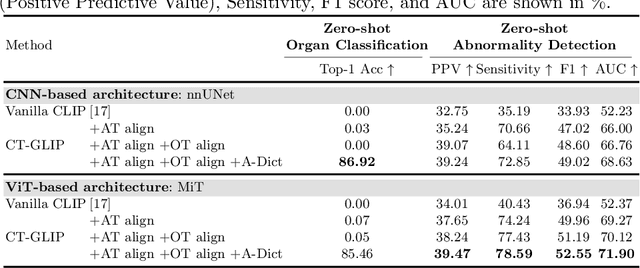
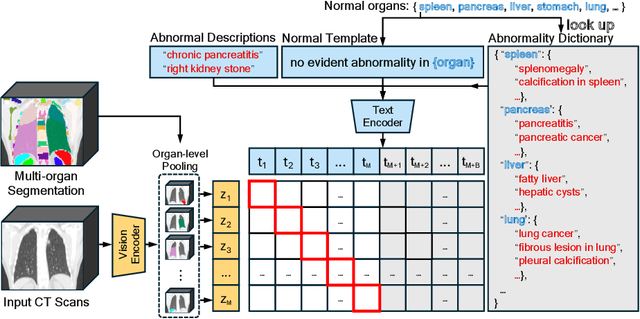
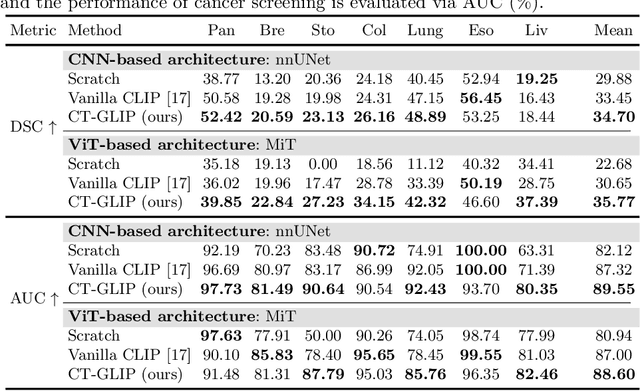
Medical Vision-Language Pretraining (Med-VLP) establishes a connection between visual content from medical images and the relevant textual descriptions. Existing Med-VLP methods primarily focus on 2D images depicting a single body part, notably chest X-rays. In this paper, we extend the scope of Med-VLP to encompass 3D images, specifically targeting full-body scenarios, by using a multimodal dataset of CT images and reports. Compared with the 2D counterpart, 3D VLP is required to effectively capture essential semantics from significantly sparser representation in 3D imaging. In this paper, we introduce CT-GLIP (Grounded Language-Image Pretraining with CT scans), a novel method that constructs organ-level image-text pairs to enhance multimodal contrastive learning, aligning grounded visual features with precise diagnostic text. Additionally, we developed an abnormality dictionary to augment contrastive learning with diverse contrastive pairs. Our method, trained on a multimodal CT dataset comprising 44,011 organ-level vision-text pairs from 17,702 patients across 104 organs, demonstrates it can identify organs and abnormalities in a zero-shot manner using natural languages. The performance of CT-GLIP is validated on a separate test set of 1,130 patients, focusing on the 16 most frequent abnormalities across 7 organs. The experimental results show our model's superior performance over the standard CLIP framework across zero-shot and fine-tuning scenarios, using both CNN and ViT architectures.
Bootstrapping Chest CT Image Understanding by Distilling Knowledge from X-ray Expert Models
Apr 07, 2024



Radiologists highly desire fully automated versatile AI for medical imaging interpretation. However, the lack of extensively annotated large-scale multi-disease datasets has hindered the achievement of this goal. In this paper, we explore the feasibility of leveraging language as a naturally high-quality supervision for chest CT imaging. In light of the limited availability of image-report pairs, we bootstrap the understanding of 3D chest CT images by distilling chest-related diagnostic knowledge from an extensively pre-trained 2D X-ray expert model. Specifically, we propose a language-guided retrieval method to match each 3D CT image with its semantically closest 2D X-ray image, and perform pair-wise and semantic relation knowledge distillation. Subsequently, we use contrastive learning to align images and reports within the same patient while distinguishing them from the other patients. However, the challenge arises when patients have similar semantic diagnoses, such as healthy patients, potentially confusing if treated as negatives. We introduce a robust contrastive learning that identifies and corrects these false negatives. We train our model with over 12,000 pairs of chest CT images and radiology reports. Extensive experiments across multiple scenarios, including zero-shot learning, report generation, and fine-tuning processes, demonstrate the model's feasibility in interpreting chest CT images.
Improved Prognostic Prediction of Pancreatic Cancer Using Multi-Phase CT by Integrating Neural Distance and Texture-Aware Transformer
Aug 01, 2023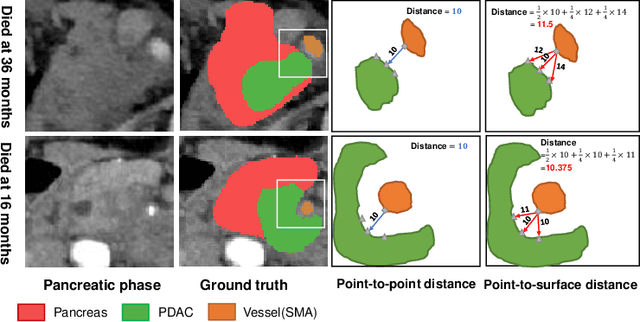
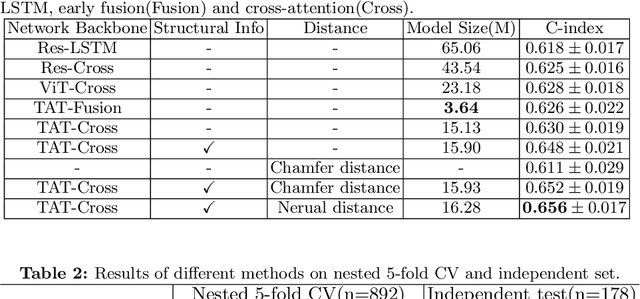
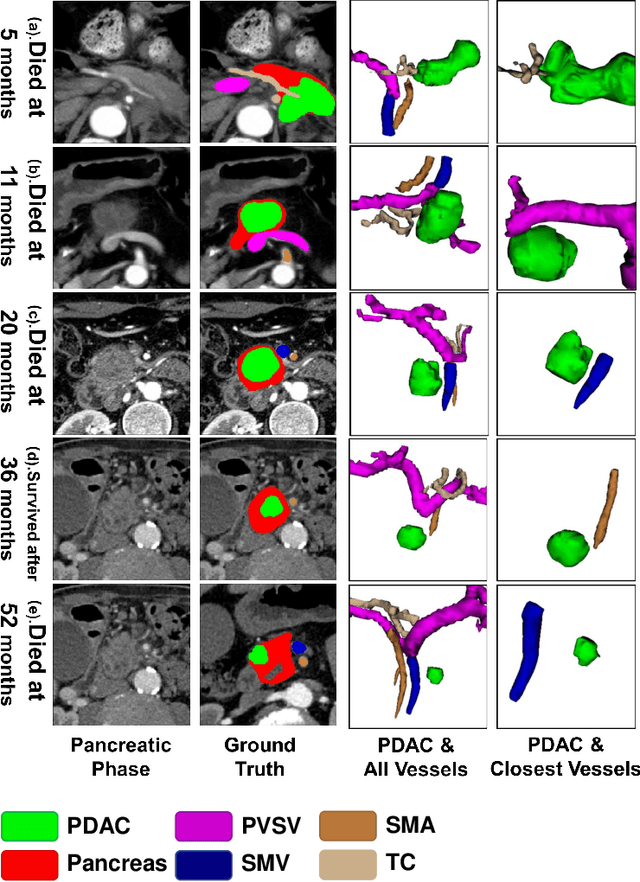
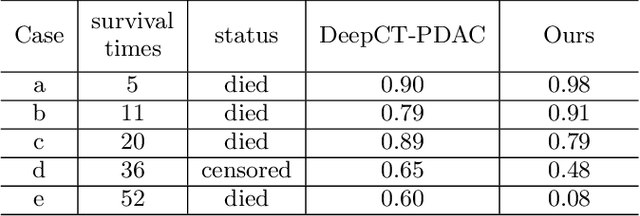
Pancreatic ductal adenocarcinoma (PDAC) is a highly lethal cancer in which the tumor-vascular involvement greatly affects the resectability and, thus, overall survival of patients. However, current prognostic prediction methods fail to explicitly and accurately investigate relationships between the tumor and nearby important vessels. This paper proposes a novel learnable neural distance that describes the precise relationship between the tumor and vessels in CT images of different patients, adopting it as a major feature for prognosis prediction. Besides, different from existing models that used CNNs or LSTMs to exploit tumor enhancement patterns on dynamic contrast-enhanced CT imaging, we improved the extraction of dynamic tumor-related texture features in multi-phase contrast-enhanced CT by fusing local and global features using CNN and transformer modules, further enhancing the features extracted across multi-phase CT images. We extensively evaluated and compared the proposed method with existing methods in the multi-center (n=4) dataset with 1,070 patients with PDAC, and statistical analysis confirmed its clinical effectiveness in the external test set consisting of three centers. The developed risk marker was the strongest predictor of overall survival among preoperative factors and it has the potential to be combined with established clinical factors to select patients at higher risk who might benefit from neoadjuvant therapy.
Liver Tumor Screening and Diagnosis in CT with Pixel-Lesion-Patient Network
Jul 17, 2023Liver tumor segmentation and classification are important tasks in computer aided diagnosis. We aim to address three problems: liver tumor screening and preliminary diagnosis in non-contrast computed tomography (CT), and differential diagnosis in dynamic contrast-enhanced CT. A novel framework named Pixel-Lesion-pAtient Network (PLAN) is proposed. It uses a mask transformer to jointly segment and classify each lesion with improved anchor queries and a foreground-enhanced sampling loss. It also has an image-wise classifier to effectively aggregate global information and predict patient-level diagnosis. A large-scale multi-phase dataset is collected containing 939 tumor patients and 810 normal subjects. 4010 tumor instances of eight types are extensively annotated. On the non-contrast tumor screening task, PLAN achieves 95% and 96% in patient-level sensitivity and specificity. On contrast-enhanced CT, our lesion-level detection precision, recall, and classification accuracy are 92%, 89%, and 86%, outperforming widely used CNN and transformers for lesion segmentation. We also conduct a reader study on a holdout set of 250 cases. PLAN is on par with a senior human radiologist, showing the clinical significance of our results.
Cluster-Induced Mask Transformers for Effective Opportunistic Gastric Cancer Screening on Non-contrast CT Scans
Jul 16, 2023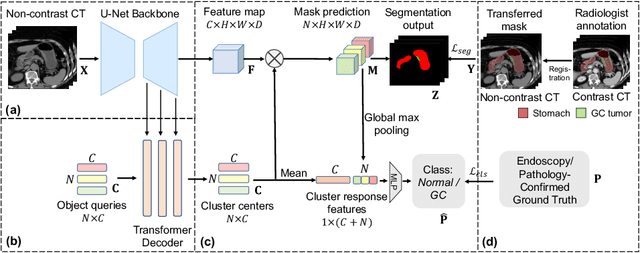
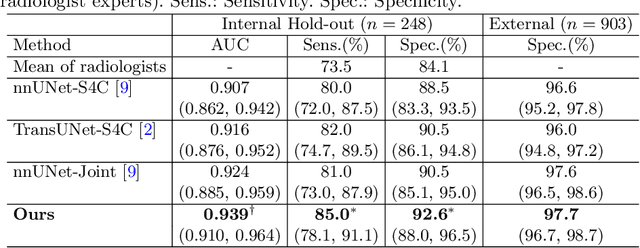
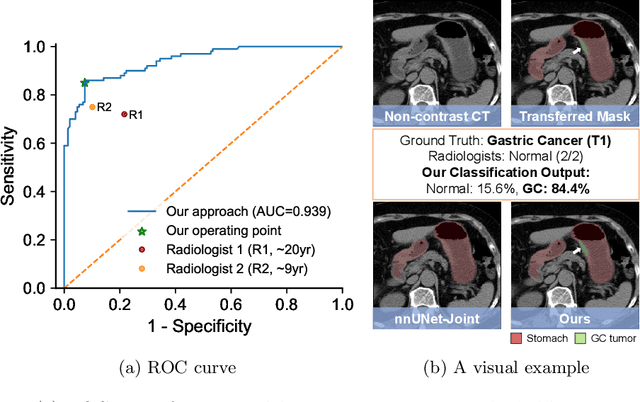
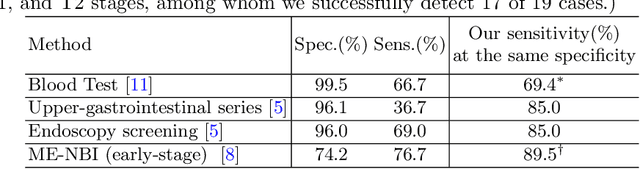
Gastric cancer is the third leading cause of cancer-related mortality worldwide, but no guideline-recommended screening test exists. Existing methods can be invasive, expensive, and lack sensitivity to identify early-stage gastric cancer. In this study, we explore the feasibility of using a deep learning approach on non-contrast CT scans for gastric cancer detection. We propose a novel cluster-induced Mask Transformer that jointly segments the tumor and classifies abnormality in a multi-task manner. Our model incorporates learnable clusters that encode the texture and shape prototypes of gastric cancer, utilizing self- and cross-attention to interact with convolutional features. In our experiments, the proposed method achieves a sensitivity of 85.0% and specificity of 92.6% for detecting gastric tumors on a hold-out test set consisting of 100 patients with cancer and 148 normal. In comparison, two radiologists have an average sensitivity of 73.5% and specificity of 84.3%. We also obtain a specificity of 97.7% on an external test set with 903 normal cases. Our approach performs comparably to established state-of-the-art gastric cancer screening tools like blood testing and endoscopy, while also being more sensitive in detecting early-stage cancer. This demonstrates the potential of our approach as a novel, non-invasive, low-cost, and accurate method for opportunistic gastric cancer screening.
Devil is in the Queries: Advancing Mask Transformers for Real-world Medical Image Segmentation and Out-of-Distribution Localization
Apr 01, 2023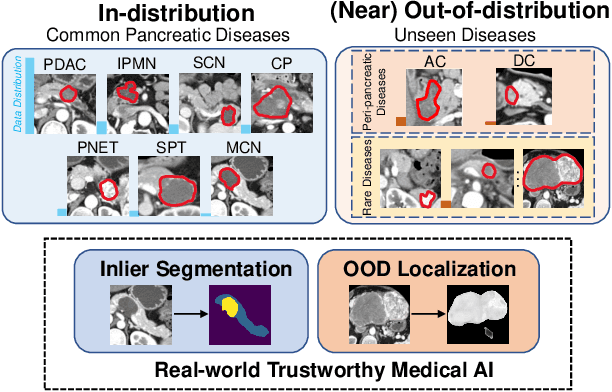
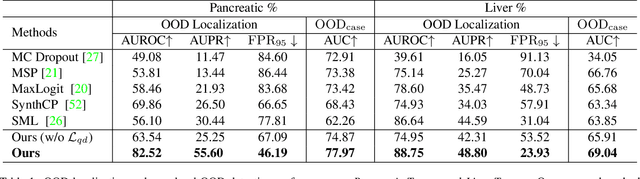
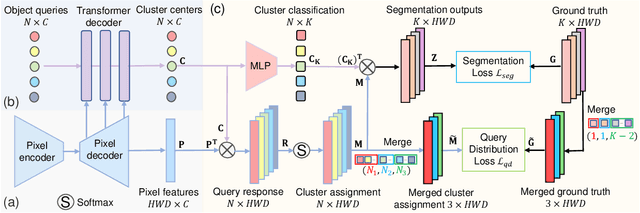

Real-world medical image segmentation has tremendous long-tailed complexity of objects, among which tail conditions correlate with relatively rare diseases and are clinically significant. A trustworthy medical AI algorithm should demonstrate its effectiveness on tail conditions to avoid clinically dangerous damage in these out-of-distribution (OOD) cases. In this paper, we adopt the concept of object queries in Mask Transformers to formulate semantic segmentation as a soft cluster assignment. The queries fit the feature-level cluster centers of inliers during training. Therefore, when performing inference on a medical image in real-world scenarios, the similarity between pixels and the queries detects and localizes OOD regions. We term this OOD localization as MaxQuery. Furthermore, the foregrounds of real-world medical images, whether OOD objects or inliers, are lesions. The difference between them is less than that between the foreground and background, possibly misleading the object queries to focus redundantly on the background. Thus, we propose a query-distribution (QD) loss to enforce clear boundaries between segmentation targets and other regions at the query level, improving the inlier segmentation and OOD indication. Our proposed framework is tested on two real-world segmentation tasks, i.e., segmentation of pancreatic and liver tumors, outperforming previous state-of-the-art algorithms by an average of 7.39% on AUROC, 14.69% on AUPR, and 13.79% on FPR95 for OOD localization. On the other hand, our framework improves the performance of inlier segmentation by an average of 5.27% DSC when compared with the leading baseline nnUNet.