 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-GLIP: 3D Grounded Language-Image Pretraining with CT Scans and Radiology Reports for Full-Body Scenarios
Paper and Code
Apr 29, 2024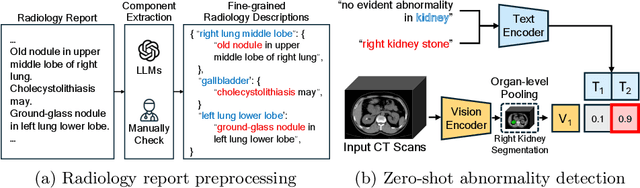
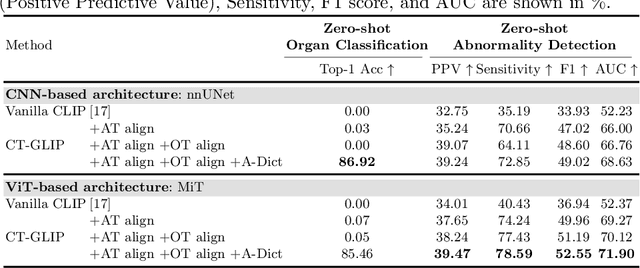
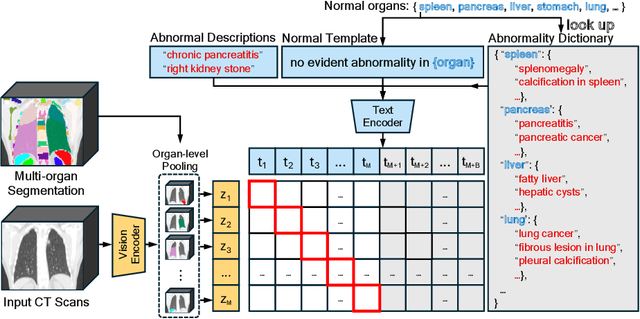
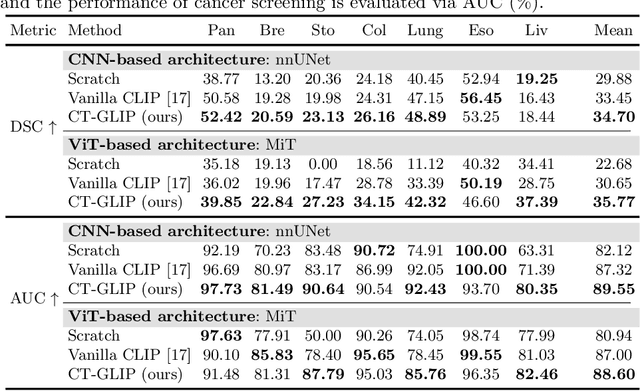
Medical Vision-Language Pretraining (Med-VLP) establishes a connection between visual content from medical images and the relevant textual descriptions. Existing Med-VLP methods primarily focus on 2D images depicting a single body part, notably chest X-rays. In this paper, we extend the scope of Med-VLP to encompass 3D images, specifically targeting full-body scenarios, by using a multimodal dataset of CT images and reports. Compared with the 2D counterpart, 3D VLP is required to effectively capture essential semantics from significantly sparser representation in 3D imaging. In this paper, we introduce CT-GLIP (Grounded Language-Image Pretraining with CT scans), a novel method that constructs organ-level image-text pairs to enhance multimodal contrastive learning, aligning grounded visual features with precise diagnostic text. Additionally, we developed an abnormality dictionary to augment contrastive learning with diverse contrastive pairs. Our method, trained on a multimodal CT dataset comprising 44,011 organ-level vision-text pairs from 17,702 patients across 104 organs, demonstrates it can identify organs and abnormalities in a zero-shot manner using natural languages. The performance of CT-GLIP is validated on a separate test set of 1,130 patients, focusing on the 16 most frequent abnormalities across 7 organs. The experimental results show our model's superior performance over the standard CLIP framework across zero-shot and fine-tuning scenarios, using both CNN and ViT architectures.