 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFS-MedSAM2: Exploring the Potential of SAM2 for Few-Shot Medical Image Segmentation without Fine-tuning
Sep 06, 2024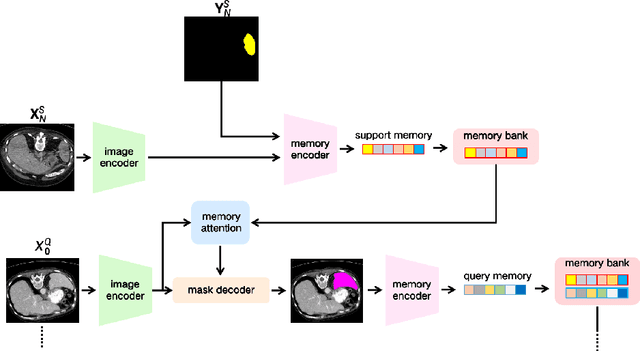


The Segment Anything Model 2 (SAM2) has recently demonstrated exceptional performance in zero-shot prompt segmentation for natural images and videos. However, it faces significant challenges when applied to medical images. Since its release, many attempts have been made to adapt SAM2's segmentation capabilities to the medical imaging domain. These efforts typically involve using a substantial amount of labeled data to fine-tune the model's weights. In this paper, we explore SAM2 from a different perspective via making the full use of its trained memory attention module and its ability of processing mask prompts. We introduce FS-MedSAM2, a simple yet effective framework that enables SAM2 to achieve superior medical image segmentation in a few-shot setting, without the need for fine-tuning. Our framework outperforms the current state-of-the-arts on two publicly available medical image datasets. The code is available at https://github.com/DeepMed-Lab-ECNU/FS_MedSAM2.
Modality-Agnostic Structural Image Representation Learning for Deformable Multi-Modality Medical Image Registration
Feb 29, 2024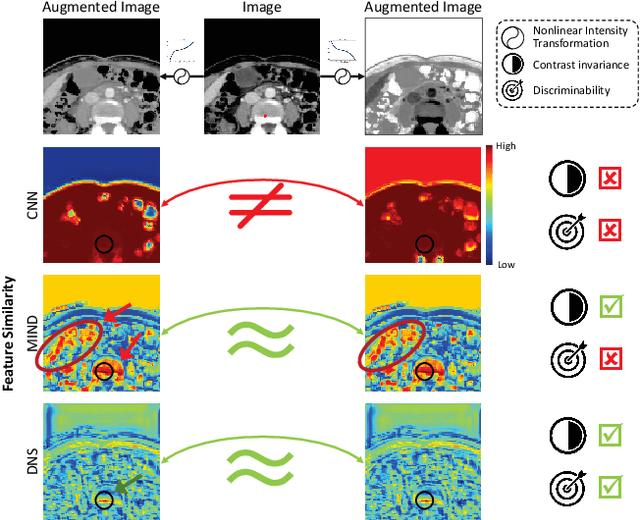
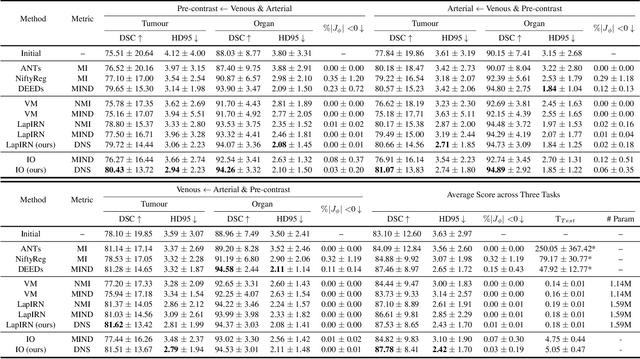
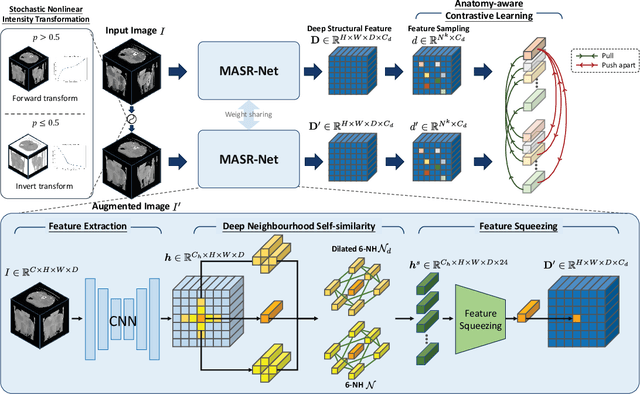
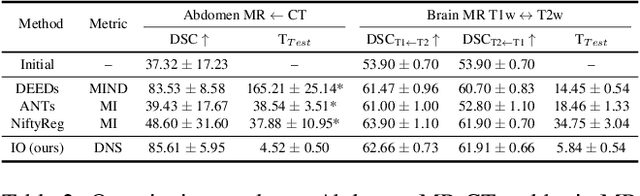
Establishing dense anatomical correspondence across distinct imaging modalities is a foundational yet challenging procedure for numerous medical image analysis studies and image-guided radiotherapy. Existing multi-modality image registration algorithms rely on statistical-based similarity measures or local structural image representations. However, the former is sensitive to locally varying noise, while the latter is not discriminative enough to cope with complex anatomical structures in multimodal scans, causing ambiguity in determining the anatomical correspondence across scans with different modalities. In this paper, we propose a modality-agnostic structural representation learning method, which leverages Deep Neighbourhood Self-similarity (DNS) and anatomy-aware contrastive learning to learn discriminative and contrast-invariance deep structural image representations (DSIR) without the need for anatomical delineations or pre-aligned training images. We evaluate our method on multiphase CT, abdomen MR-CT, and brain MR T1w-T2w registration. Comprehensive results demonstrate that our method is superior to the conventional local structural representation and statistical-based similarity measures in terms of discriminability and accuracy.
Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation
May 01, 2023In semi-supervised medical image segmentation, there exist empirical mismatch problems between labeled and unlabeled data distribution. The knowledge learned from the labeled data may be largely discarded if treating labeled and unlabeled data separately or in an inconsistent manner. We propose a straightforward method for alleviating the problem - copy-pasting labeled and unlabeled data bidirectionally, in a simple Mean Teacher architecture. The method encourages unlabeled data to learn comprehensive common semantics from the labeled data in both inward and outward directions. More importantly, the consistent learning procedure for labeled and unlabeled data can largely reduce the empirical distribution gap. In detail, we copy-paste a random crop from a labeled image (foreground) onto an unlabeled image (background) and an unlabeled image (foreground) onto a labeled image (background), respectively. The two mixed images are fed into a Student network and supervised by the mixed supervisory signals of pseudo-labels and ground-truth. We reveal that the simple mechanism of copy-pasting bidirectionally between labeled and unlabeled data is good enough and the experiments show solid gains (e.g., over 21% Dice improvement on ACDC dataset with 5% labeled data) compared with other state-of-the-arts on various semi-supervised medical image segmentation datasets. Code is available at https://github.com/DeepMed-Lab-ECNU/BCP}.
MagicNet: Semi-Supervised Multi-Organ Segmentation via Magic-Cube Partition and Recovery
Dec 29, 2022We propose a novel teacher-student model for semi-supervised multi-organ segmentation. In teacher-student model, data augmentation is usually adopted on unlabeled data to regularize the consistent training between teacher and student. We start from a key perspective that fixed relative locations and variable sizes of different organs can provide distribution information where a multi-organ CT scan is drawn. Thus, we treat the prior anatomy as a strong tool to guide the data augmentation and reduce the mismatch between labeled and unlabeled images for semi-supervised learning. More specifically, we propose a data augmentation strategy based on partition-and-recovery N$^3$ cubes cross- and within- labeled and unlabeled images. Our strategy encourages unlabeled images to learn organ semantics in relative locations from the labeled images (cross-branch) and enhances the learning ability for small organs (within-branch). For within-branch, we further propose to refine the quality of pseudo labels by blending the learned representations from small cubes to incorporate local attributes. Our method is termed as MagicNet, since it treats the CT volume as a magic-cube and $N^3$-cube partition-and-recovery process matches with the rule of playing a magic-cube. Extensive experiments on two public CT multi-organ datasets demonstrate the effectiveness of MagicNet, and noticeably outperforms state-of-the-art semi-supervised medical image segmentation approaches, with +7% DSC improvement on MACT dataset with 10% labeled images.