 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Efficient Test-Time Scaling via Hierarchical Search and Self-Verification for Discrete Diffusion Language Models
Feb 02, 2026Inference-time compute has re-emerged as a practical way to improve LLM reasoning. Most test-time scaling (TTS) algorithms rely on autoregressive decoding, which is ill-suited to discrete diffusion language models (dLLMs) due to their parallel decoding over the entire sequence. As a result, developing effective and efficient TTS methods to unlock dLLMs' full generative potential remains an underexplored challenge. To address this, we propose Prism (Pruning, Remasking, and Integrated Self-verification Method), an efficient TTS framework for dLLMs that (i) performs Hierarchical Trajectory Search (HTS) which dynamically prunes and reallocates compute in an early-to-mid denoising window, (ii) introduces Local branching with partial remasking to explore diverse implementations while preserving high-confidence tokens, and (iii) replaces external verifiers with Self-Verified Feedback (SVF) obtained via self-evaluation prompts on intermediate completions. Across four mathematical reasoning and code generation benchmarks on three dLLMs, including LLaDA 8B Instruct, Dream 7B Instruct, and LLaDA 2.0-mini, our Prism achieves a favorable performance-efficiency trade-off, matching best-of-N performance with substantially fewer function evaluations (NFE). The code is released at https://github.com/viiika/Prism.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025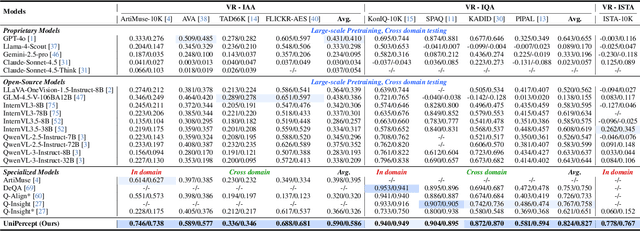

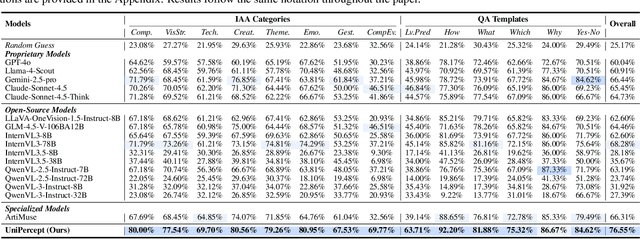
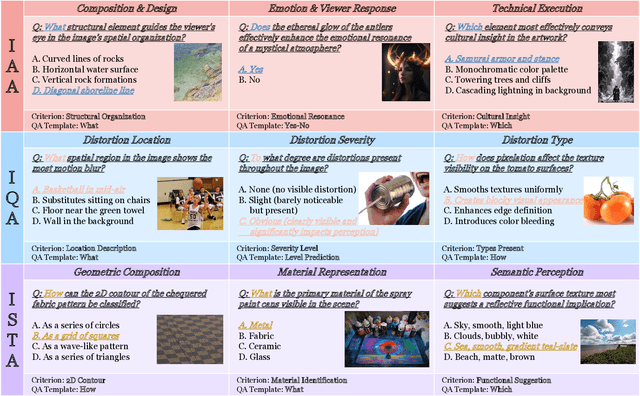
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal Large Language Models
Dec 22, 2025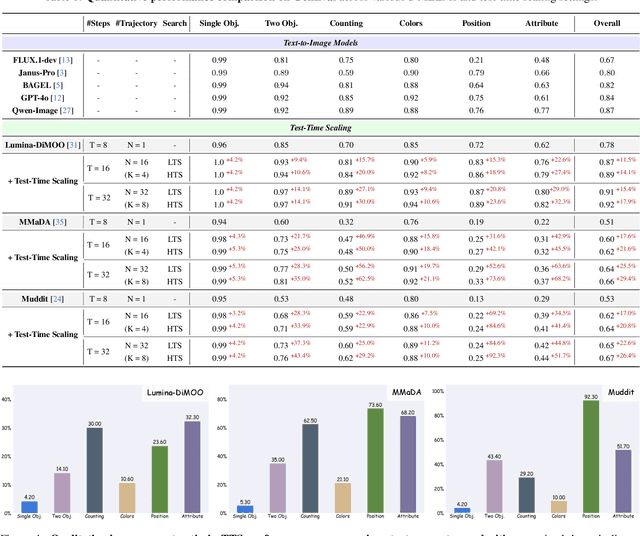

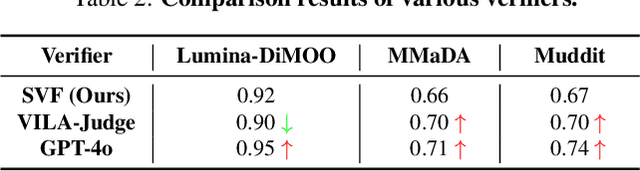
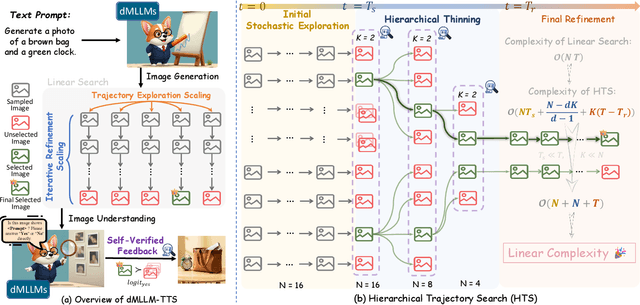
Diffusion Multi-modal Large Language Models (dMLLMs) have recently emerged as a novel architecture unifying image generation and understanding. However, developing effective and efficient Test-Time Scaling (TTS) methods to unlock their full generative potential remains an underexplored challenge. To address this, we propose dMLLM-TTS, a novel framework operating on two complementary scaling axes: (1) trajectory exploration scaling to enhance the diversity of generated hypotheses, and (2) iterative refinement scaling for stable generation. Conventional TTS approaches typically perform linear search across these two dimensions, incurring substantial computational costs of O(NT) and requiring an external verifier for best-of-N selection. To overcome these limitations, we propose two innovations. First, we design an efficient hierarchical search algorithm with O(N+T) complexity that adaptively expands and prunes sampling trajectories. Second, we introduce a self-verified feedback mechanism that leverages the dMLLMs' intrinsic image understanding capabilities to assess text-image alignment, eliminating the need for external verifier. Extensive experiments on the GenEval benchmark across three representative dMLLMs (e.g., Lumina-DiMOO, MMaDA, Muddit) show that our framework substantially improves generation quality while achieving up to 6x greater efficiency than linear search. Project page: https://github.com/Alpha-VLLM/Lumina-DiMOO.
From Masks to Worlds: A Hitchhiker's Guide to World Models
Oct 23, 2025This is not a typical survey of world models; it is a guide for those who want to build worlds. We do not aim to catalog every paper that has ever mentioned a ``world model". Instead, we follow one clear road: from early masked models that unified representation learning across modalities, to unified architectures that share a single paradigm, then to interactive generative models that close the action-perception loop, and finally to memory-augmented systems that sustain consistent worlds over time. We bypass loosely related branches to focus on the core: the generative heart, the interactive loop, and the memory system. We show that this is the most promising path towards true world models.
LayerT2V: Interactive Multi-Object Trajectory Layering for Video Generation
Aug 06, 2025Controlling object motion trajectories in Text-to-Video (T2V) generation is a challenging and relatively under-explored area, particularly in scenarios involving multiple moving objects. Most community models and datasets in the T2V domain are designed for single-object motion, limiting the performance of current generative models in multi-object tasks. Additionally, existing motion control methods in T2V either lack support for multi-object motion scenes or experience severe performance degradation when object trajectories intersect, primarily due to the semantic conflicts in colliding regions. To address these limitations, we introduce LayerT2V, the first approach for generating video by compositing background and foreground objects layer by layer. This layered generation enables flexible integration of multiple independent elements within a video, positioning each element on a distinct "layer" and thus facilitating coherent multi-object synthesis while enhancing control over the generation process. Extensive experiments demonstrate the superiority of LayerT2V in generating complex multi-object scenarios, showcasing 1.4x and 4.5x improvements in mIoU and AP50 metrics over state-of-the-art (SOTA) methods. Project page and code are available at https://kr-panghu.github.io/LayerT2V/ .
TR-PTS: Task-Relevant Parameter and Token Selection for Efficient Tuning
Jul 30, 2025Large pre-trained models achieve remarkable performance in vision tasks but are impractical for fine-tuning due to high computational and storage costs. Parameter-Efficient Fine-Tuning (PEFT) methods mitigate this issue by updating only a subset of parameters; however, most existing approaches are task-agnostic, failing to fully exploit task-specific adaptations, which leads to suboptimal efficiency and performance. To address this limitation, we propose Task-Relevant Parameter and Token Selection (TR-PTS), a task-driven framework that enhances both computational efficiency and accuracy. Specifically, we introduce Task-Relevant Parameter Selection, which utilizes the Fisher Information Matrix (FIM) to identify and fine-tune only the most informative parameters in a layer-wise manner, while keeping the remaining parameters frozen. Simultaneously, Task-Relevant Token Selection dynamically preserves the most informative tokens and merges redundant ones, reducing computational overhead. By jointly optimizing parameters and tokens, TR-PTS enables the model to concentrate on task-discriminative information. We evaluate TR-PTS on benchmark, including FGVC and VTAB-1k, where it achieves state-of-the-art performance, surpassing full fine-tuning by 3.40% and 10.35%, respectively. The code are available at https://github.com/synbol/TR-PTS.
Low-Cost Test-Time Adaptation for Robust Video Editing
Jul 29, 2025

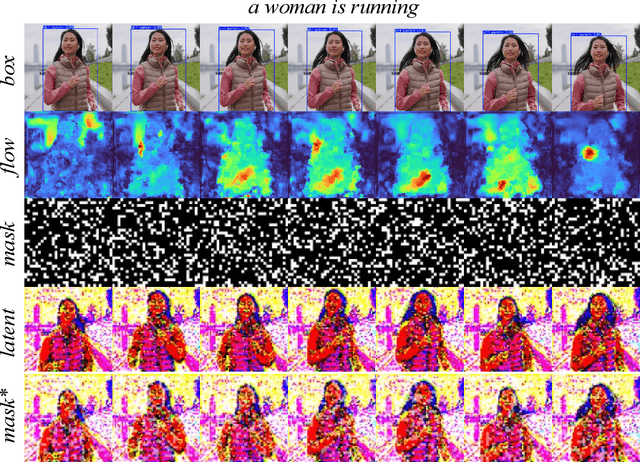

Video editing is a critical component of content creation that transforms raw footage into coherent works aligned with specific visual and narrative objectives. Existing approaches face two major challenges: temporal inconsistencies due to failure in capturing complex motion patterns, and overfitting to simple prompts arising from limitations in UNet backbone architectures. While learning-based methods can enhance editing quality, they typically demand substantial computational resources and are constrained by the scarcity of high-quality annotated data. In this paper, we present Vid-TTA, a lightweight test-time adaptation framework that personalizes optimization for each test video during inference through self-supervised auxiliary tasks. Our approach incorporates a motion-aware frame reconstruction mechanism that identifies and preserves crucial movement regions, alongside a prompt perturbation and reconstruction strategy that strengthens model robustness to diverse textual descriptions. These innovations are orchestrated by a meta-learning driven dynamic loss balancing mechanism that adaptively adjusts the optimization process based on video characteristics. Extensive experiments demonstrate that Vid-TTA significantly improves video temporal consistency and mitigates prompt overfitting while maintaining low computational overhead, offering a plug-and-play performance boost for existing video editing models.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025



We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
Resurrect Mask AutoRegressive Modeling for Efficient and Scalable Image Generation
Jul 17, 2025

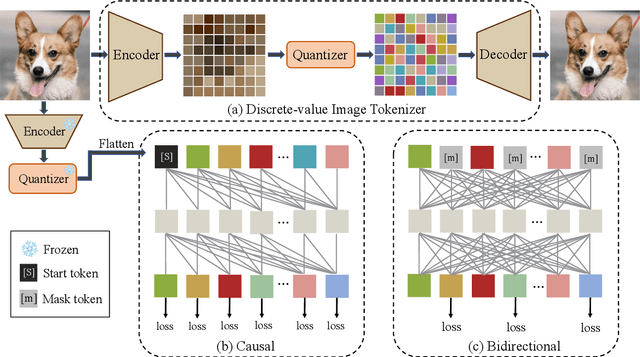

AutoRegressive (AR) models have made notable progress in image generation, with Masked AutoRegressive (MAR) models gaining attention for their efficient parallel decoding. However, MAR models have traditionally underperformed when compared to standard AR models. This study refines the MAR architecture to improve image generation quality. We begin by evaluating various image tokenizers to identify the most effective one. Subsequently, we introduce an improved Bidirectional LLaMA architecture by replacing causal attention with bidirectional attention and incorporating 2D RoPE, which together form our advanced model, MaskGIL. Scaled from 111M to 1.4B parameters, MaskGIL achieves a FID score of 3.71, matching state-of-the-art AR models in the ImageNet 256x256 benchmark, while requiring only 8 inference steps compared to the 256 steps of AR models. Furthermore, we develop a text-driven MaskGIL model with 775M parameters for generating images from text at various resolutions. Beyond image generation, MaskGIL extends to accelerate AR-based generation and enable real-time speech-to-image conversion. Our codes and models are available at https://github.com/synbol/MaskGIL.
Partitioner Guided Modal Learning Framework
Jul 15, 2025Multimodal learning benefits from multiple modal information, and each learned modal representations can be divided into uni-modal that can be learned from uni-modal training and paired-modal features that can be learned from cross-modal interaction. Building on this perspective, we propose a partitioner-guided modal learning framework, PgM, which consists of the modal partitioner, uni-modal learner, paired-modal learner, and uni-paired modal decoder. Modal partitioner segments the learned modal representation into uni-modal and paired-modal features. Modal learner incorporates two dedicated components for uni-modal and paired-modal learning. Uni-paired modal decoder reconstructs modal representation based on uni-modal and paired-modal features. PgM offers three key benefits: 1) thorough learning of uni-modal and paired-modal features, 2) flexible distribution adjustment for uni-modal and paired-modal representations to suit diverse downstream tasks, and 3) different learning rates across modalities and partitions. Extensive experiments demonstrate the effectiveness of PgM across four multimodal tasks and further highlight its transferability to existing models. Additionally, we visualize the distribution of uni-modal and paired-modal features across modalities and tasks, offering insights into their respective contributions.