 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Smoothness Doubly Robust Learning for Debiased Knowledge Tracing
May 07, 2026Knowledge Tracing (KT) is fundamental to intelligent education systems, yet relies on educational logs that are selectively observed. The non-random nature of exercise recommendations and student choices inevitably induces severe selection bias. Most existing KT methods neglect this issue, training on observed logs using standard empirical risk, which yields biased mastery estimates and accumulates errors in subsequent recommendations. To address this, we introduce a doubly robust (DR) formulation for KT that integrates a propensity model with an error imputation model, theoretically guaranteeing unbiasedness if either model is accurate. Beyond unbiasedness, in the sequential setting of KT, we identify that the estimator's performance is compromised by variance-dependent stochastic deviations that accumulate over time, thereby causing training instability and limiting performance. To mitigate this, we derive a generalization bound that explicitly characterizes the impact of estimator variance and identifies temporal smoothness as a key factor in controlling it. Building on these theoretical insights, we propose the Temporal Smoothness Doubly Robust (TSDR) framework. TSDR jointly optimizes the KT predictor and the imputation model with a smoothness regularizer, effectively reducing variance while preserving the unbiasedness guarantee of DR. Experiments on multiple real-world benchmarks demonstrate that TSDR consistently enhances various state-of-the-art KT backbones, underscoring the vital role of principled bias correction in KT.
SAM-NER: Semantic Archetype Mediation for Zero-Shot Named Entity Recognition
May 05, 2026Zero-shot Named Entity Recognition (ZS-NER) remains brittle under domain and schema shifts, where unseen label definitions often misalign with a large language model's (LLM's) intrinsic semantic organization. As a result, directly mapping entity mentions to fine-grained target labels can induce systematic semantic drift, especially when target schemas are novel or semantically overlapping. We propose \textbf{SAM-NER}, a three-stage framework based on \emph{Semantic Archetype Mediation} that stabilizes cross-domain transfer through an intermediate, domain-invariant archetype space. SAM-NER: (i) performs \emph{Entity Discovery} via cooperative extraction and consensus-based denoising to obtain high-coverage, high-fidelity entity spans; (ii) conducts \emph{Abstract Mediation} by projecting entities into a compact set of universal semantic archetypes distilled from high-level ontological abstractions; and (iii) applies \emph{Semantic Calibration} to resolve archetype-level predictions into target-domain types through constrained, definition-aligned inference with a frozen LLM. Experiments on the CrossNER benchmark show that SAM-NER consistently outperforms strong prior ZS-NER baselines in cross-domain settings. Our implementation will be open-sourced at https://github.com/DMIRLAB-Group/SAM-NER.
SERE: Structural Example Retrieval for Enhancing LLMs in Event Causality Identification
May 05, 2026Event Causality Identification (ECI) requires models to determine whether a given pair of events in a context exhibits a causal relationship. While Large Language Models (LLMs) have demonstrated strong performance across various NLP tasks, their effectiveness in ECI remains limited due to biases in causal reasoning, often leading to overprediction of causal relationships (causal hallucination). To mitigate these issues and enhance LLM performance in ECI, we propose SERE, a structural example retrieval framework that leverages LLMs' few-shot learning capabilities. SERE introduces an innovative retrieval mechanism based on three structural concepts: (i) Conceptual Path Metric, which measures the conceptual relationship between events using edit distance in ConceptNet; (ii) Syntactic Metric, which quantifies structural similarity through tree edit distance on syntactic trees; and (iii) Causal Pattern Filtering, which filters examples based on predefined causal structures using LLMs. By integrating these structural retrieval strategies, SERE selects more relevant examples to guide LLMs in causal reasoning, mitigating bias and improving accuracy in ECI tasks. Extensive experiments on multiple ECI datasets validate the effectiveness of SERE. The source code is publicly available at https://github.com/DMIRLAB-Group/SERE.
$\mathcal{S}^2$IT: Stepwise Syntax Integration Tuning for Large Language Models in Aspect Sentiment Quad Prediction
Apr 25, 2026Aspect Sentiment Quad Prediction (ASQP) has seen significant advancements, largely driven by the powerful semantic understanding and generative capabilities of large language models (LLMs). However, while syntactic structure information has been proven effective in previous extractive paradigms, it remains underutilized in the generative paradigm of LLMs due to their limited reasoning capabilities. In this paper, we propose S^2IT, a novel Stepwise Syntax Integration Tuning framework that progressively integrates syntactic structure knowledge into LLMs through a multi-step tuning process. The training process is divided into three steps. S^2IT decomposes the quadruple generation task into two stages: 1) Global Syntax-guided Extraction and 2) Local Syntax-guided Classification, integrating both global and local syntactic structure information. Finally, Fine-grained Structural Tuning enhances the model's understanding of syntactic structures through the prediction of element links and node classification. Experiments demonstrate that S^2IT significantly improves state-of-the-art performance across multiple datasets. Our implementation will be open-sourced at https://github.com/DMIRLAB-Group/S2IT.
Hierarchical Action Learning for Weakly-Supervised Action Segmentation
Feb 27, 2026Humans perceive actions through key transitions that structure actions across multiple abstraction levels, whereas machines, relying on visual features, tend to over-segment. This highlights the difficulty of enabling hierarchical reasoning in video understanding. Interestingly, we observe that lower-level visual and high-level action latent variables evolve at different rates, with low-level visual variables changing rapidly, while high-level action variables evolve more slowly, making them easier to identify. Building on this insight, we propose the Hierarchical Action Learning (\textbf{HAL}) model for weakly-supervised action segmentation. Our approach introduces a hierarchical causal data generation process, where high-level latent action governs the dynamics of low-level visual features. To model these varying timescales effectively, we introduce deterministic processes to align these latent variables over time. The \textbf{HAL} model employs a hierarchical pyramid transformer to capture both visual features and latent variables, and a sparse transition constraint is applied to enforce the slower dynamics of high-level action variables. This mechanism enhances the identification of these latent variables over time. Under mild assumptions, we prove that these latent action variables are strictly identifiable. Experimental results on several benchmarks show that the \textbf{HAL} model significantly outperforms existing methods for weakly-supervised action segmentation, confirming its practical effectiveness in real-world applications.
CausalAgent: A Conversational Multi-Agent System for End-to-End Causal Inference
Feb 12, 2026Causal inference holds immense value in fields such as healthcare, economics, and social sciences. However, traditional causal analysis workflows impose significant technical barriers, requiring researchers to possess dual backgrounds in statistics and computer science, while manually selecting algorithms, handling data quality issues, and interpreting complex results. To address these challenges, we propose CausalAgent, a conversational multi-agent system for end-to-end causal inference. The system innovatively integrates Multi-Agent Systems (MAS), Retrieval-Augmented Generation (RAG), and the Model Context Protocol (MCP) to achieve automation from data cleaning and causal structure learning to bias correction and report generation through natural language interaction. Users need only upload a dataset and pose questions in natural language to receive a rigorous, interactive analysis report. As a novel user-centered human-AI collaboration paradigm, CausalAgent explicitly models the analysis workflow. By leveraging interactive visualizations, it significantly lowers the barrier to entry for causal analysis while ensuring the rigor and interpretability of the process.
Rethinking Zero-Shot Time Series Classification: From Task-specific Classifiers to In-Context Inference
Jan 31, 2026The zero-shot evaluation of time series foundation models (TSFMs) for classification typically uses a frozen encoder followed by a task-specific classifier. However, this practice violates the training-free premise of zero-shot deployment and introduces evaluation bias due to classifier-dependent training choices. To address this issue, we propose TIC-FM, an in-context learning framework that treats the labeled training set as context and predicts labels for all test instances in a single forward pass, without parameter updates. TIC-FM pairs a time series encoder and a lightweight projection adapter with a split-masked latent memory Transformer. We further provide theoretical justification that in-context inference can subsume trained classifiers and can emulate gradient-based classifier training within a single forward pass. Experiments on 128 UCR datasets show strong accuracy, with consistent gains in the extreme low-label situation, highlighting training-free transfer
What Gets Activated: Uncovering Domain and Driver Experts in MoE Language Models
Jan 15, 2026Most interpretability work focuses on layer- or neuron-level mechanisms in Transformers, leaving expert-level behavior in MoE LLMs underexplored. Motivated by functional specialization in the human brain, we analyze expert activation by distinguishing domain and driver experts. In this work, we study expert activation in MoE models across three public domains and address two key questions: (1) which experts are activated, and whether certain expert types exhibit consistent activation patterns; and (2) how tokens are associated with and trigger the activation of specific experts. To answer these questions, we introduce entropy-based and causal-effect metrics to assess whether an expert is strongly favored for a particular domain, and how strongly expert activation contributes causally to the model's output, thus identify domain and driver experts, respectively. Furthermore, we explore how individual tokens are associated with the activation of specific experts. Our analysis reveals that (1) Among the activated experts, some show clear domain preferences, while others exert strong causal influence on model performance, underscoring their decisive roles. (2) tokens occurring earlier in a sentence are more likely to trigger the driver experts, and (3) adjusting the weights of domain and driver experts leads to significant performance gains across all three models and domains. These findings shed light on the internal mechanisms of MoE models and enhance their interpretability.
ENTRA: Entropy-Based Redundancy Avoidance in Large Language Model Reasoning
Jan 12, 2026Large Reasoning Models (LRMs) often suffer from overthinking, generating unnecessarily long reasoning chains even for simple tasks. This leads to substantial computational overhead with limited performance gain, primarily due to redundant verification and repetitive generation. While prior work typically constrains output length or optimizes correctness, such coarse supervision fails to guide models toward concise yet accurate inference. In this paper, we propose ENTRA, an entropy-based training framework that suppresses redundant reasoning while preserving performance. ENTRA first estimates the token-level importance using a lightweight Bidirectional Importance Estimation (BIE) method, which accounts for both prediction confidence and forward influence. It then computes a redundancy reward based on the entropy of low-importance tokens, normalized by its theoretical upper bound, and optimizes this reward via reinforcement learning. Experiments on mathematical reasoning benchmarks demonstrate that ENTRA reduces output length by 37% to 53% with no loss-and in some cases, gains-in accuracy. Our approach offers a principled and efficient solution to reduce overthinking in LRMs, and provides a generalizable path toward redundancy-aware reasoning optimization.
Temporal Latent Variable Structural Causal Model for Causal Discovery under External Interferences
Nov 13, 2025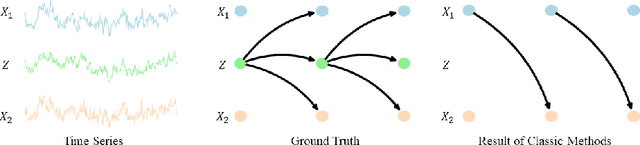

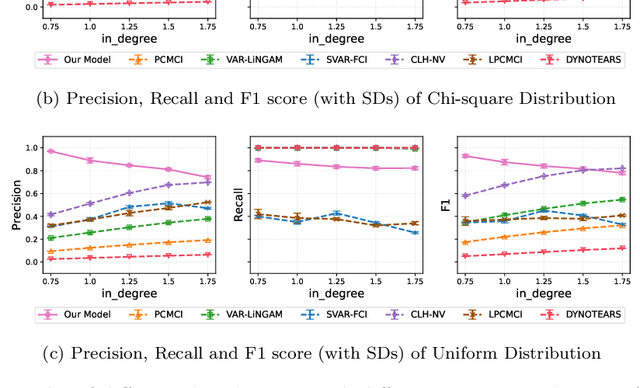
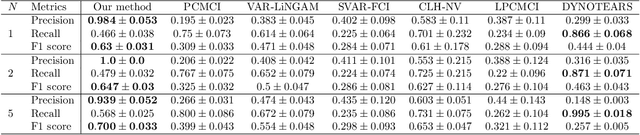
Inferring causal relationships from observed data is an important task, yet it becomes challenging when the data is subject to various external interferences. Most of these interferences are the additional effects of external factors on observed variables. Since these external factors are often unknown, we introduce latent variables to represent these unobserved factors that affect the observed data. Specifically, to capture the causal strength and adjacency information, we propose a new temporal latent variable structural causal model, incorporating causal strength and adjacency coefficients that represent the causal relationships between variables. Considering that expert knowledge can provide information about unknown interferences in certain scenarios, we develop a method that facilitates the incorporation of prior knowledge into parameter learning based on Variational Inference, to guide the model estimation. Experimental results demonstrate the stability and accuracy of our proposed method.