 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Smoothness Doubly Robust Learning for Debiased Knowledge Tracing
May 07, 2026Knowledge Tracing (KT) is fundamental to intelligent education systems, yet relies on educational logs that are selectively observed. The non-random nature of exercise recommendations and student choices inevitably induces severe selection bias. Most existing KT methods neglect this issue, training on observed logs using standard empirical risk, which yields biased mastery estimates and accumulates errors in subsequent recommendations. To address this, we introduce a doubly robust (DR) formulation for KT that integrates a propensity model with an error imputation model, theoretically guaranteeing unbiasedness if either model is accurate. Beyond unbiasedness, in the sequential setting of KT, we identify that the estimator's performance is compromised by variance-dependent stochastic deviations that accumulate over time, thereby causing training instability and limiting performance. To mitigate this, we derive a generalization bound that explicitly characterizes the impact of estimator variance and identifies temporal smoothness as a key factor in controlling it. Building on these theoretical insights, we propose the Temporal Smoothness Doubly Robust (TSDR) framework. TSDR jointly optimizes the KT predictor and the imputation model with a smoothness regularizer, effectively reducing variance while preserving the unbiasedness guarantee of DR. Experiments on multiple real-world benchmarks demonstrate that TSDR consistently enhances various state-of-the-art KT backbones, underscoring the vital role of principled bias correction in KT.
CustomTex: High-fidelity Indoor Scene Texturing via Multi-Reference Customization
Mar 19, 2026The creation of high-fidelity, customizable 3D indoor scene textures remains a significant challenge. While text-driven methods offer flexibility, they lack the precision for fine-grained, instance-level control, and often produce textures with insufficient quality, artifacts, and baked-in shading. To overcome these limitations, we introduce CustomTex, a novel framework for instance-level, high-fidelity scene texturing driven by reference images. CustomTex takes an untextured 3D scene and a set of reference images specifying the desired appearance for each object instance, and generates a unified, high-resolution texture map. The core of our method is a dual-distillation approach that separates semantic control from pixel-level enhancement. We employ semantic-level distillation, equipped with an instance cross-attention, to ensure semantic plausibility and ``reference-instance'' alignment, and pixel-level distillation to enforce high visual fidelity. Both are unified within a Variational Score Distillation (VSD) optimization framework. Experiments demonstrate that CustomTex achieves precise instance-level consistency with reference images and produces textures with superior sharpness, reduced artifacts, and minimal baked-in shading compared to state-of-the-art methods. Our work establishes a more direct and user-friendly path to high-quality, customizable 3D scene appearance editing.
Hierarchical Action Learning for Weakly-Supervised Action Segmentation
Feb 27, 2026Humans perceive actions through key transitions that structure actions across multiple abstraction levels, whereas machines, relying on visual features, tend to over-segment. This highlights the difficulty of enabling hierarchical reasoning in video understanding. Interestingly, we observe that lower-level visual and high-level action latent variables evolve at different rates, with low-level visual variables changing rapidly, while high-level action variables evolve more slowly, making them easier to identify. Building on this insight, we propose the Hierarchical Action Learning (\textbf{HAL}) model for weakly-supervised action segmentation. Our approach introduces a hierarchical causal data generation process, where high-level latent action governs the dynamics of low-level visual features. To model these varying timescales effectively, we introduce deterministic processes to align these latent variables over time. The \textbf{HAL} model employs a hierarchical pyramid transformer to capture both visual features and latent variables, and a sparse transition constraint is applied to enforce the slower dynamics of high-level action variables. This mechanism enhances the identification of these latent variables over time. Under mild assumptions, we prove that these latent action variables are strictly identifiable. Experimental results on several benchmarks show that the \textbf{HAL} model significantly outperforms existing methods for weakly-supervised action segmentation, confirming its practical effectiveness in real-world applications.
Long-Term Individual Causal Effect Estimation via Identifiable Latent Representation Learning
May 08, 2025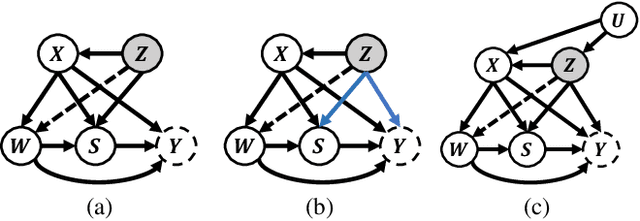
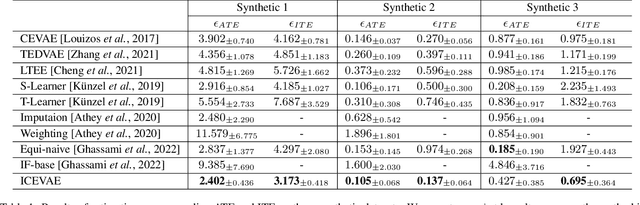
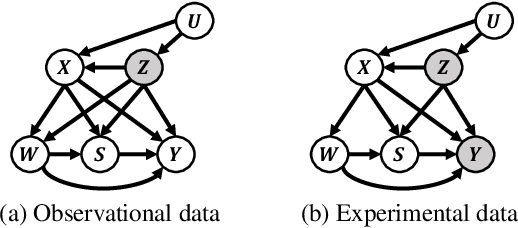
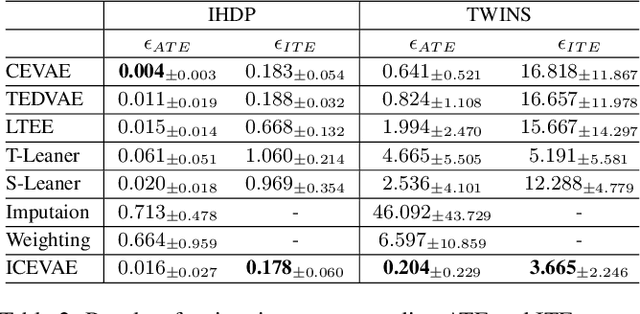
Estimating long-term causal effects by combining long-term observational and short-term experimental data is a crucial but challenging problem in many real-world scenarios. In existing methods, several ideal assumptions, e.g. latent unconfoundedness assumption or additive equi-confounding bias assumption, are proposed to address the latent confounder problem raised by the observational data. However, in real-world applications, these assumptions are typically violated which limits their practical effectiveness. In this paper, we tackle the problem of estimating the long-term individual causal effects without the aforementioned assumptions. Specifically, we propose to utilize the natural heterogeneity of data, such as data from multiple sources, to identify latent confounders, thereby significantly avoiding reliance on idealized assumptions. Practically, we devise a latent representation learning-based estimator of long-term causal effects. Theoretically, we establish the identifiability of latent confounders, with which we further achieve long-term effect identification. Extensive experimental studies, conducted on multiple synthetic and semi-synthetic datasets, demonstrate the effectiveness of our proposed method.
Causal Effect Estimation under Networked Interference without Networked Unconfoundedness Assumption
Feb 27, 2025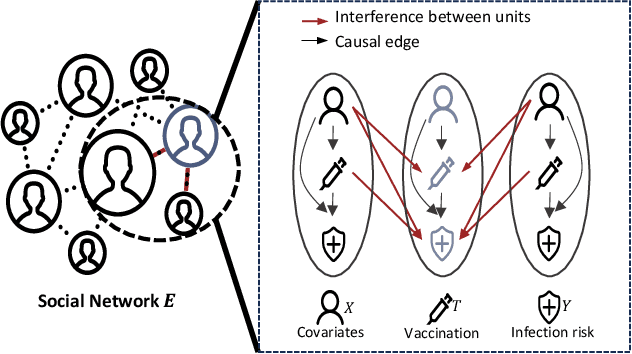
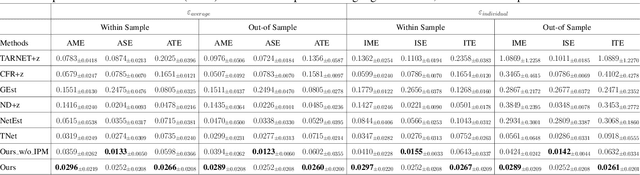
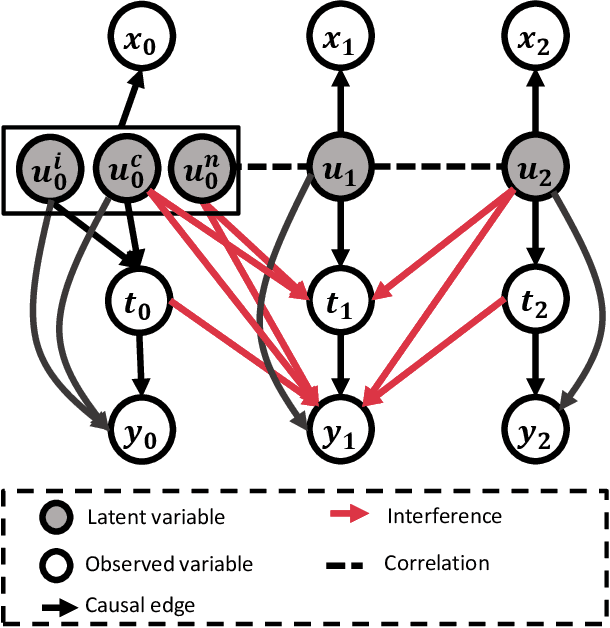
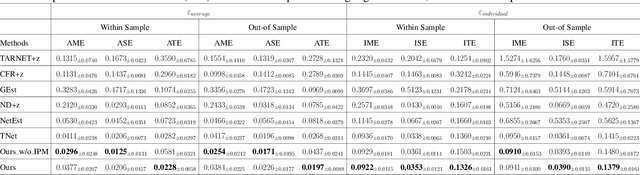
Estimating causal effects under networked interference is a crucial yet challenging problem. Existing methods based on observational data mainly rely on the networked unconfoundedness assumption, which guarantees the identification of networked effects. However, the networked unconfoundedness assumption is usually violated due to the latent confounders in observational data, hindering the identification of networked effects. Interestingly, in such networked settings, interactions between units provide valuable information for recovering latent confounders. In this paper, we identify three types of latent confounders in networked inference that hinder identification: those affecting only the individual, those affecting only neighbors, and those influencing both. Specifically, we devise a networked effect estimator based on identifiable representation learning techniques. Theoretically, we establish the identifiability of all latent confounders, and leveraging the identified latent confounders, we provide the networked effect identification result. Extensive experiments validate our theoretical results and demonstrate the effectiveness of the proposed method.
Nonparametric Heterogeneous Long-term Causal Effect Estimation via Data Combination
Feb 26, 2025Long-term causal inference has drawn increasing attention in many scientific domains. Existing methods mainly focus on estimating average long-term causal effects by combining long-term observational data and short-term experimental data. However, it is still understudied how to robustly and effectively estimate heterogeneous long-term causal effects, significantly limiting practical applications. In this paper, we propose several two-stage style nonparametric estimators for heterogeneous long-term causal effect estimation, including propensity-based, regression-based, and multiple robust estimators. We conduct a comprehensive theoretical analysis of their asymptotic properties under mild assumptions, with the ultimate goal of building a better understanding of the conditions under which some estimators can be expected to perform better. Extensive experiments across several semi-synthetic and real-world datasets validate the theoretical results and demonstrate the effectiveness of the proposed estimators.
Long-term Causal Inference via Modeling Sequential Latent Confounding
Feb 26, 2025Long-term causal inference is an important but challenging problem across various scientific domains. To solve the latent confounding problem in long-term observational studies, existing methods leverage short-term experimental data. Ghassami et al. propose an approach based on the Conditional Additive Equi-Confounding Bias (CAECB) assumption, which asserts that the confounding bias in the short-term outcome is equal to that in the long-term outcome, so that the long-term confounding bias and the causal effects can be identified. While effective in certain cases, this assumption is limited to scenarios with a one-dimensional short-term outcome. In this paper, we introduce a novel assumption that extends the CAECB assumption to accommodate temporal short-term outcomes. Our proposed assumption states a functional relationship between sequential confounding biases across temporal short-term outcomes, under which we theoretically establish the identification of long-term causal effects. Based on the identification result, we develop an estimator and conduct a theoretical analysis of its asymptotic properties. Extensive experiments validate our theoretical results and demonstrate the effectiveness of the proposed method.
Estimating Long-term Heterogeneous Dose-response Curve: Generalization Bound Leveraging Optimal Transport Weights
Jun 27, 2024



Long-term causal effect estimation is a significant but challenging problem in many applications. Existing methods rely on ideal assumptions to estimate long-term average effects, e.g., no unobserved confounders or a binary treatment,while in numerous real-world applications, these assumptions could be violated and average effects are unable to provide individual-level suggestions.In this paper,we address a more general problem of estimating the long-term heterogeneous dose-response curve (HDRC) while accounting for unobserved confounders. Specifically, to remove unobserved confounding in observational data, we introduce an optimal transport weighting framework to align the observational data to the experimental data with theoretical guarantees. Furthermore,to accurately predict the heterogeneous effects of continuous treatment, we establish a generalization bound on counterfactual prediction error by leveraging the reweighted distribution induced by optimal transport. Finally, we develop an HDRC estimator building upon the above theoretical foundations. Extensive experimental studies conducted on multiple synthetic and semi-synthetic datasets demonstrate the effectiveness of our proposed method.
From Orthogonality to Dependency: Learning Disentangled Representation for Multi-Modal Time-Series Sensing Signals
May 25, 2024



Existing methods for multi-modal time series representation learning aim to disentangle the modality-shared and modality-specific latent variables. Although achieving notable performances on downstream tasks, they usually assume an orthogonal latent space. However, the modality-specific and modality-shared latent variables might be dependent on real-world scenarios. Therefore, we propose a general generation process, where the modality-shared and modality-specific latent variables are dependent, and further develop a \textbf{M}ulti-mod\textbf{A}l \textbf{TE}mporal Disentanglement (\textbf{MATE}) model. Specifically, our \textbf{MATE} model is built on a temporally variational inference architecture with the modality-shared and modality-specific prior networks for the disentanglement of latent variables. Furthermore, we establish identifiability results to show that the extracted representation is disentangled. More specifically, we first achieve the subspace identifiability for modality-shared and modality-specific latent variables by leveraging the pairing of multi-modal data. Then we establish the component-wise identifiability of modality-specific latent variables by employing sufficient changes of historical latent variables. Extensive experimental studies on multi-modal sensors, human activity recognition, and healthcare datasets show a general improvement in different downstream tasks, highlighting the effectiveness of our method in real-world scenarios.
Doubly Robust Causal Effect Estimation under Networked Interference via Targeted Learning
May 06, 2024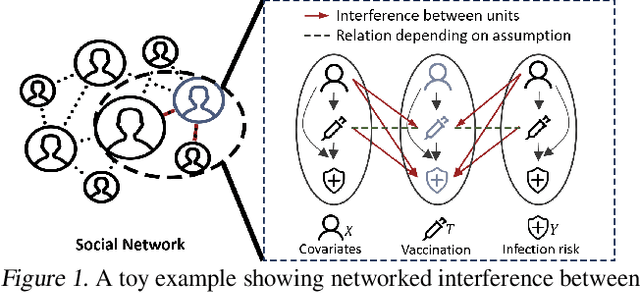
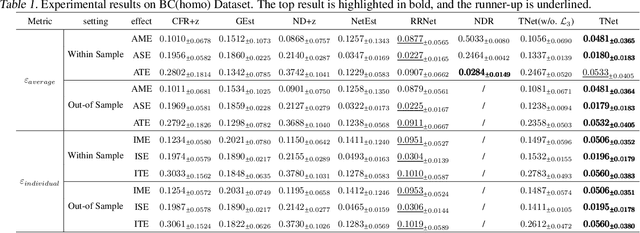
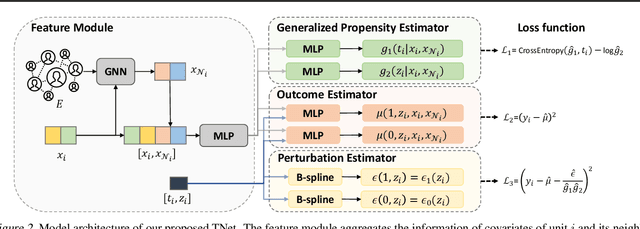
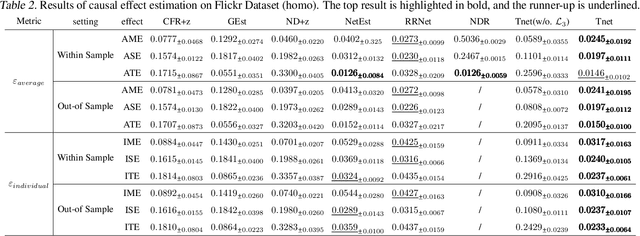
Causal effect estimation under networked interference is an important but challenging problem. Available parametric methods are limited in their model space, while previous semiparametric methods, e.g., leveraging neural networks to fit only one single nuisance function, may still encounter misspecification problems under networked interference without appropriate assumptions on the data generation process. To mitigate bias stemming from misspecification, we propose a novel doubly robust causal effect estimator under networked interference, by adapting the targeted learning technique to the training of neural networks. Specifically, we generalize the targeted learning technique into the networked interference setting and establish the condition under which an estimator achieves double robustness. Based on the condition, we devise an end-to-end causal effect estimator by transforming the identified theoretical condition into a targeted loss. Moreover, we provide a theoretical analysis of our designed estimator, revealing a faster convergence rate compared to a single nuisance model. Extensive experimental results on two real-world networks with semisynthetic data demonstrate the effectiveness of our proposed estimators.