 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Heterogeneous and Adaptive Segmentation from Multi-Source and Multi-Phase CT Imaging Data: A Study on Pathological Liver and Lesion Segmentation
Jun 10, 2020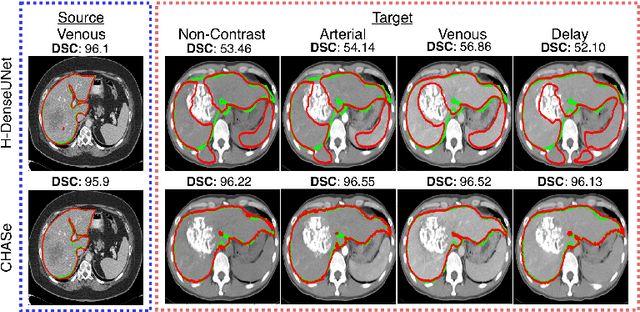
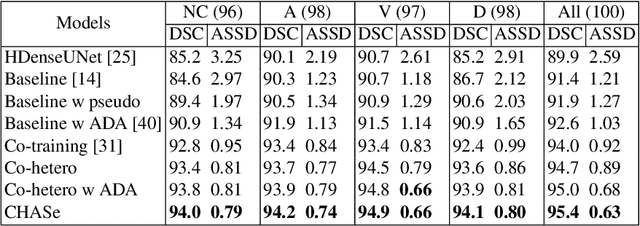
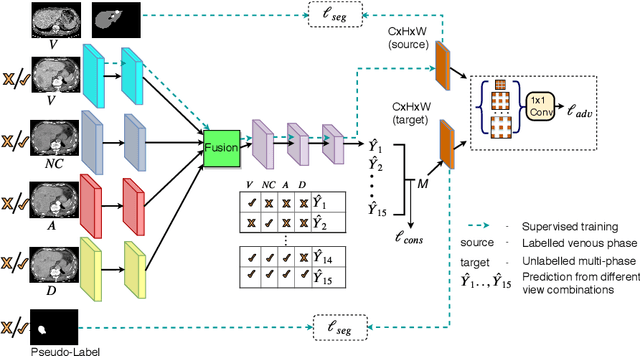
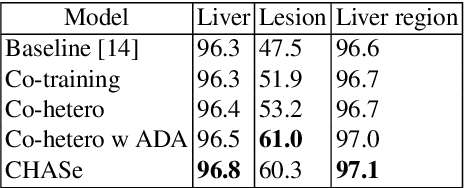
In medical imaging, organ/pathology segmentation models trained on current publicly available and fully-annotated datasets usually do not well-represent the heterogeneous modalities, phases, pathologies, and clinical scenarios encountered in real environments. On the other hand, there are tremendous amounts of unlabelled patient imaging scans stored by many modern clinical centers. In this work, we present a novel segmentation strategy, co-heterogenous and adaptive segmentation (CHASe), which only requires a small labeled cohort of single phase imaging data to adapt to any unlabeled cohort of heterogenous multi-phase data with possibly new clinical scenarios and pathologies. To do this, we propose a versatile framework that fuses appearance based semi-supervision, mask based adversarial domain adaptation, and pseudo-labeling. We also introduce co-heterogeneous training, which is a novel integration of co-training and hetero modality learning. We have evaluated CHASe using a clinically comprehensive and challenging dataset of multi-phase computed tomography (CT) imaging studies (1147 patients and 4577 3D volumes). Compared to previous state-of-the-art baselines, CHASe can further improve pathological liver mask Dice-Sorensen coefficients by ranges of $4.2\% \sim 9.4\%$, depending on the phase combinations: e.g., from $84.6\%$ to $94.0\%$ on non-contrast CTs.
Detecting Scatteredly-Distributed, Small, andCritically Important Objects in 3D OncologyImaging via Decision Stratification
May 27, 2020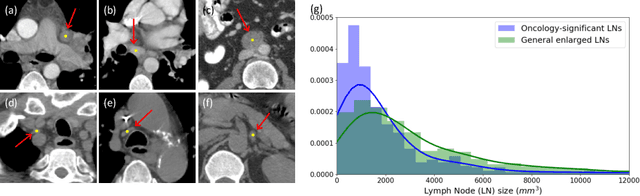
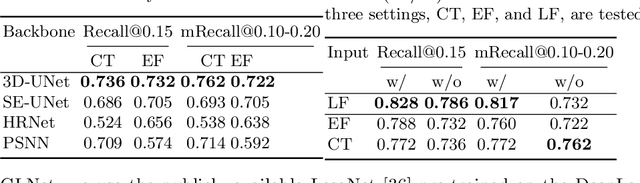
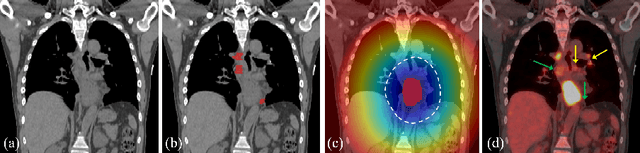
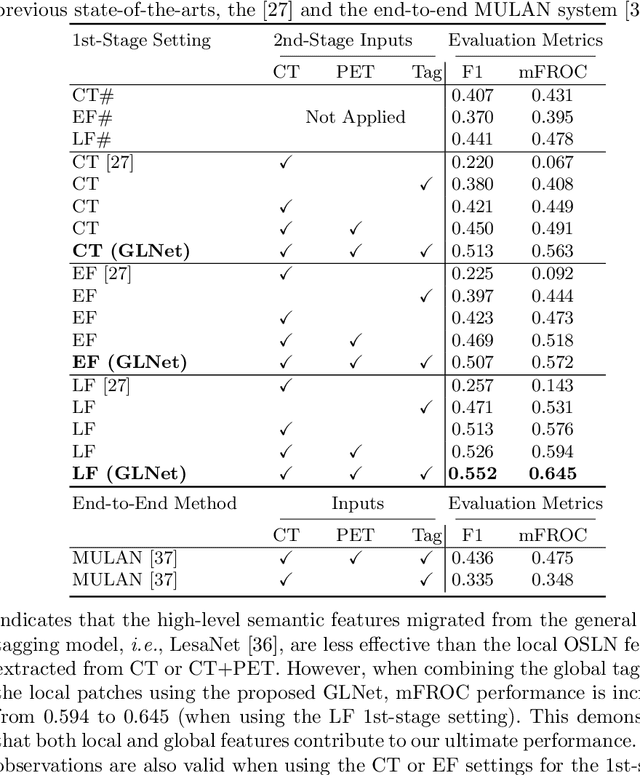
Finding and identifying scatteredly-distributed, small, and critically important objects in 3D oncology images is very challenging. We focus on the detection and segmentation of oncology-significant (or suspicious cancer metastasized) lymph nodes (OSLNs), which has not been studied before as a computational task. Determining and delineating the spread of OSLNs is essential in defining the corresponding resection/irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. For patients who are treated with radiotherapy, this task is performed by experienced radiation oncologists that involves high-level reasoning on whether LNs are metastasized, which is subject to high inter-observer variations. In this work, we propose a divide-and-conquer decision stratification approach that divides OSLNs into tumor-proximal and tumor-distal categories. This is motivated by the observation that each category has its own different underlying distributions in appearance, size and other characteristics. Two separate detection-by-segmentation networks are trained per category and fused. To further reduce false positives (FP), we present a novel global-local network (GLNet) that combines high-level lesion characteristics with features learned from localized 3D image patches. Our method is evaluated on a dataset of 141 esophageal cancer patients with PET and CT modalities (the largest to-date). Our results significantly improve the recall from $45\%$ to $67\%$ at $3$ FPs per patient as compared to previous state-of-the-art methods. The highest achieved OSLN recall of $0.828$ is clinically relevant and valuable.
JSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
May 27, 2020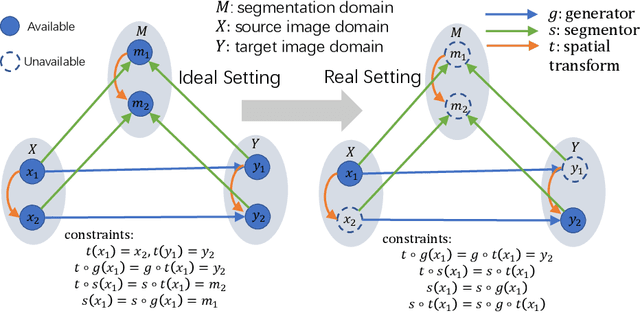
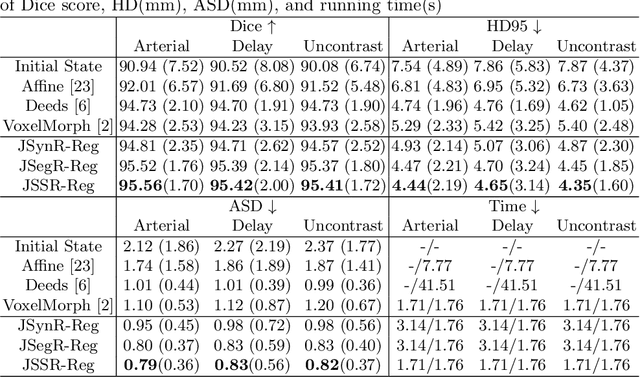
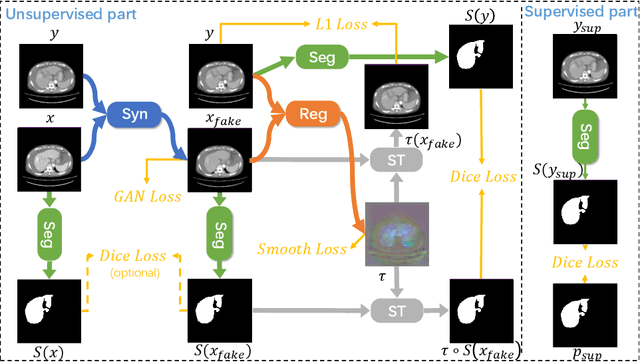
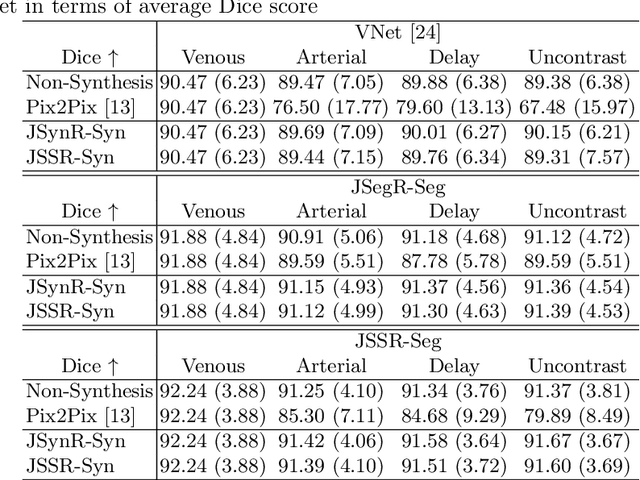
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by 0.9% and 1.9% respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.