 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAM: Binary Expert Activation Masking for Dynamic Routing in MoE
May 14, 2026Mixture-of-Experts (MoE) architectures enhance the efficiency of large language models by activating only a subset of experts per token. However, standard MoE employs a fixed Top-K routing strategy, leading to redundant computation and suboptimal inference latency. Existing acceleration methods either require costly retraining with architectural changes or suffer from severe performance drop at high sparsity due to train-inference mismatch. To address these limitations, we propose BEAM (Binary Expert Activation Masking), a novel method that learns token-adaptive expert selection via trainable binary masks. With a straight-through estimator and an auxiliary regularization loss, BEAM induces dynamic expert sparsity through end-to-end training while maintaining model capability. We further implement an efficient custom CUDA kernel for BEAM, ensuring seamless integration with the vLLM inference framework. Experiments show that BEAM retains over 98\% of the original model's performance while reducing MoE layer FLOPs by up to 85\%, achieving up to 2.5$\times$ faster decoding and 1.4$\times$ higher throughput, demonstrating its effectiveness as a practical, plug-and-play solution for efficient MoE inference.
Clore: Interactive Pathology Image Segmentation with Click-based Local Refinement
Mar 29, 2026Recent advancements in deep learning-based interactive segmentation methods have significantly improved pathology image segmentation. Most existing approaches utilize user-provided positive and negative clicks to guide the segmentation process. However, these methods primarily rely on iterative global updates for refinement, which lead to redundant re-prediction and often fail to capture fine-grained structures or correct subtle errors during localized adjustments. To address this limitation, we propose the Click-based Local Refinement (Clore) pipeline, a simple yet efficient method designed to enhance interactive segmentation. The key innovation of Clore lies in its hierarchical interaction paradigm: the initial clicks drive global segmentation to rapidly outline large target regions, while subsequent clicks progressively refine local details to achieve precise boundaries. This approach not only improves the ability to handle fine-grained segmentation tasks but also achieves high-quality results with fewer interactions. Experimental results on four datasets demonstrate that Clore achieves the best balance between segmentation accuracy and interaction cost, making it an effective solution for efficient and accurate interactive pathology image segmentation.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Enhancing Document Key Information Localization Through Data Augmentation
Feb 10, 2025The Visually Rich Form Document Intelligence and Understanding (VRDIU) Track B focuses on the localization of key information in document images. The goal is to develop a method capable of localizing objects in both digital and handwritten documents, using only digital documents for training. This paper presents a simple yet effective approach that includes a document augmentation phase and an object detection phase. Specifically, we augment the training set of digital documents by mimicking the appearance of handwritten documents. Our experiments demonstrate that this pipeline enhances the models' generalization ability and achieves high performance in the competition.
Multimodal Graph Constrastive Learning and Prompt for ChartQA
Jan 08, 2025ChartQA presents significant challenges due to the complex distribution of chart elements and the implicit patterns embedded within the underlying data. In this chapter, we have developed a joint multimodal scene graph for charts, explicitly representing the relationships between chart elements and their associated patterns. Our proposed multimodal scene graph consists of two components: a visual graph and a textual graph, each designed to capture the structural and semantic information within the chart. To unify representations across these different modalities, we introduce a multimodal graph contrastive learning approach that learns unified representations by maximizing similarity between nodes representing the same object across multimodal graphs. The learned graph representations can be seamlessly incorporated into a transformer decoder as a soft prompt. Additionally, given the growing need for Multimodal Large Language Models (MLLMs) in zero-shot scenarios, we have designed Chain-of-Thought (CoT) prompts for MLLMs to reduce hallucinations. We tested both methods on public benchmarks such as ChartQA, OpenCQA, and ChartX, demonstrating improved performance and validating the effectiveness of our proposed methods.
ChuLo: Chunk-Level Key Information Representation for Long Document Processing
Oct 14, 2024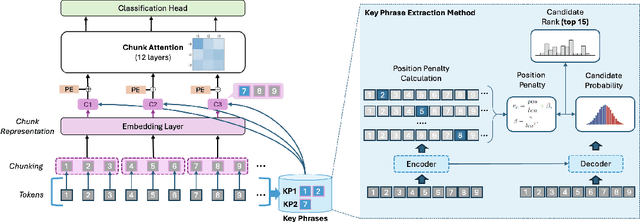
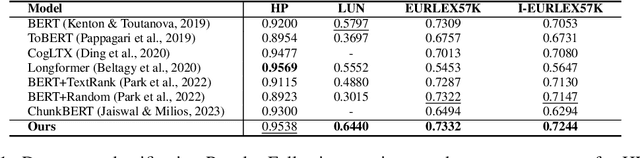
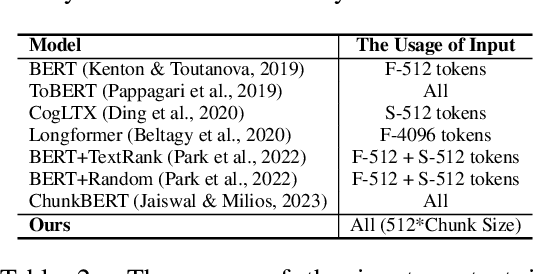
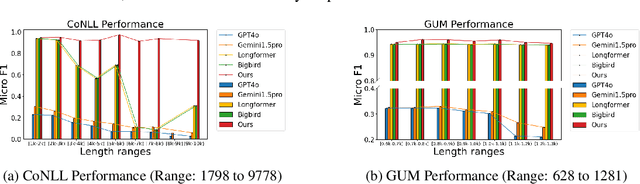
Transformer-based models have achieved remarkable success in various Natural Language Processing (NLP) tasks, yet their ability to handle long documents is constrained by computational limitations. Traditional approaches, such as truncating inputs, sparse self-attention, and chunking, attempt to mitigate these issues, but they often lead to information loss and hinder the model's ability to capture long-range dependencies. In this paper, we introduce ChuLo, a novel chunk representation method for long document classification that addresses these limitations. Our ChuLo groups input tokens using unsupervised keyphrase extraction, emphasizing semantically important keyphrase based chunk to retain core document content while reducing input length. This approach minimizes information loss and improves the efficiency of Transformer-based models. Preserving all tokens in long document understanding, especially token classification tasks, is especially important to ensure that fine-grained annotations, which depend on the entire sequence context, are not lost. We evaluate our method on multiple long document classification tasks and long document token classification tasks, demonstrating its effectiveness through comprehensive qualitative and quantitative analyses.
MSG-Chart: Multimodal Scene Graph for ChartQA
Aug 09, 2024



Automatic Chart Question Answering (ChartQA) is challenging due to the complex distribution of chart elements with patterns of the underlying data not explicitly displayed in charts. To address this challenge, we design a joint multimodal scene graph for charts to explicitly represent the relationships between chart elements and their patterns. Our proposed multimodal scene graph includes a visual graph and a textual graph to jointly capture the structural and semantical knowledge from the chart. This graph module can be easily integrated with different vision transformers as inductive bias. Our experiments demonstrate that incorporating the proposed graph module enhances the understanding of charts' elements' structure and semantics, thereby improving performance on publicly available benchmarks, ChartQA and OpenCQA.
SmartFRZ: An Efficient Training Framework using Attention-Based Layer Freezing
Jan 30, 2024

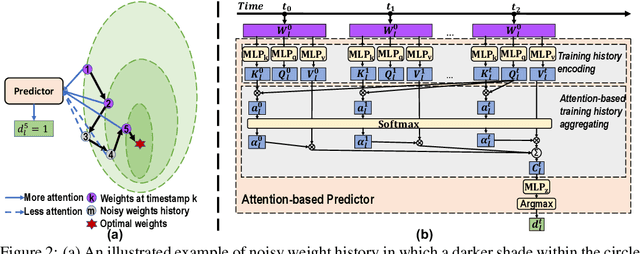

There has been a proliferation of artificial intelligence applications, where model training is key to promising high-quality services for these applications. However, the model training process is both time-intensive and energy-intensive, inevitably affecting the user's demand for application efficiency. Layer freezing, an efficient model training technique, has been proposed to improve training efficiency. Although existing layer freezing methods demonstrate the great potential to reduce model training costs, they still remain shortcomings such as lacking generalizability and compromised accuracy. For instance, existing layer freezing methods either require the freeze configurations to be manually defined before training, which does not apply to different networks, or use heuristic freezing criteria that is hard to guarantee decent accuracy in different scenarios. Therefore, there lacks a generic and smart layer freezing method that can automatically perform ``in-situation'' layer freezing for different networks during training processes. To this end, we propose a generic and efficient training framework (SmartFRZ). The core proposed technique in SmartFRZ is attention-guided layer freezing, which can automatically select the appropriate layers to freeze without compromising accuracy. Experimental results show that SmartFRZ effectively reduces the amount of computation in training and achieves significant training acceleration, and outperforms the state-of-the-art layer freezing approaches.
EdgeOL: Efficient in-situ Online Learning on Edge Devices
Jan 30, 2024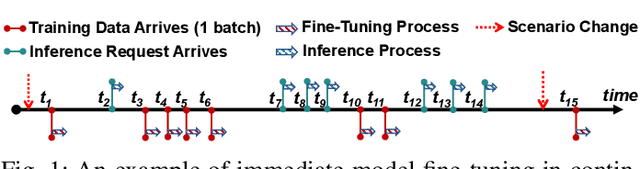
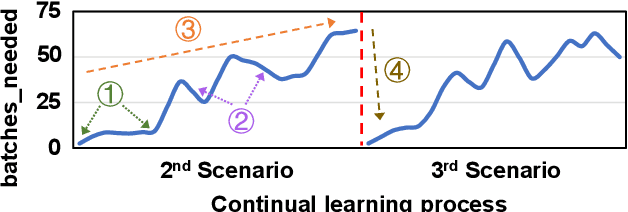
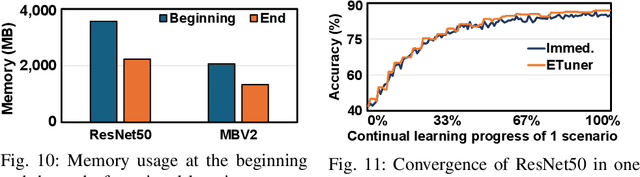
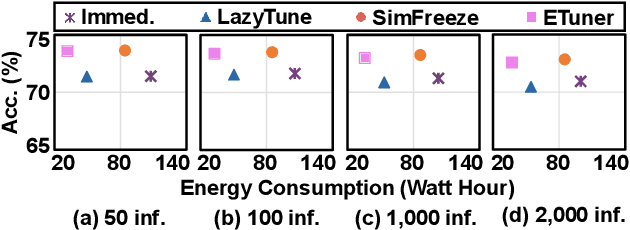
Emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) models and naturally require: i) handling streaming-in inference requests and ii) adapting to possible deployment scenario changes. Online model fine-tuning is widely adopted to satisfy these needs. However, fine-tuning involves significant energy consumption, making it challenging to deploy on edge devices. In this paper, we propose EdgeOL, an edge online learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, EdgeOL reduces overall fine-tuning execution time by 82%, energy consumption by 74%, and improves average inference accuracy by 1.70% over the immediate online learning strategy.
ImageArg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining
Sep 14, 2022


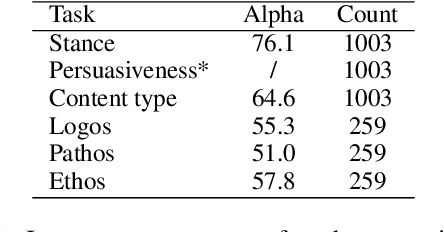
The growing interest in developing corpora of persuasive texts has promoted applications in automated systems, e.g., debating and essay scoring systems; however, there is little prior work mining image persuasiveness from an argumentative perspective. To expand persuasiveness mining into a multi-modal realm, we present a multi-modal dataset, ImageArg, consisting of annotations of image persuasiveness in tweets. The annotations are based on a persuasion taxonomy we developed to explore image functionalities and the means of persuasion. We benchmark image persuasiveness tasks on ImageArg using widely-used multi-modal learning methods. The experimental results show that our dataset offers a useful resource for this rich and challenging topic, and there is ample room for modeling improvement.