 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Dec 02, 2023After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.
Enabling Weakly-Supervised Temporal Action Localization from On-Device Learning of the Video Stream
Aug 25, 2022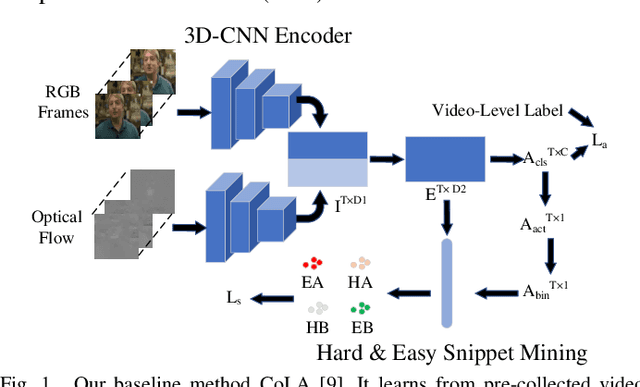
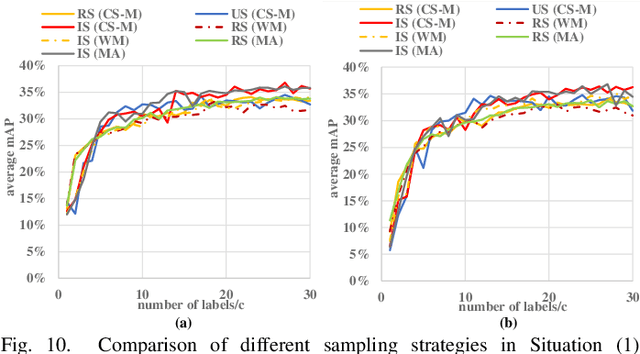
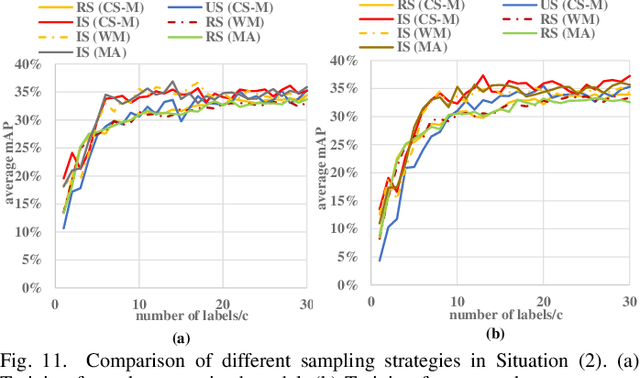
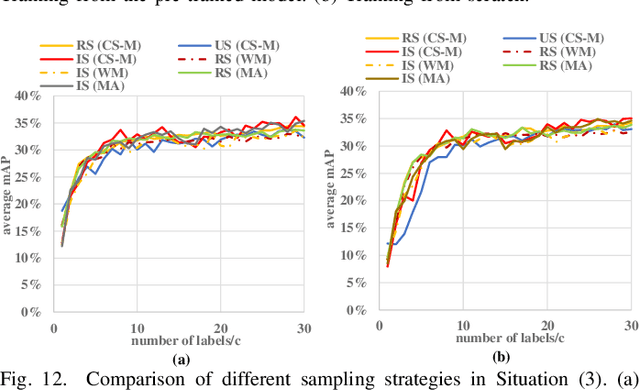
Detecting actions in videos have been widely applied in on-device applications. Practical on-device videos are always untrimmed with both action and background. It is desirable for a model to both recognize the class of action and localize the temporal position where the action happens. Such a task is called temporal action location (TAL), which is always trained on the cloud where multiple untrimmed videos are collected and labeled. It is desirable for a TAL model to continuously and locally learn from new data, which can directly improve the action detection precision while protecting customers' privacy. However, it is non-trivial to train a TAL model, since tremendous video samples with temporal annotations are required. However, annotating videos frame by frame is exorbitantly time-consuming and expensive. Although weakly-supervised TAL (W-TAL) has been proposed to learn from untrimmed videos with only video-level labels, such an approach is also not suitable for on-device learning scenarios. In practical on-device learning applications, data are collected in streaming. Dividing such a long video stream into multiple video segments requires lots of human effort, which hinders the exploration of applying the TAL tasks to realistic on-device learning applications. To enable W-TAL models to learn from a long, untrimmed streaming video, we propose an efficient video learning approach that can directly adapt to new environments. We first propose a self-adaptive video dividing approach with a contrast score-based segment merging approach to convert the video stream into multiple segments. Then, we explore different sampling strategies on the TAL tasks to request as few labels as possible. To the best of our knowledge, we are the first attempt to directly learn from the on-device, long video stream.
Sustainable AI Processing at the Edge
Jul 04, 2022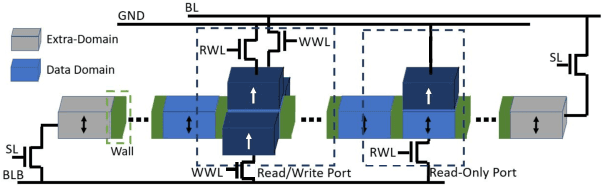
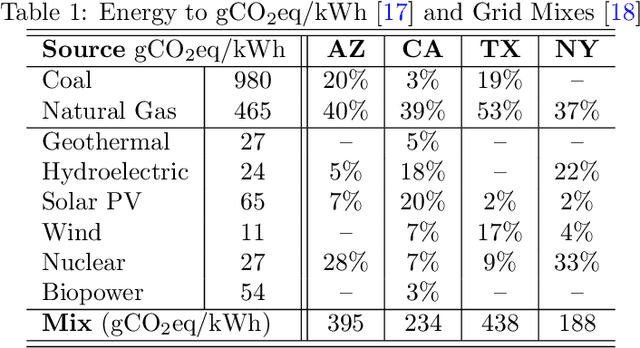
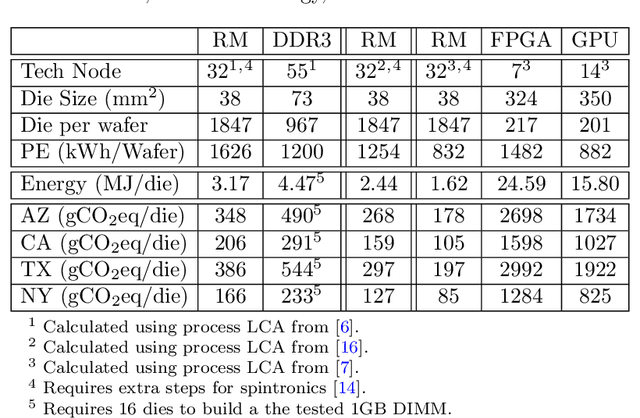
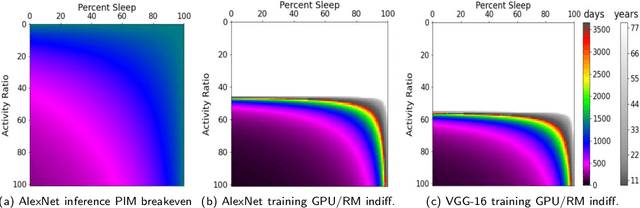
Edge computing is a popular target for accelerating machine learning algorithms supporting mobile devices without requiring the communication latencies to handle them in the cloud. Edge deployments of machine learning primarily consider traditional concerns such as SWaP constraints (Size, Weight, and Power) for their installations. However, such metrics are not entirely sufficient to consider environmental impacts from computing given the significant contributions from embodied energy and carbon. In this paper we explore the tradeoffs of convolutional neural network acceleration engines for both inference and on-line training. In particular, we explore the use of processing-in-memory (PIM) approaches, mobile GPU accelerators, and recently released FPGAs, and compare them with novel Racetrack memory PIM. Replacing PIM-enabled DDR3 with Racetrack memory PIM can recover its embodied energy as quickly as 1 year. For high activity ratios, mobile GPUs can be more sustainable but have higher embodied energy to overcome compared to PIM-enabled Racetrack memory.
H2H: Heterogeneous Model to Heterogeneous System Mapping with Computation and Communication Awareness
Apr 29, 2022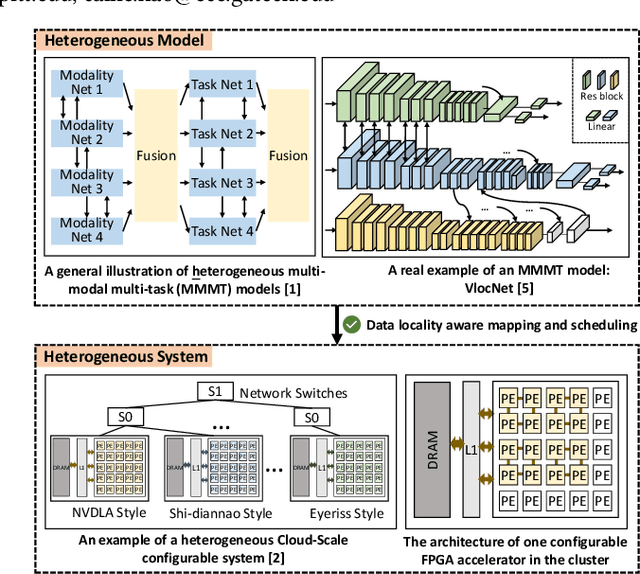
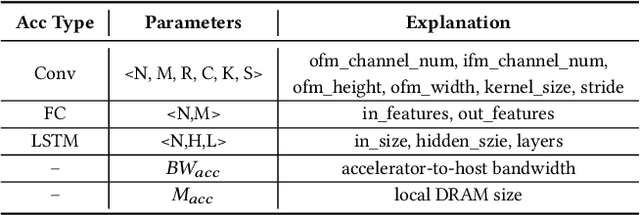
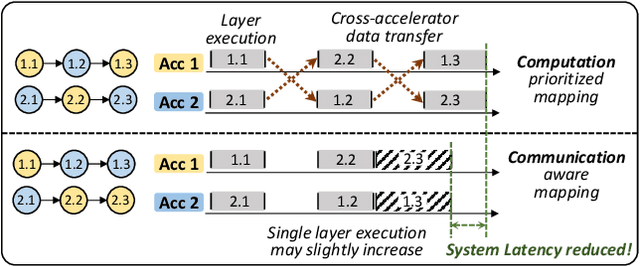
The complex nature of real-world problems calls for heterogeneity in both machine learning (ML) models and hardware systems. The heterogeneity in ML models comes from multi-sensor perceiving and multi-task learning, i.e., multi-modality multi-task (MMMT), resulting in diverse deep neural network (DNN) layers and computation patterns. The heterogeneity in systems comes from diverse processing components, as it becomes the prevailing method to integrate multiple dedicated accelerators into one system. Therefore, a new problem emerges: heterogeneous model to heterogeneous system mapping (H2H). While previous mapping algorithms mostly focus on efficient computations, in this work, we argue that it is indispensable to consider computation and communication simultaneously for better system efficiency. We propose a novel H2H mapping algorithm with both computation and communication awareness; by slightly trading computation for communication, the system overall latency and energy consumption can be largely reduced. The superior performance of our work is evaluated based on MAESTRO modeling, demonstrating 15%-74% latency reduction and 23%-64% energy reduction compared with existing computation-prioritized mapping algorithms.
EF-Train: Enable Efficient On-device CNN Training on FPGA Through Data Reshaping for Online Adaptation or Personalization
Feb 18, 2022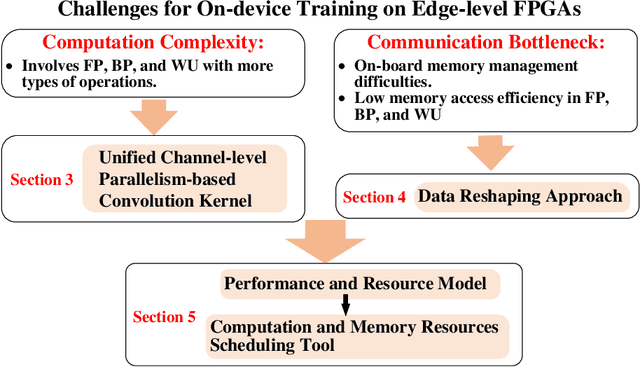

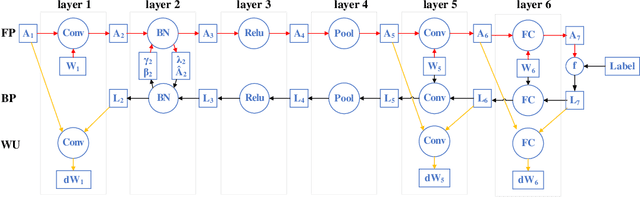

Conventionally, DNN models are trained once in the cloud and deployed in edge devices such as cars, robots, or unmanned aerial vehicles (UAVs) for real-time inference. However, there are many cases that require the models to adapt to new environments, domains, or new users. In order to realize such domain adaption or personalization, the models on devices need to be continuously trained on the device. In this work, we design EF-Train, an efficient DNN training accelerator with a unified channel-level parallelism-based convolution kernel that can achieve end-to-end training on resource-limited low-power edge-level FPGAs. It is challenging to implement on-device training on resource-limited FPGAs due to the low efficiency caused by different memory access patterns among forward, backward propagation, and weight update. Therefore, we developed a data reshaping approach with intra-tile continuous memory allocation and weight reuse. An analytical model is established to automatically schedule computation and memory resources to achieve high energy efficiency on edge FPGAs. The experimental results show that our design achieves 46.99 GFLOPS and 6.09GFLOPS/W in terms of throughput and energy efficiency, respectively.