 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Mixture-of-Agents Serving via Tree-Structured Routing, Adaptive Pruning, and Dependency-Aware Prefill-Decode Overlap
Dec 19, 2025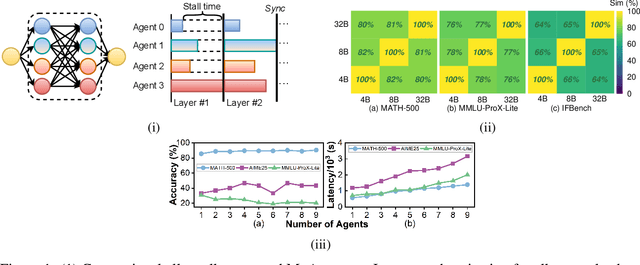
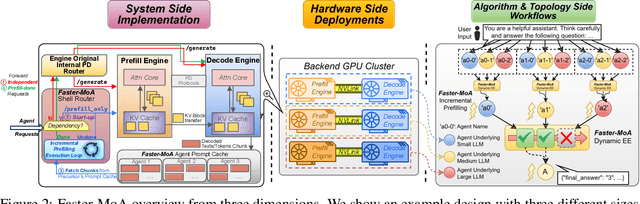
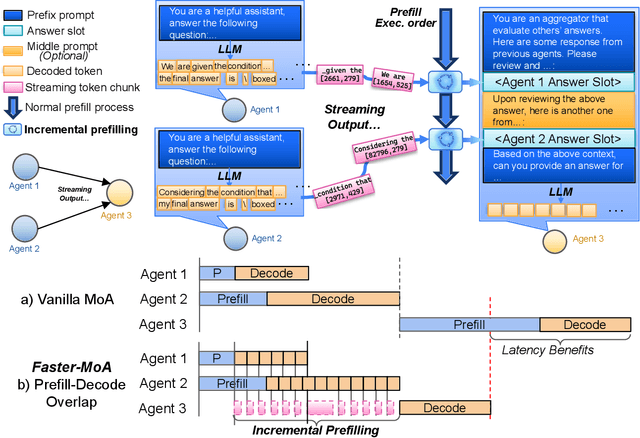
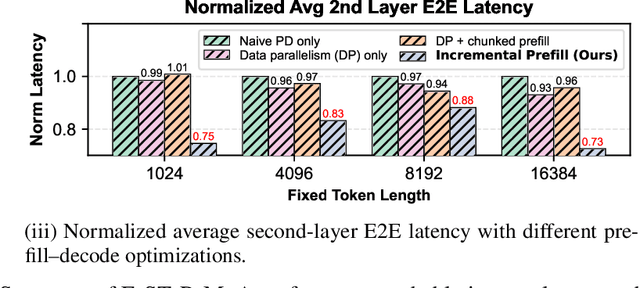
Mixture-of-Agents (MoA) inference can suffer from dense inter-agent communication and low hardware utilization, which jointly inflate serving latency. We present a serving design that targets these bottlenecks through an algorithm-system co-design. First, we replace dense agent interaction graphs with a hierarchical tree topology that induces structured sparsity in inter-agent communication. Second, we introduce a runtime adaptive mechanism that selectively terminates or skips downstream agent invocations using semantic agreement and confidence signals from intermediate outputs. Third, we pipeline agent execution by overlapping incremental prefilling with decoding across dependency-related agents, improving utilization and reducing inference latency. Across representative tasks, this approach substantially reduces end-to-end latency (up to 90%) while maintaining comparable accuracy (within $\pm$1%) relative to dense-connectivity MoA baselines, and can improve accuracy in certain settings.
HLS-Eval: A Benchmark and Framework for Evaluating LLMs on High-Level Synthesis Design Tasks
Apr 16, 2025The rapid scaling of large language model (LLM) training and inference has driven their adoption in semiconductor design across academia and industry. While most prior work evaluates LLMs on hardware description language (HDL) tasks, particularly Verilog, designers are increasingly using high-level synthesis (HLS) to build domain-specific accelerators and complex hardware systems. However, benchmarks and tooling to comprehensively evaluate LLMs for HLS design tasks remain scarce. To address this, we introduce HLS-Eval, the first complete benchmark and evaluation framework for LLM-driven HLS design. HLS-Eval targets two core tasks: (1) generating HLS code from natural language descriptions, and (2) performing HLS-specific code edits to optimize performance and hardware efficiency. The benchmark includes 94 unique designs drawn from standard HLS benchmarks and novel sources. Each case is prepared via a semi-automated flow that produces a natural language description and a paired testbench for C-simulation and synthesis validation, ensuring each task is "LLM-ready." Beyond the benchmark, HLS-Eval offers a modular Python framework for automated, parallel evaluation of both local and hosted LLMs. It includes a parallel evaluation engine, direct HLS tool integration, and abstractions for to support different LLM interaction paradigms, enabling rapid prototyping of new benchmarks, tasks, and LLM methods. We demonstrate HLS-Eval through baseline evaluations of open-source LLMs on Vitis HLS, measuring outputs across four key metrics - parseability, compilability, runnability, and synthesizability - reflecting the iterative HLS design cycle. We also report pass@k metrics, establishing clear baselines and reusable infrastructure for the broader LLM-for-hardware community. All benchmarks, framework code, and results are open-sourced at https://github.com/stefanpie/hls-eval.
MEMS Gyroscope Multi-Feature Calibration Using Machine Learning Technique
Oct 10, 2024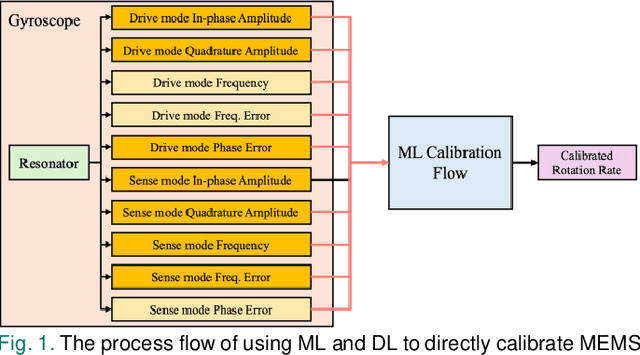
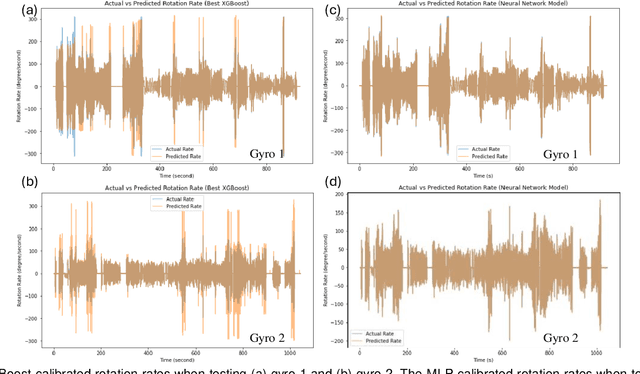
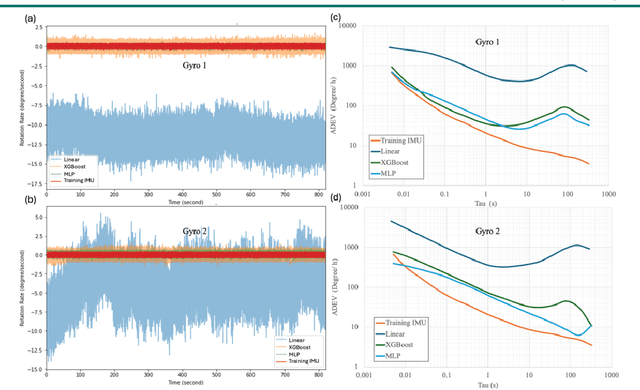
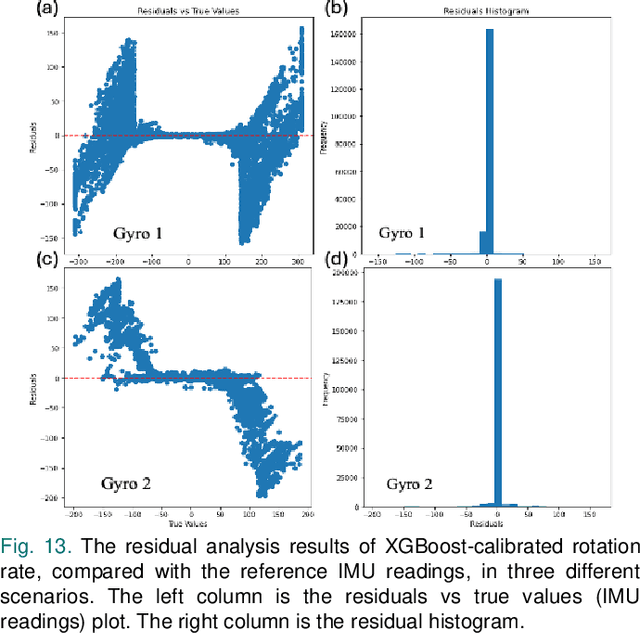
Gyroscopes are crucial for accurate angular velocity measurements in navigation, stabilization, and control systems. MEMS gyroscopes offer advantages like compact size and low cost but suffer from errors and inaccuracies that are complex and time varying. This study leverages machine learning (ML) and uses multiple signals of the MEMS resonator gyroscope to improve its calibration. XGBoost, known for its high predictive accuracy and ability to handle complex, non-linear relationships, and MLP, recognized for its capability to model intricate patterns through multiple layers and hidden dimensions, are employed to enhance the calibration process. Our findings show that both XGBoost and MLP models significantly reduce noise and enhance accuracy and stability, outperforming the traditional calibration techniques. Despite higher computational costs, DL models are ideal for high-stakes applications, while ML models are efficient for consumer electronics and environmental monitoring. Both ML and DL models demonstrate the potential of advanced calibration techniques in enhancing MEMS gyroscope performance and calibration efficiency.
Residual-INR: Communication Efficient On-Device Learning Using Implicit Neural Representation
Aug 10, 2024



Edge computing is a distributed computing paradigm that collects and processes data at or near the source of data generation. The on-device learning at edge relies on device-to-device wireless communication to facilitate real-time data sharing and collaborative decision-making among multiple devices. This significantly improves the adaptability of the edge computing system to the changing environments. However, as the scale of the edge computing system is getting larger, communication among devices is becoming the bottleneck because of the limited bandwidth of wireless communication leads to large data transfer latency. To reduce the amount of device-to-device data transmission and accelerate on-device learning, in this paper, we propose Residual-INR, a fog computing-based communication-efficient on-device learning framework by utilizing implicit neural representation (INR) to compress images/videos into neural network weights. Residual-INR enhances data transfer efficiency by collecting JPEG images from edge devices, compressing them into INR format at the fog node, and redistributing them for on-device learning. By using a smaller INR for full image encoding and a separate object INR for high-quality object region reconstruction through residual encoding, our technique can reduce the encoding redundancy while maintaining the object quality. Residual-INR is a promising solution for edge on-device learning because it reduces data transmission by up to 5.16 x across a network of 10 edge devices. It also facilitates CPU-free accelerated on-device learning, achieving up to 2.9 x speedup without sacrificing accuracy. Our code is available at: https://github.com/sharclab/Residual-INR.
HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond
May 01, 2024Machine learning (ML) techniques have been applied to high-level synthesis (HLS) flows for quality-of-result (QoR) prediction and design space exploration (DSE). Nevertheless, the scarcity of accessible high-quality HLS datasets and the complexity of building such datasets present challenges. Existing datasets have limitations in terms of benchmark coverage, design space enumeration, vendor extensibility, or lack of reproducible and extensible software for dataset construction. Many works also lack user-friendly ways to add more designs, limiting wider adoption of such datasets. In response to these challenges, we introduce HLSFactory, a comprehensive framework designed to facilitate the curation and generation of high-quality HLS design datasets. HLSFactory has three main stages: 1) a design space expansion stage to elaborate single HLS designs into large design spaces using various optimization directives across multiple vendor tools, 2) a design synthesis stage to execute HLS and FPGA tool flows concurrently across designs, and 3) a data aggregation stage for extracting standardized data into packaged datasets for ML usage. This tripartite architecture ensures broad design space coverage via design space expansion and supports multiple vendor tools. Users can contribute to each stage with their own HLS designs and synthesis results and extend the framework itself with custom frontends and tool flows. We also include an initial set of built-in designs from common HLS benchmarks curated open-source HLS designs. We showcase the versatility and multi-functionality of our framework through six case studies: I) Design space sampling; II) Fine-grained parallelism backend speedup; III) Targeting Intel's HLS flow; IV) Adding new auxiliary designs; V) Integrating published HLS data; VI) HLS tool version regression benchmarking. Code at https://github.com/sharc-lab/HLSFactory.
INR-Arch: A Dataflow Architecture and Compiler for Arbitrary-Order Gradient Computations in Implicit Neural Representation Processing
Aug 11, 2023



An increasing number of researchers are finding use for nth-order gradient computations for a wide variety of applications, including graphics, meta-learning (MAML), scientific computing, and most recently, implicit neural representations (INRs). Recent work shows that the gradient of an INR can be used to edit the data it represents directly without needing to convert it back to a discrete representation. However, given a function represented as a computation graph, traditional architectures face challenges in efficiently computing its nth-order gradient due to the higher demand for computing power and higher complexity in data movement. This makes it a promising target for FPGA acceleration. In this work, we introduce INR-Arch, a framework that transforms the computation graph of an nth-order gradient into a hardware-optimized dataflow architecture. We address this problem in two phases. First, we design a dataflow architecture that uses FIFO streams and an optimized computation kernel library, ensuring high memory efficiency and parallel computation. Second, we propose a compiler that extracts and optimizes computation graphs, automatically configures hardware parameters such as latency and stream depths to optimize throughput, while ensuring deadlock-free operation, and outputs High-Level Synthesis (HLS) code for FPGA implementation. We utilize INR editing as our benchmark, presenting results that demonstrate 1.8-4.8x and 1.5-3.6x speedup compared to CPU and GPU baselines respectively. Furthermore, we obtain 3.1-8.9x and 1.7-4.3x lower memory usage, and 1.7-11.3x and 5.5-32.8x lower energy-delay product. Our framework will be made open-source and available on GitHub.
Rapid-INR: Storage Efficient CPU-free DNN Training Using Implicit Neural Representation
Jun 29, 2023Implicit Neural Representation (INR) is an innovative approach for representing complex shapes or objects without explicitly defining their geometry or surface structure. Instead, INR represents objects as continuous functions. Previous research has demonstrated the effectiveness of using neural networks as INR for image compression, showcasing comparable performance to traditional methods such as JPEG. However, INR holds potential for various applications beyond image compression. This paper introduces Rapid-INR, a novel approach that utilizes INR for encoding and compressing images, thereby accelerating neural network training in computer vision tasks. Our methodology involves storing the whole dataset directly in INR format on a GPU, mitigating the significant data communication overhead between the CPU and GPU during training. Additionally, the decoding process from INR to RGB format is highly parallelized and executed on-the-fly. To further enhance compression, we propose iterative and dynamic pruning, as well as layer-wise quantization, building upon previous work. We evaluate our framework on the image classification task, utilizing the ResNet-18 backbone network and three commonly used datasets with varying image sizes. Rapid-INR reduces memory consumption to only 5% of the original dataset size and achieves a maximum 6$\times$ speedup over the PyTorch training pipeline, as well as a maximum 1.2x speedup over the DALI training pipeline, with only a marginal decrease in accuracy. Importantly, Rapid-INR can be readily applied to other computer vision tasks and backbone networks with reasonable engineering efforts. Our implementation code is publicly available at https://anonymous.4open.science/r/INR-4BF7.
Edge-MoE: Memory-Efficient Multi-Task Vision Transformer Architecture with Task-level Sparsity via Mixture-of-Experts
May 30, 2023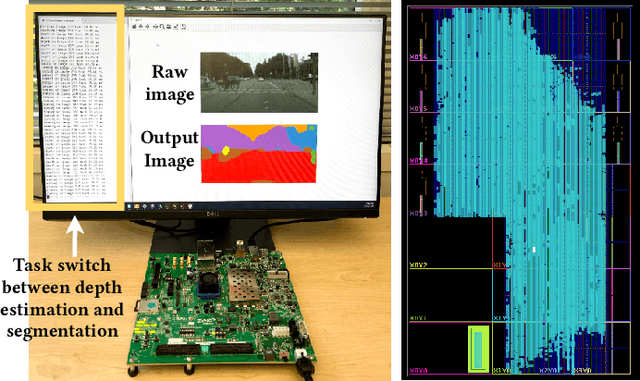


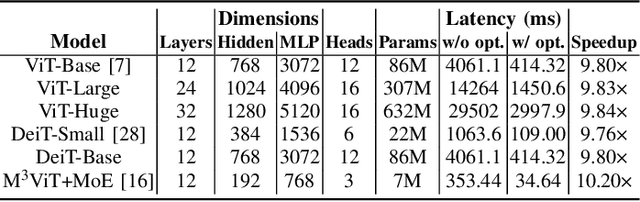
Computer vision researchers are embracing two promising paradigms: Vision Transformers (ViTs) and Multi-task Learning (MTL), which both show great performance but are computation-intensive, given the quadratic complexity of self-attention in ViT and the need to activate an entire large MTL model for one task. M$^3$ViT is the latest multi-task ViT model that introduces mixture-of-experts (MoE), where only a small portion of subnetworks ("experts") are sparsely and dynamically activated based on the current task. M$^3$ViT achieves better accuracy and over 80% computation reduction but leaves challenges for efficient deployment on FPGA. Our work, dubbed Edge-MoE, solves the challenges to introduce the first end-to-end FPGA accelerator for multi-task ViT with a collection of architectural innovations, including (1) a novel reordering mechanism for self-attention, which requires only constant bandwidth regardless of the target parallelism; (2) a fast single-pass softmax approximation; (3) an accurate and low-cost GELU approximation; (4) a unified and flexible computing unit that is shared by almost all computational layers to maximally reduce resource usage; and (5) uniquely for M$^3$ViT, a novel patch reordering method to eliminate memory access overhead. Edge-MoE achieves 2.24x and 4.90x better energy efficiency comparing with GPU and CPU, respectively. A real-time video demonstration is available online, along with our code written using High-Level Synthesis, which will be open-sourced.
DGNN-Booster: A Generic FPGA Accelerator Framework For Dynamic Graph Neural Network Inference
Apr 13, 2023



Dynamic Graph Neural Networks (DGNNs) are becoming increasingly popular due to their effectiveness in analyzing and predicting the evolution of complex interconnected graph-based systems. However, hardware deployment of DGNNs still remains a challenge. First, DGNNs do not fully utilize hardware resources because temporal data dependencies cause low hardware parallelism. Additionally, there is currently a lack of generic DGNN hardware accelerator frameworks, and existing GNN accelerator frameworks have limited ability to handle dynamic graphs with changing topologies and node features. To address the aforementioned challenges, in this paper, we propose DGNN-Booster, which is a novel Field-Programmable Gate Array (FPGA) accelerator framework for real-time DGNN inference using High-Level Synthesis (HLS). It includes two different FPGA accelerator designs with different dataflows that can support the most widely used DGNNs. We showcase the effectiveness of our designs by implementing and evaluating two representative DGNN models on ZCU102 board and measuring the end-to-end performance. The experiment results demonstrate that DGNN-Booster can achieve a speedup of up to 5.6x compared to the CPU baseline (6226R), 8.4x compared to the GPU baseline (A6000) and 2.1x compared to the FPGA baseline without applying optimizations proposed in this paper. Moreover, DGNN-Booster can achieve over 100x and over 1000x runtime energy efficiency than the CPU and GPU baseline respectively. Our implementation code and on-board measurements are publicly available at https://github.com/sharc-lab/DGNN-Booster.
GNNBuilder: An Automated Framework for Generic Graph Neural Network Accelerator Generation, Simulation, and Optimization
Mar 29, 2023



There are plenty of graph neural network (GNN) accelerators being proposed. However, they highly rely on users' hardware expertise and are usually optimized for one specific GNN model, making them challenging for practical use . Therefore, in this work, we propose GNNBuilder, the first automated, generic, end-to-end GNN accelerator generation framework. It features four advantages: (1) GNNBuilder can automatically generate GNN accelerators for a wide range of GNN models arbitrarily defined by users; (2) GNNBuilder takes standard PyTorch programming interface, introducing zero overhead for algorithm developers; (3) GNNBuilder supports end-to-end code generation, simulation, accelerator optimization, and hardware deployment, realizing a push-button fashion for GNN accelerator design; (4) GNNBuilder is equipped with accurate performance models of its generated accelerator, enabling fast and flexible design space exploration (DSE). In the experiments, first, we show that our accelerator performance model has errors within $36\%$ for latency prediction and $18\%$ for BRAM count prediction. Second, we show that our generated accelerators can outperform CPU by $6.33\times$ and GPU by $6.87\times$. This framework is open-source, and the code is available at https://anonymous.4open.science/r/gnn-builder-83B4/.