 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning based 6-DoF Maneuvers for Microgravity Intravehicular Docking: A Simulation Study with Int-Ball2 in ISS-JEM
Dec 15, 2025Autonomous free-flyers play a critical role in intravehicular tasks aboard the International Space Station (ISS), where their precise docking under sensing noise, small actuation mismatches, and environmental variability remains a nontrivial challenge. This work presents a reinforcement learning (RL) framework for six-degree-of-freedom (6-DoF) docking of JAXA's Int-Ball2 robot inside a high-fidelity Isaac Sim model of the Japanese Experiment Module (JEM). Using Proximal Policy Optimization (PPO), we train and evaluate controllers under domain-randomized dynamics and bounded observation noise, while explicitly modeling propeller drag-torque effects and polarity structure. This enables a controlled study of how Int-Ball2's propulsion physics influence RL-based docking performance in constrained microgravity interiors. The learned policy achieves stable and reliable docking across varied conditions and lays the groundwork for future extensions pertaining to Int-Ball2 in collision-aware navigation, safe RL, propulsion-accurate sim-to-real transfer, and vision-based end-to-end docking.
Iterative NLP Query Refinement for Enhancing Domain-Specific Information Retrieval: A Case Study in Career Services
Dec 22, 2024

Retrieving semantically relevant documents in niche domains poses significant challenges for traditional TF-IDF-based systems, often resulting in low similarity scores and suboptimal retrieval performance. This paper addresses these challenges by introducing an iterative and semi-automated query refinement methodology tailored to Humber College's career services webpages. Initially, generic queries related to interview preparation yield low top-document similarities (approximately 0.2--0.3). To enhance retrieval effectiveness, we implement a two-fold approach: first, domain-aware query refinement by incorporating specialized terms such as resources-online-learning, student-online-services, and career-advising; second, the integration of structured educational descriptors like "online resume and interview improvement tools." Additionally, we automate the extraction of domain-specific keywords from top-ranked documents to suggest relevant terms for query expansion. Through experiments conducted on five baseline queries, our semi-automated iterative refinement process elevates the average top similarity score from approximately 0.18 to 0.42, marking a substantial improvement in retrieval performance. The implementation details, including reproducible code and experimental setups, are made available in our GitHub repositories \url{https://github.com/Elipei88/HumberChatbotBackend} and \url{https://github.com/Nisarg851/HumberChatbot}. We also discuss the limitations of our approach and propose future directions, including the integration of advanced neural retrieval models.
HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond
May 01, 2024Machine learning (ML) techniques have been applied to high-level synthesis (HLS) flows for quality-of-result (QoR) prediction and design space exploration (DSE). Nevertheless, the scarcity of accessible high-quality HLS datasets and the complexity of building such datasets present challenges. Existing datasets have limitations in terms of benchmark coverage, design space enumeration, vendor extensibility, or lack of reproducible and extensible software for dataset construction. Many works also lack user-friendly ways to add more designs, limiting wider adoption of such datasets. In response to these challenges, we introduce HLSFactory, a comprehensive framework designed to facilitate the curation and generation of high-quality HLS design datasets. HLSFactory has three main stages: 1) a design space expansion stage to elaborate single HLS designs into large design spaces using various optimization directives across multiple vendor tools, 2) a design synthesis stage to execute HLS and FPGA tool flows concurrently across designs, and 3) a data aggregation stage for extracting standardized data into packaged datasets for ML usage. This tripartite architecture ensures broad design space coverage via design space expansion and supports multiple vendor tools. Users can contribute to each stage with their own HLS designs and synthesis results and extend the framework itself with custom frontends and tool flows. We also include an initial set of built-in designs from common HLS benchmarks curated open-source HLS designs. We showcase the versatility and multi-functionality of our framework through six case studies: I) Design space sampling; II) Fine-grained parallelism backend speedup; III) Targeting Intel's HLS flow; IV) Adding new auxiliary designs; V) Integrating published HLS data; VI) HLS tool version regression benchmarking. Code at https://github.com/sharc-lab/HLSFactory.
ULEEN: A Novel Architecture for Ultra Low-Energy Edge Neural Networks
Apr 20, 2023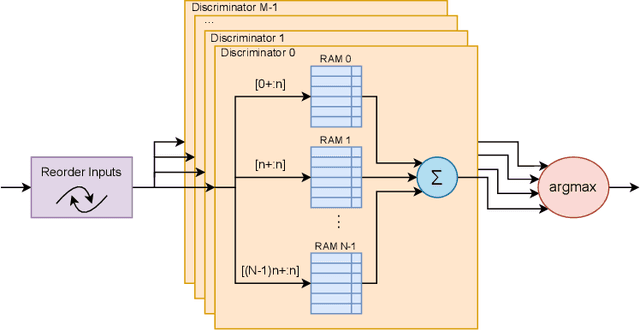
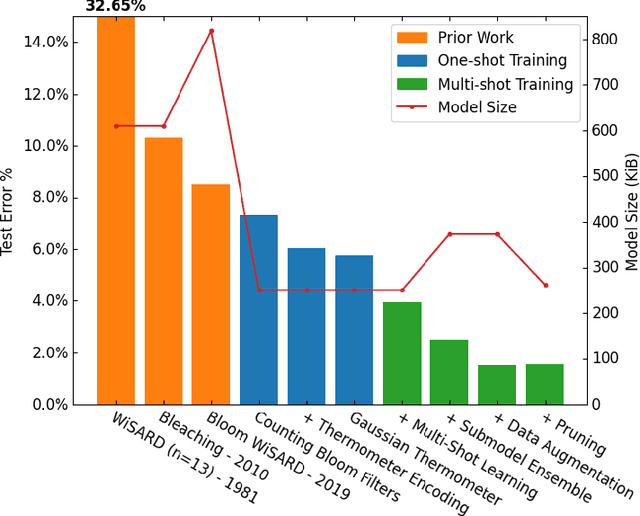
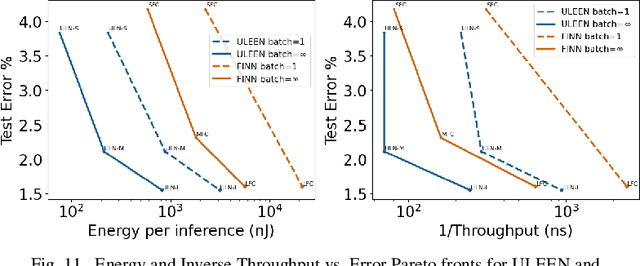
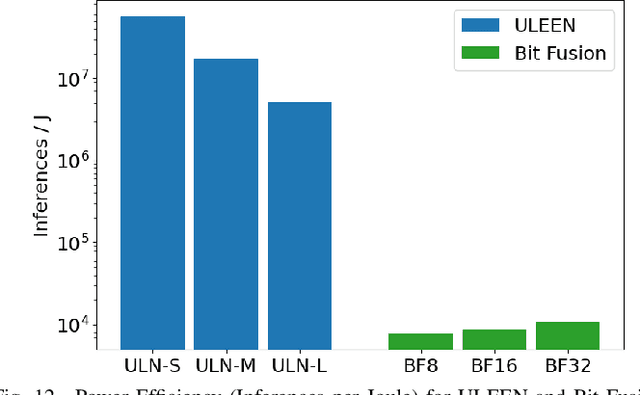
The deployment of AI models on low-power, real-time edge devices requires accelerators for which energy, latency, and area are all first-order concerns. There are many approaches to enabling deep neural networks (DNNs) in this domain, including pruning, quantization, compression, and binary neural networks (BNNs), but with the emergence of the "extreme edge", there is now a demand for even more efficient models. In order to meet the constraints of ultra-low-energy devices, we propose ULEEN, a model architecture based on weightless neural networks. Weightless neural networks (WNNs) are a class of neural model which use table lookups, not arithmetic, to perform computation. The elimination of energy-intensive arithmetic operations makes WNNs theoretically well suited for edge inference; however, they have historically suffered from poor accuracy and excessive memory usage. ULEEN incorporates algorithmic improvements and a novel training strategy inspired by BNNs to make significant strides in improving accuracy and reducing model size. We compare FPGA and ASIC implementations of an inference accelerator for ULEEN against edge-optimized DNN and BNN devices. On a Xilinx Zynq Z-7045 FPGA, we demonstrate classification on the MNIST dataset at 14.3 million inferences per second (13 million inferences/Joule) with 0.21 $\mu$s latency and 96.2% accuracy, while Xilinx FINN achieves 12.3 million inferences per second (1.69 million inferences/Joule) with 0.31 $\mu$s latency and 95.83% accuracy. In a 45nm ASIC, we achieve 5.1 million inferences/Joule and 38.5 million inferences/second at 98.46% accuracy, while a quantized Bit Fusion model achieves 9230 inferences/Joule and 19,100 inferences/second at 99.35% accuracy. In our search for ever more efficient edge devices, ULEEN shows that WNNs are deserving of consideration.
HLSDataset: Open-Source Dataset for ML-Assisted FPGA Design using High Level Synthesis
Feb 17, 2023Machine Learning (ML) has been widely adopted in design exploration using high level synthesis (HLS) to give a better and faster performance, and resource and power estimation at very early stages for FPGA-based design. To perform prediction accurately, high-quality and large-volume datasets are required for training ML models.This paper presents a dataset for ML-assisted FPGA design using HLS, called HLSDataset. The dataset is generated from widely used HLS C benchmarks including Polybench, Machsuite, CHStone and Rossetta. The Verilog samples are generated with a variety of directives including loop unroll, loop pipeline and array partition to make sure optimized and realistic designs are covered. The total number of generated Verilog samples is nearly 9,000 per FPGA type. To demonstrate the effectiveness of our dataset, we undertake case studies to perform power estimation and resource usage estimation with ML models trained with our dataset. All the codes and dataset are public at the github repo.We believe that HLSDataset can save valuable time for researchers by avoiding the tedious process of running tools, scripting and parsing files to generate the dataset, and enable them to spend more time where it counts, that is, in training ML models.
Weightless Neural Networks for Efficient Edge Inference
Mar 03, 2022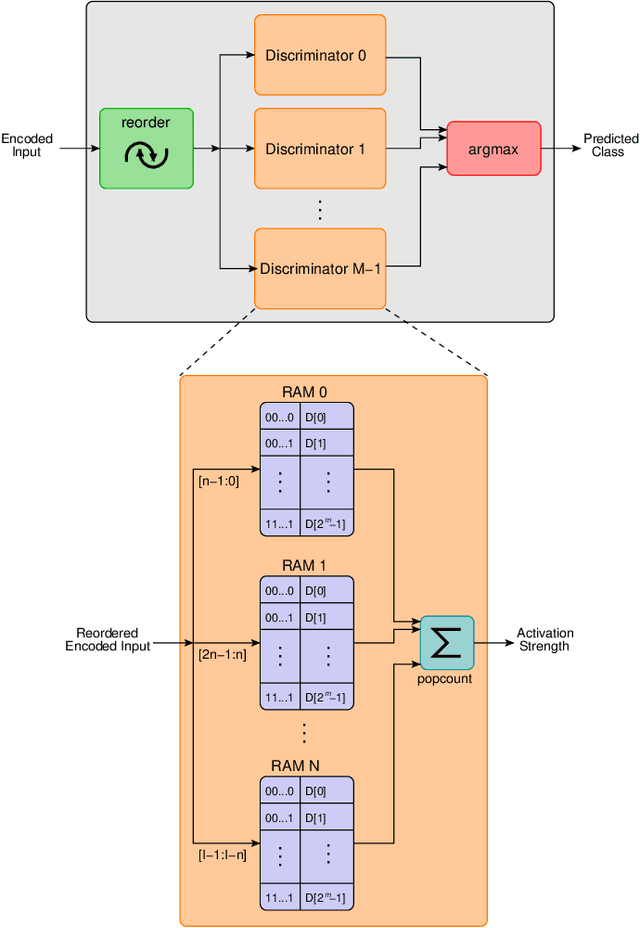
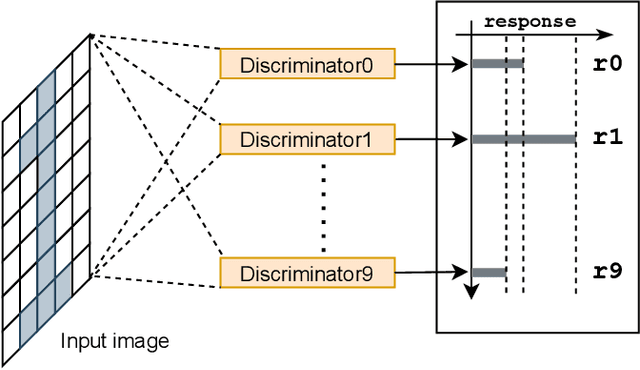
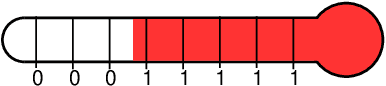
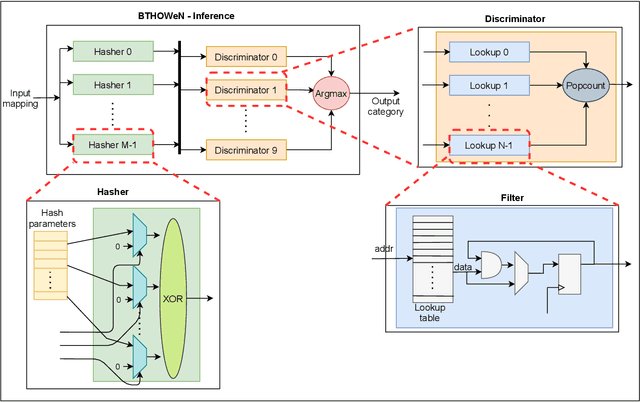
Weightless Neural Networks (WNNs) are a class of machine learning model which use table lookups to perform inference. This is in contrast with Deep Neural Networks (DNNs), which use multiply-accumulate operations. State-of-the-art WNN architectures have a fraction of the implementation cost of DNNs, but still lag behind them on accuracy for common image recognition tasks. Additionally, many existing WNN architectures suffer from high memory requirements. In this paper, we propose a novel WNN architecture, BTHOWeN, with key algorithmic and architectural improvements over prior work, namely counting Bloom filters, hardware-friendly hashing, and Gaussian-based nonlinear thermometer encodings to improve model accuracy and reduce area and energy consumption. BTHOWeN targets the large and growing edge computing sector by providing superior latency and energy efficiency to comparable quantized DNNs. Compared to state-of-the-art WNNs across nine classification datasets, BTHOWeN on average reduces error by more than than 40% and model size by more than 50%. We then demonstrate the viability of the BTHOWeN architecture by presenting an FPGA-based accelerator, and compare its latency and resource usage against similarly accurate quantized DNN accelerators, including Multi-Layer Perceptron (MLP) and convolutional models. The proposed BTHOWeN models consume almost 80% less energy than the MLP models, with nearly 85% reduction in latency. In our quest for efficient ML on the edge, WNNs are clearly deserving of additional attention.
Compute RAMs: Adaptable Compute and Storage Blocks for DL-Optimized FPGAs
Jul 19, 2021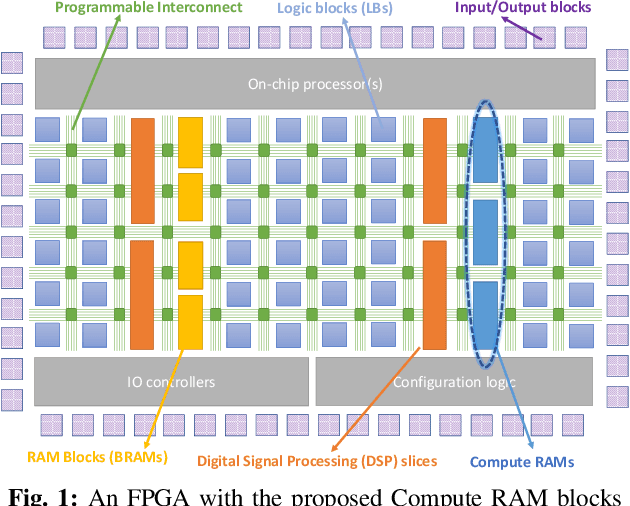
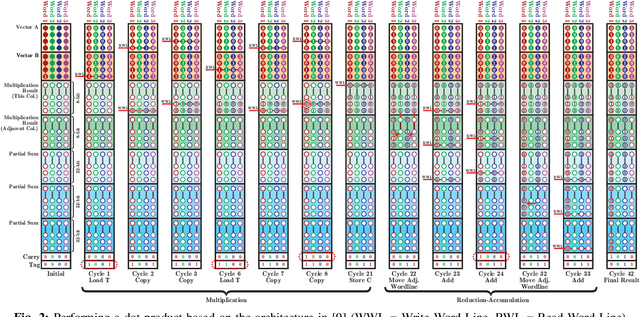

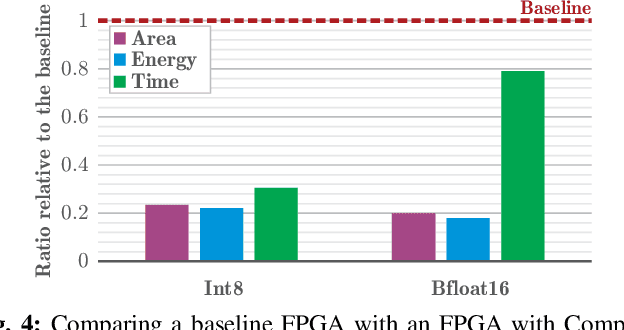
The configurable building blocks of current FPGAs -- Logic blocks (LBs), Digital Signal Processing (DSP) slices, and Block RAMs (BRAMs) -- make them efficient hardware accelerators for the rapid-changing world of Deep Learning (DL). Communication between these blocks happens through an interconnect fabric consisting of switching elements spread throughout the FPGA. In this paper, a new block, Compute RAM, is proposed. Compute RAMs provide highly-parallel processing-in-memory (PIM) by combining computation and storage capabilities in one block. Compute RAMs can be integrated in the FPGA fabric just like the existing FPGA blocks and provide two modes of operation (storage or compute) that can be dynamically chosen. They reduce power consumption by reducing data movement, provide adaptable precision support, and increase the effective on-chip memory bandwidth. Compute RAMs also help increase the compute density of FPGAs. In our evaluation of addition, multiplication and dot-product operations across multiple data precisions (int4, int8 and bfloat16), we observe an average savings of 80% in energy consumption, and an improvement in execution time ranging from 20% to 80%. Adding Compute RAMs can benefit non-DL applications as well, and make FPGAs more efficient, flexible, and performant accelerators.