 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULEEN: A Novel Architecture for Ultra Low-Energy Edge Neural Networks
Apr 20, 2023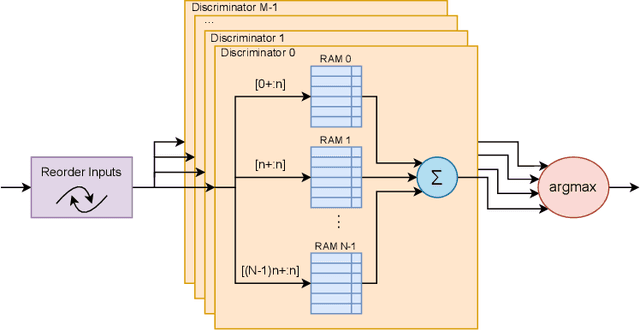
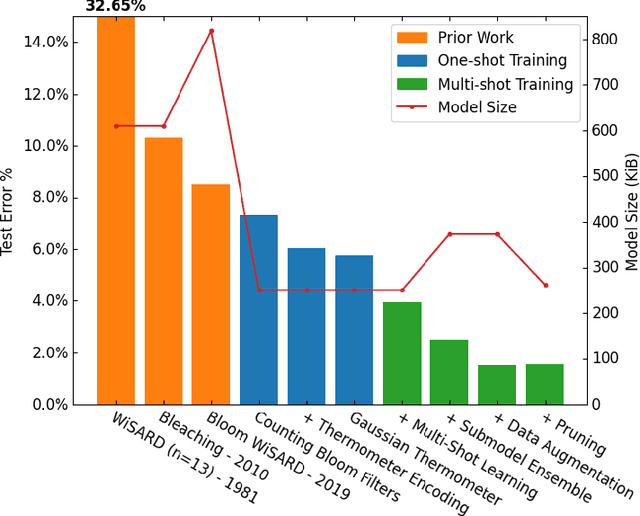
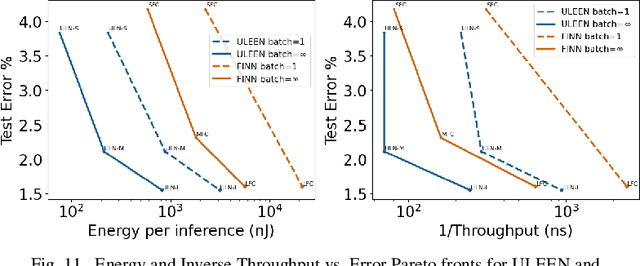
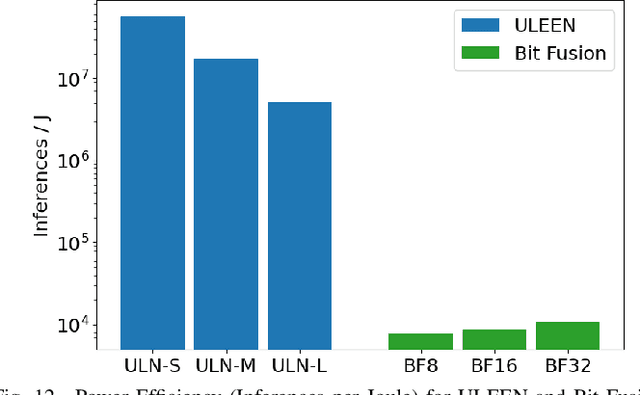
The deployment of AI models on low-power, real-time edge devices requires accelerators for which energy, latency, and area are all first-order concerns. There are many approaches to enabling deep neural networks (DNNs) in this domain, including pruning, quantization, compression, and binary neural networks (BNNs), but with the emergence of the "extreme edge", there is now a demand for even more efficient models. In order to meet the constraints of ultra-low-energy devices, we propose ULEEN, a model architecture based on weightless neural networks. Weightless neural networks (WNNs) are a class of neural model which use table lookups, not arithmetic, to perform computation. The elimination of energy-intensive arithmetic operations makes WNNs theoretically well suited for edge inference; however, they have historically suffered from poor accuracy and excessive memory usage. ULEEN incorporates algorithmic improvements and a novel training strategy inspired by BNNs to make significant strides in improving accuracy and reducing model size. We compare FPGA and ASIC implementations of an inference accelerator for ULEEN against edge-optimized DNN and BNN devices. On a Xilinx Zynq Z-7045 FPGA, we demonstrate classification on the MNIST dataset at 14.3 million inferences per second (13 million inferences/Joule) with 0.21 $\mu$s latency and 96.2% accuracy, while Xilinx FINN achieves 12.3 million inferences per second (1.69 million inferences/Joule) with 0.31 $\mu$s latency and 95.83% accuracy. In a 45nm ASIC, we achieve 5.1 million inferences/Joule and 38.5 million inferences/second at 98.46% accuracy, while a quantized Bit Fusion model achieves 9230 inferences/Joule and 19,100 inferences/second at 99.35% accuracy. In our search for ever more efficient edge devices, ULEEN shows that WNNs are deserving of consideration.