 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute RAMs: Adaptable Compute and Storage Blocks for DL-Optimized FPGAs
Jul 19, 2021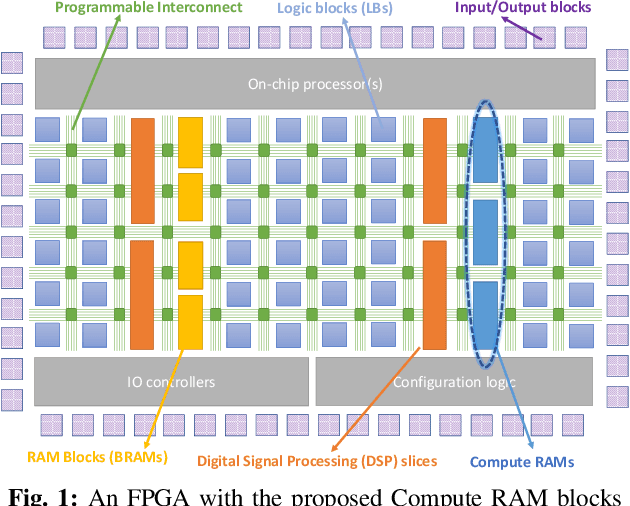
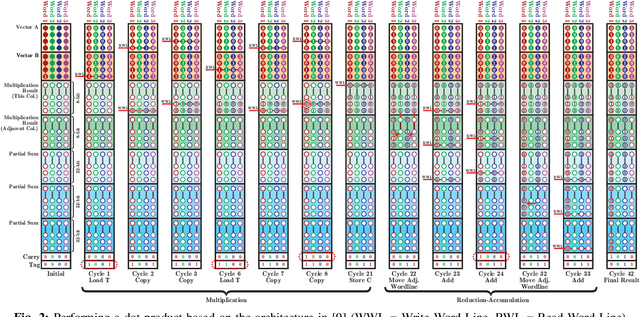

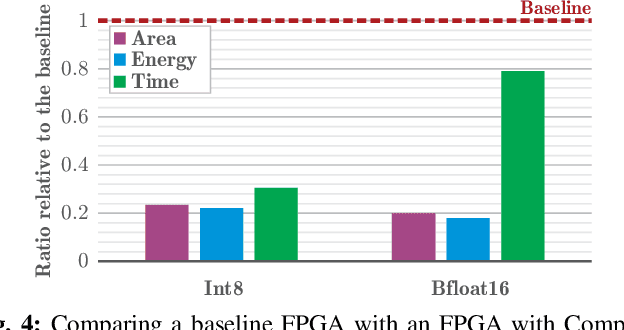
The configurable building blocks of current FPGAs -- Logic blocks (LBs), Digital Signal Processing (DSP) slices, and Block RAMs (BRAMs) -- make them efficient hardware accelerators for the rapid-changing world of Deep Learning (DL). Communication between these blocks happens through an interconnect fabric consisting of switching elements spread throughout the FPGA. In this paper, a new block, Compute RAM, is proposed. Compute RAMs provide highly-parallel processing-in-memory (PIM) by combining computation and storage capabilities in one block. Compute RAMs can be integrated in the FPGA fabric just like the existing FPGA blocks and provide two modes of operation (storage or compute) that can be dynamically chosen. They reduce power consumption by reducing data movement, provide adaptable precision support, and increase the effective on-chip memory bandwidth. Compute RAMs also help increase the compute density of FPGAs. In our evaluation of addition, multiplication and dot-product operations across multiple data precisions (int4, int8 and bfloat16), we observe an average savings of 80% in energy consumption, and an improvement in execution time ranging from 20% to 80%. Adding Compute RAMs can benefit non-DL applications as well, and make FPGAs more efficient, flexible, and performant accelerators.
Demystifying the MLPerf Benchmark Suite
Aug 24, 2019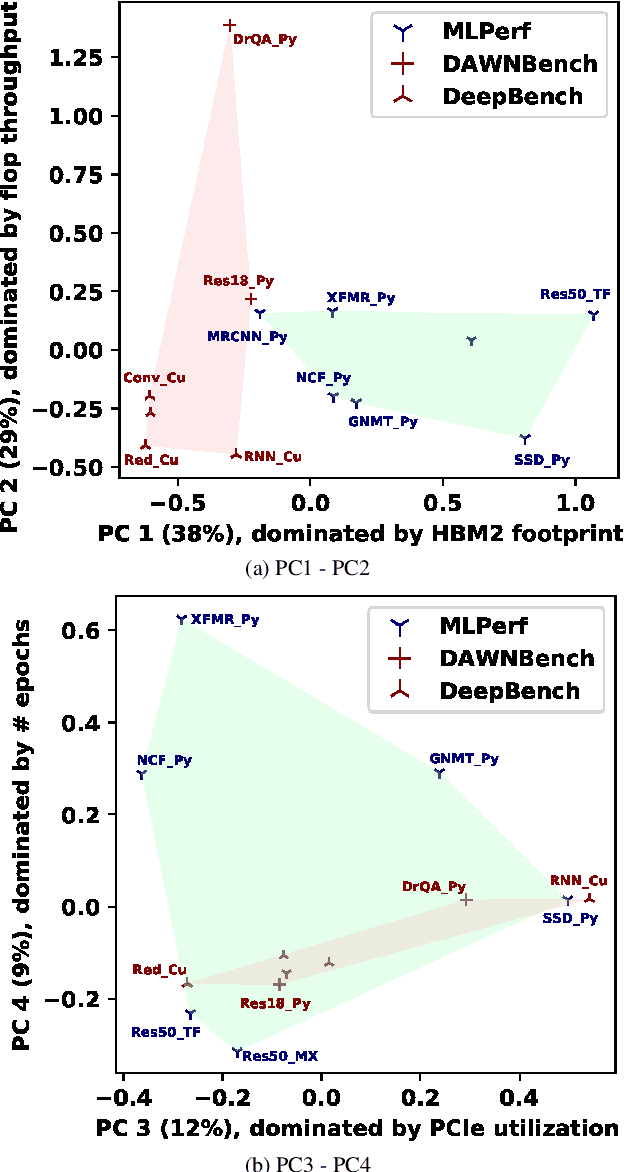
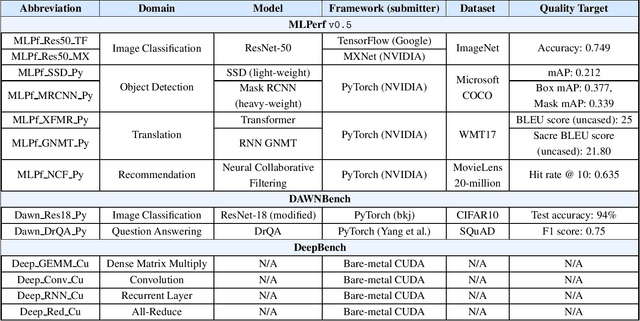
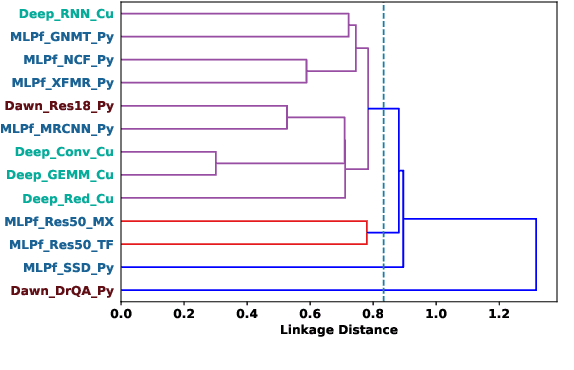
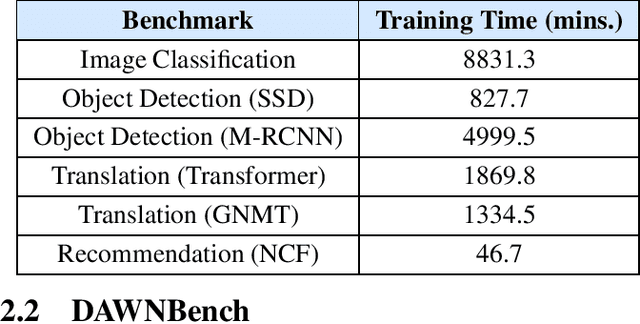
MLPerf, an emerging machine learning benchmark suite strives to cover a broad range of applications of machine learning. We present a study on its characteristics and how the MLPerf benchmarks differ from some of the previous deep learning benchmarks like DAWNBench and DeepBench. We find that application benchmarks such as MLPerf (although rich in kernels) exhibit different features compared to kernel benchmarks such as DeepBench. MLPerf benchmark suite contains a diverse set of models which allows unveiling various bottlenecks in the system. Based on our findings, dedicated low latency interconnect between GPUs in multi-GPU systems is required for optimal distributed deep learning training. We also observe variation in scaling efficiency across the MLPerf models. The variation exhibited by the different models highlight the importance of smart scheduling strategies for multi-GPU training. Another observation is that CPU utilization increases with increase in number of GPUs used for training. Corroborating prior work we also observe and quantify improvements possible by compiler optimizations, mixed-precision training and use of Tensor Cores.