 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinking the Giant : Quasi-Weightless Transformers for Low Energy Inference
Nov 04, 2024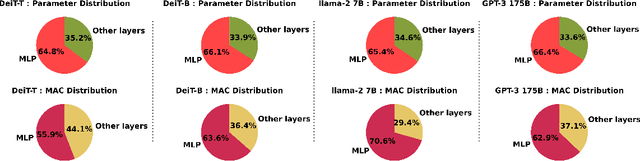

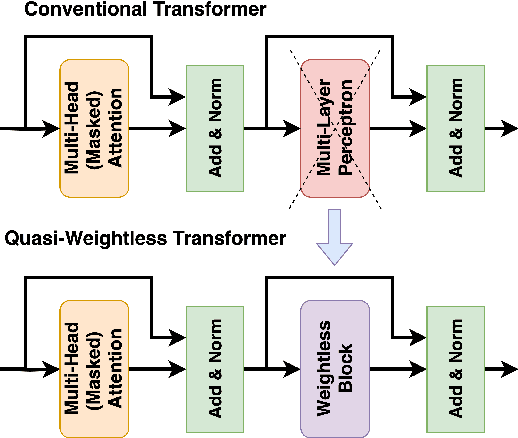
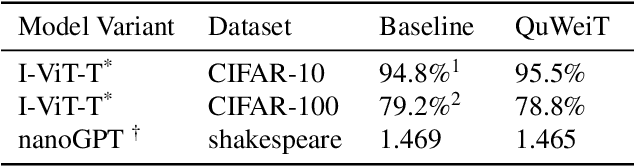
Transformers are set to become ubiquitous with applications ranging from chatbots and educational assistants to visual recognition and remote sensing. However, their increasing computational and memory demands is resulting in growing energy consumption. Building models with fast and energy-efficient inference is imperative to enable a variety of transformer-based applications. Look Up Table (LUT) based Weightless Neural Networks are faster than the conventional neural networks as their inference only involves a few lookup operations. Recently, an approach for learning LUT networks directly via an Extended Finite Difference method was proposed. We build on this idea, extending it for performing the functions of the Multi Layer Perceptron (MLP) layers in transformer models and integrating them with transformers to propose Quasi Weightless Transformers (QuWeiT). This allows for a computational and energy-efficient inference solution for transformer-based models. On I-ViT-T, we achieve a comparable accuracy of 95.64% on CIFAR-10 dataset while replacing approximately 55% of all the multiplications in the entire model and achieving a 2.2x energy efficiency. We also observe similar savings on experiments with the nanoGPT framework.
Neuro-Symbolic AI: An Emerging Class of AI Workloads and their Characterization
Sep 13, 2021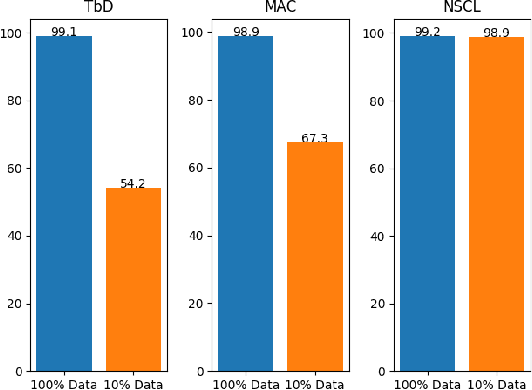

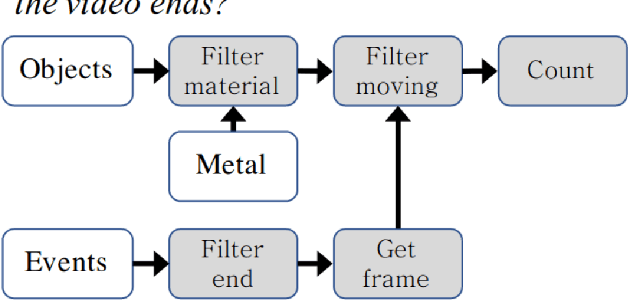
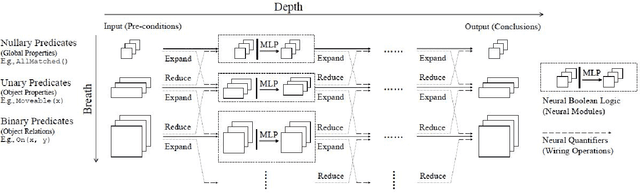
Neuro-symbolic artificial intelligence is a novel area of AI research which seeks to combine traditional rules-based AI approaches with modern deep learning techniques. Neuro-symbolic models have already demonstrated the capability to outperform state-of-the-art deep learning models in domains such as image and video reasoning. They have also been shown to obtain high accuracy with significantly less training data than traditional models. Due to the recency of the field's emergence and relative sparsity of published results, the performance characteristics of these models are not well understood. In this paper, we describe and analyze the performance characteristics of three recent neuro-symbolic models. We find that symbolic models have less potential parallelism than traditional neural models due to complex control flow and low-operational-intensity operations, such as scalar multiplication and tensor addition. However, the neural aspect of computation dominates the symbolic part in cases where they are clearly separable. We also find that data movement poses a potential bottleneck, as it does in many ML workloads.
Demystifying the MLPerf Benchmark Suite
Aug 24, 2019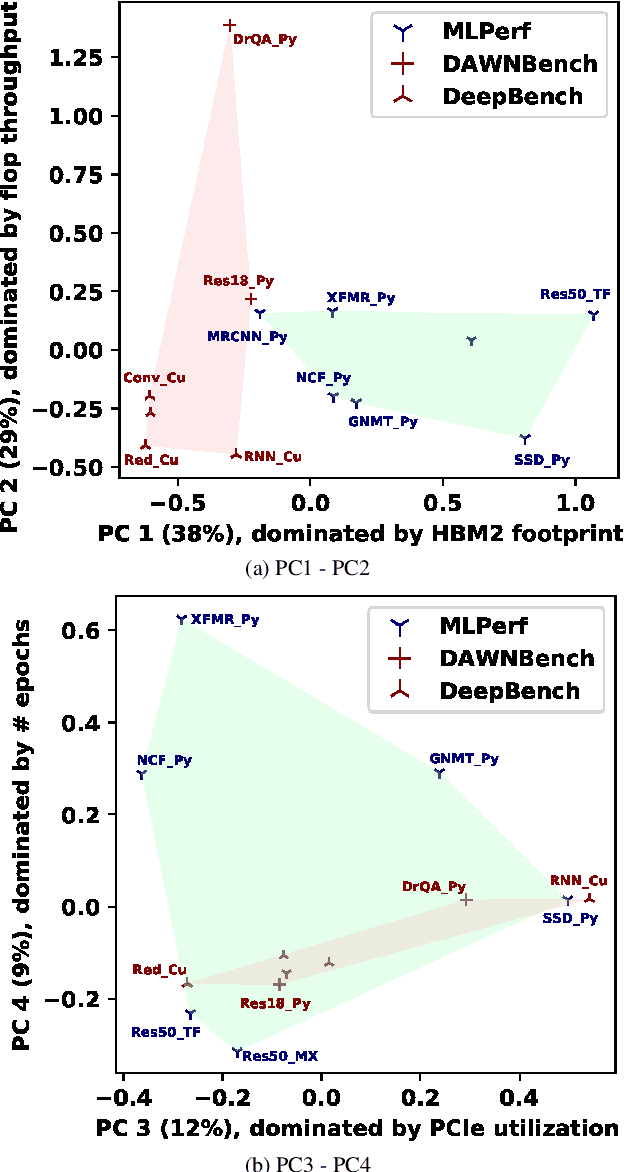
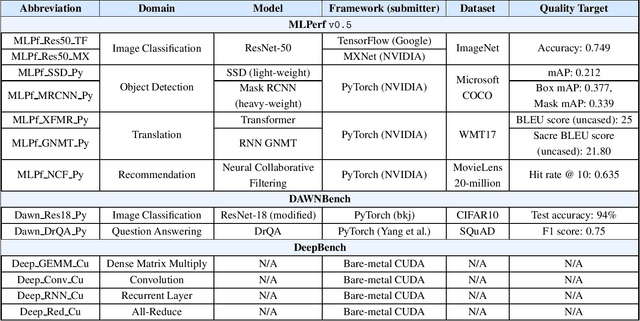
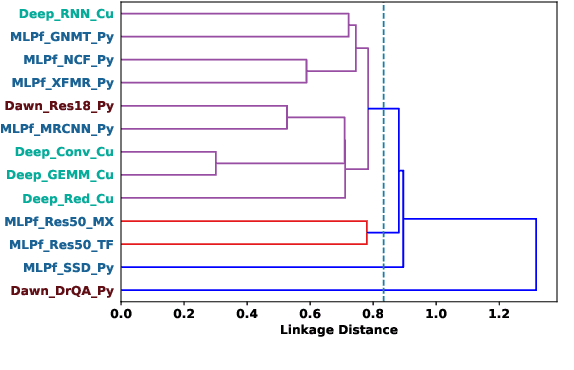
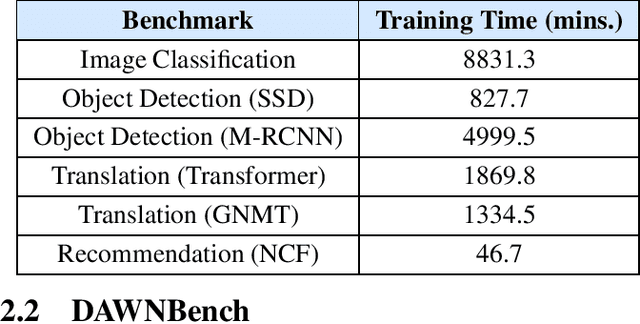
MLPerf, an emerging machine learning benchmark suite strives to cover a broad range of applications of machine learning. We present a study on its characteristics and how the MLPerf benchmarks differ from some of the previous deep learning benchmarks like DAWNBench and DeepBench. We find that application benchmarks such as MLPerf (although rich in kernels) exhibit different features compared to kernel benchmarks such as DeepBench. MLPerf benchmark suite contains a diverse set of models which allows unveiling various bottlenecks in the system. Based on our findings, dedicated low latency interconnect between GPUs in multi-GPU systems is required for optimal distributed deep learning training. We also observe variation in scaling efficiency across the MLPerf models. The variation exhibited by the different models highlight the importance of smart scheduling strategies for multi-GPU training. Another observation is that CPU utilization increases with increase in number of GPUs used for training. Corroborating prior work we also observe and quantify improvements possible by compiler optimizations, mixed-precision training and use of Tensor Cores.