 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Arithmetic to Logic: The Resilience of Logic and Lookup-Based Neural Networks Under Parameter Bit-Flips
Mar 24, 2026The deployment of deep neural networks (DNNs) in safety-critical edge environments necessitates robustness against hardware-induced bit-flip errors. While empirical studies indicate that reducing numerical precision can improve fault tolerance, the theoretical basis of this phenomenon remains underexplored. In this work, we study resilience as a structural property of neural architectures rather than solely as a property of a dataset-specific trained solution. By deriving the expected squared error (MSE) under independent parameter bit flips across multiple numerical formats and layer primitives, we show that lower precision, higher sparsity, bounded activations, and shallow depth are consistently favored under this corruption model. We then argue that logic and lookup-based neural networks realize the joint limit of these design trends. Through ablation studies on the MLPerf Tiny benchmark suite, we show that the observed empirical trends are consistent with the theoretical predictions, and that LUT-based models remain highly stable in corruption regimes where standard floating-point models fail sharply. Furthermore, we identify a novel even-layer recovery effect unique to logic-based architectures and analyze the structural conditions under which it emerges. Overall, our results suggest that shifting from continuous arithmetic weights to discrete Boolean lookups can provide a favorable accuracy-resilience trade-off for hardware fault tolerance.
HELIOS: Adaptive Model And Early-Exit Selection for Efficient LLM Inference Serving
Apr 14, 2025



Deploying large language models (LLMs) presents critical challenges due to the inherent trade-offs associated with key performance metrics, such as latency, accuracy, and throughput. Typically, gains in one metric is accompanied with degradation in others. Early-Exit LLMs (EE-LLMs) efficiently navigate this trade-off space by skipping some of the later model layers when it confidently finds an output token early, thus reducing latency without impacting accuracy. However, as the early exits taken depend on the task and are unknown apriori to request processing, EE-LLMs conservatively load the entire model, limiting resource savings and throughput. Also, current frameworks statically select a model for a user task, limiting our ability to adapt to changing nature of the input queries. We propose HELIOS to address these challenges. First, HELIOS shortlists a set of candidate LLMs, evaluates them using a subset of prompts, gathering telemetry data in real-time. Second, HELIOS uses the early exit data from these evaluations to greedily load the selected model only up to a limited number of layers. This approach yields memory savings which enables us to process more requests at the same time, thereby improving throughput. Third, HELIOS monitors and periodically reassesses the performance of the candidate LLMs and if needed, switches to another model that can service incoming queries more efficiently (such as using fewer layers without lowering accuracy). Our evaluations show that HELIOS achieves 1.48$\times$ throughput, 1.10$\times$ energy-efficiency, 1.39$\times$ lower response time, and 3.7$\times$ improvements in inference batch sizes compared to the baseline, when optimizing for the respective service level objectives.
Shrinking the Giant : Quasi-Weightless Transformers for Low Energy Inference
Nov 04, 2024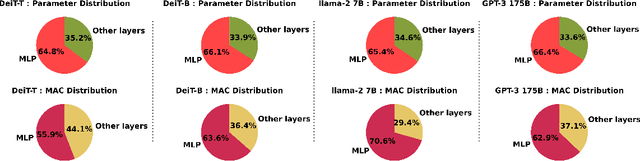

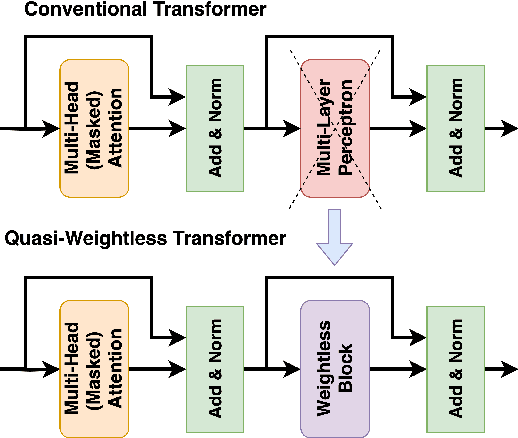
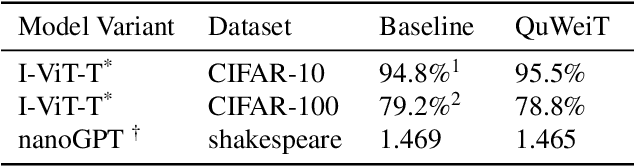
Transformers are set to become ubiquitous with applications ranging from chatbots and educational assistants to visual recognition and remote sensing. However, their increasing computational and memory demands is resulting in growing energy consumption. Building models with fast and energy-efficient inference is imperative to enable a variety of transformer-based applications. Look Up Table (LUT) based Weightless Neural Networks are faster than the conventional neural networks as their inference only involves a few lookup operations. Recently, an approach for learning LUT networks directly via an Extended Finite Difference method was proposed. We build on this idea, extending it for performing the functions of the Multi Layer Perceptron (MLP) layers in transformer models and integrating them with transformers to propose Quasi Weightless Transformers (QuWeiT). This allows for a computational and energy-efficient inference solution for transformer-based models. On I-ViT-T, we achieve a comparable accuracy of 95.64% on CIFAR-10 dataset while replacing approximately 55% of all the multiplications in the entire model and achieving a 2.2x energy efficiency. We also observe similar savings on experiments with the nanoGPT framework.
ViTA: A Vision Transformer Inference Accelerator for Edge Applications
Feb 17, 2023Vision Transformer models, such as ViT, Swin Transformer, and Transformer-in-Transformer, have recently gained significant traction in computer vision tasks due to their ability to capture the global relation between features which leads to superior performance. However, they are compute-heavy and difficult to deploy in resource-constrained edge devices. Existing hardware accelerators, including those for the closely-related BERT transformer models, do not target highly resource-constrained environments. In this paper, we address this gap and propose ViTA - a configurable hardware accelerator for inference of vision transformer models, targeting resource-constrained edge computing devices and avoiding repeated off-chip memory accesses. We employ a head-level pipeline and inter-layer MLP optimizations, and can support several commonly used vision transformer models with changes solely in our control logic. We achieve nearly 90% hardware utilization efficiency on most vision transformer models, report a power of 0.88W when synthesised with a clock of 150 MHz, and get reasonable frame rates - all of which makes ViTA suitable for edge applications.