 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTA: A Vision Transformer Inference Accelerator for Edge Applications
Feb 17, 2023Vision Transformer models, such as ViT, Swin Transformer, and Transformer-in-Transformer, have recently gained significant traction in computer vision tasks due to their ability to capture the global relation between features which leads to superior performance. However, they are compute-heavy and difficult to deploy in resource-constrained edge devices. Existing hardware accelerators, including those for the closely-related BERT transformer models, do not target highly resource-constrained environments. In this paper, we address this gap and propose ViTA - a configurable hardware accelerator for inference of vision transformer models, targeting resource-constrained edge computing devices and avoiding repeated off-chip memory accesses. We employ a head-level pipeline and inter-layer MLP optimizations, and can support several commonly used vision transformer models with changes solely in our control logic. We achieve nearly 90% hardware utilization efficiency on most vision transformer models, report a power of 0.88W when synthesised with a clock of 150 MHz, and get reasonable frame rates - all of which makes ViTA suitable for edge applications.
Probabilistic spike propagation for FPGA implementation of spiking neural networks
Jan 07, 2020

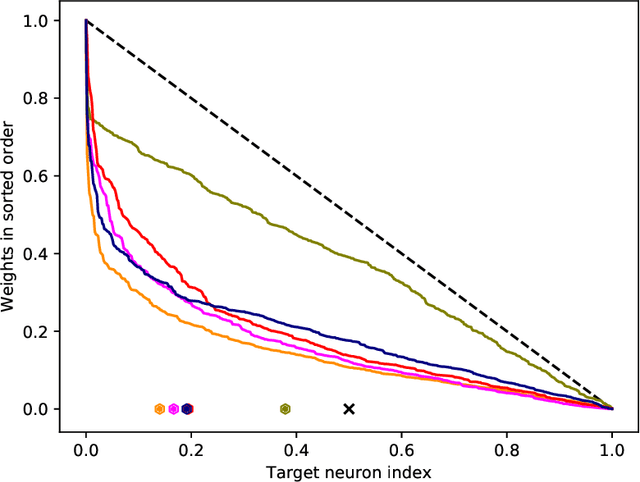
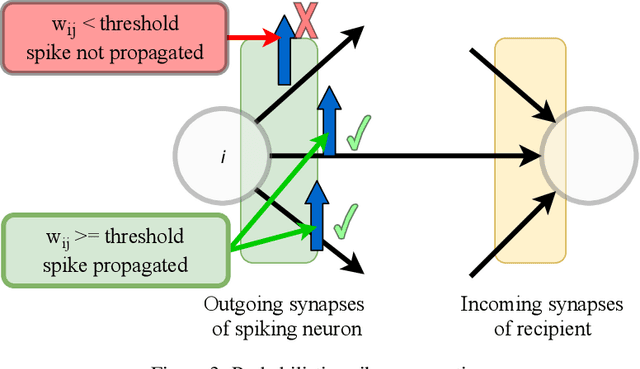
Evaluation of spiking neural networks requires fetching a large number of synaptic weights to update postsynaptic neurons. This limits parallelism and becomes a bottleneck for hardware. We present an approach for spike propagation based on a probabilistic interpretation of weights, thus reducing memory accesses and updates. We study the effects of introducing randomness into the spike processing, and show on benchmark networks that this can be done with minimal impact on the recognition accuracy. We present an architecture and the trade-offs in accuracy on fully connected and convolutional networks for the MNIST and CIFAR10 datasets on the Xilinx Zynq platform.