 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELIOS: Adaptive Model And Early-Exit Selection for Efficient LLM Inference Serving
Apr 14, 2025



Deploying large language models (LLMs) presents critical challenges due to the inherent trade-offs associated with key performance metrics, such as latency, accuracy, and throughput. Typically, gains in one metric is accompanied with degradation in others. Early-Exit LLMs (EE-LLMs) efficiently navigate this trade-off space by skipping some of the later model layers when it confidently finds an output token early, thus reducing latency without impacting accuracy. However, as the early exits taken depend on the task and are unknown apriori to request processing, EE-LLMs conservatively load the entire model, limiting resource savings and throughput. Also, current frameworks statically select a model for a user task, limiting our ability to adapt to changing nature of the input queries. We propose HELIOS to address these challenges. First, HELIOS shortlists a set of candidate LLMs, evaluates them using a subset of prompts, gathering telemetry data in real-time. Second, HELIOS uses the early exit data from these evaluations to greedily load the selected model only up to a limited number of layers. This approach yields memory savings which enables us to process more requests at the same time, thereby improving throughput. Third, HELIOS monitors and periodically reassesses the performance of the candidate LLMs and if needed, switches to another model that can service incoming queries more efficiently (such as using fewer layers without lowering accuracy). Our evaluations show that HELIOS achieves 1.48$\times$ throughput, 1.10$\times$ energy-efficiency, 1.39$\times$ lower response time, and 3.7$\times$ improvements in inference batch sizes compared to the baseline, when optimizing for the respective service level objectives.
Enabling and Accelerating Dynamic Vision Transformer Inference for Real-Time Applications
Dec 06, 2022Many state-of-the-art deep learning models for computer vision tasks are based on the transformer architecture. Such models can be computationally expensive and are typically statically set to meet the deployment scenario. However, in real-time applications, the resources available for every inference can vary considerably and be smaller than what state-of-the-art models use. We can use dynamic models to adapt the model execution to meet real-time application resource constraints. While prior dynamic work has primarily minimized resource utilization for less complex input images while maintaining accuracy and focused on CNNs and early transformer models such as BERT, we adapt vision transformers to meet system dynamic resource constraints, independent of the input image. We find that unlike early transformer models, recent state-of-the-art vision transformers heavily rely on convolution layers. We show that pretrained models are fairly resilient to skipping computation in the convolution and self-attention layers, enabling us to create a low-overhead system for dynamic real-time inference without additional training. Finally, we create a optimized accelerator for these dynamic vision transformers in a 5nm technology. The PE array occupies 2.26mm$^2$ and is 17 times faster than a NVIDIA TITAN V GPU for state-of-the-art transformer-based models for semantic segmentation.
Structurally Sparsified Backward Propagation for Faster Long Short-Term Memory Training
Jun 01, 2018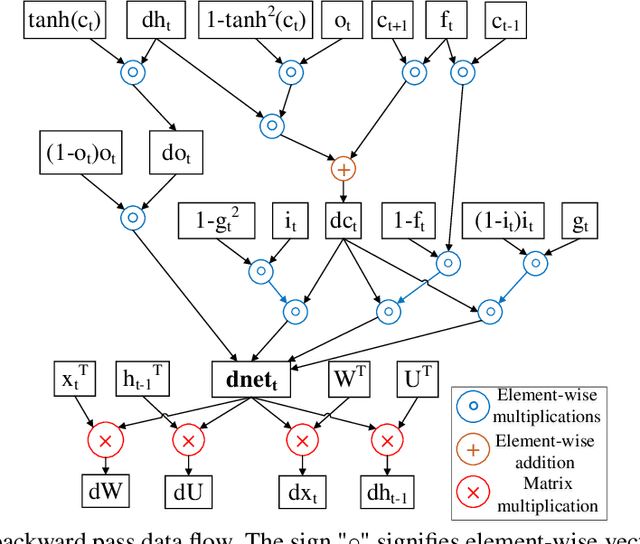
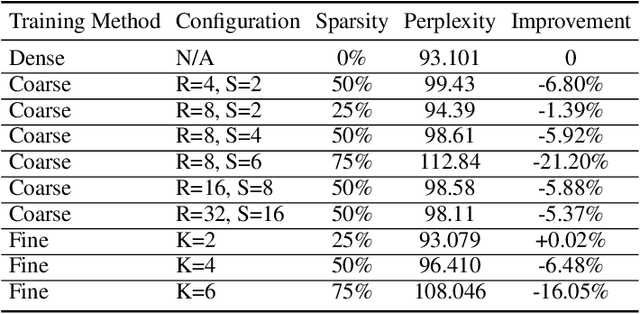
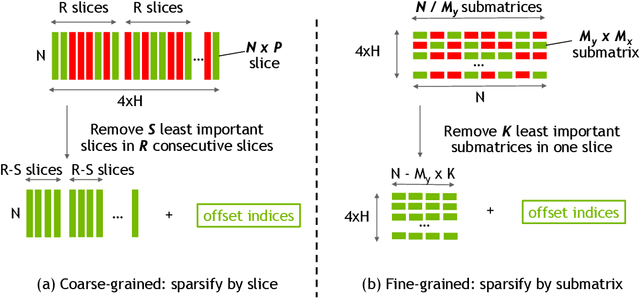
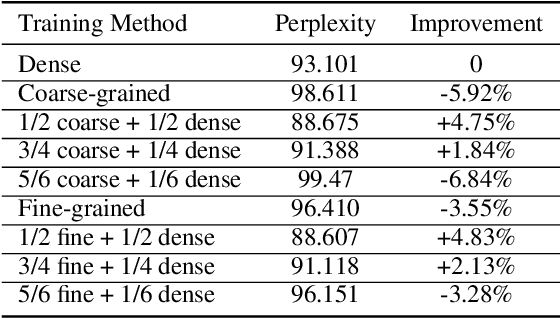
Exploiting sparsity enables hardware systems to run neural networks faster and more energy-efficiently. However, most prior sparsity-centric optimization techniques only accelerate the forward pass of neural networks and usually require an even longer training process with iterative pruning and retraining. We observe that artificially inducing sparsity in the gradients of the gates in an LSTM cell has little impact on the training quality. Further, we can enforce structured sparsity in the gate gradients to make the LSTM backward pass up to 45% faster than the state-of-the-art dense approach and 168% faster than the state-of-the-art sparsifying method on modern GPUs. Though the structured sparsifying method can impact the accuracy of a model, this performance gap can be eliminated by mixing our sparse training method and the standard dense training method. Experimental results show that the mixed method can achieve comparable results in a shorter time span than using purely dense training.
Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPU
Mar 02, 2017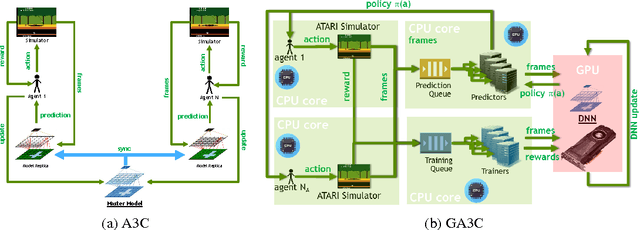


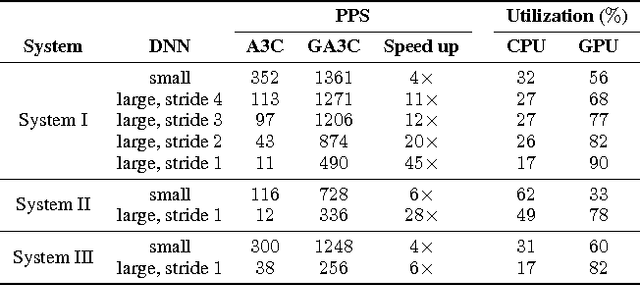
We introduce a hybrid CPU/GPU version of the Asynchronous Advantage Actor-Critic (A3C) algorithm, currently the state-of-the-art method in reinforcement learning for various gaming tasks. We analyze its computational traits and concentrate on aspects critical to leveraging the GPU's computational power. We introduce a system of queues and a dynamic scheduling strategy, potentially helpful for other asynchronous algorithms as well. Our hybrid CPU/GPU version of A3C, based on TensorFlow, achieves a significant speed up compared to a CPU implementation; we make it publicly available to other researchers at https://github.com/NVlabs/GA3C .
vDNN: Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design
Jul 28, 2016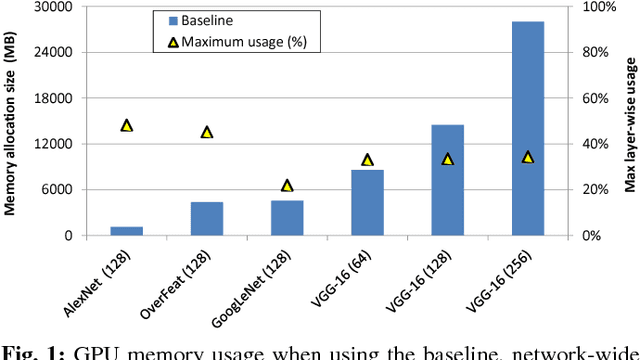
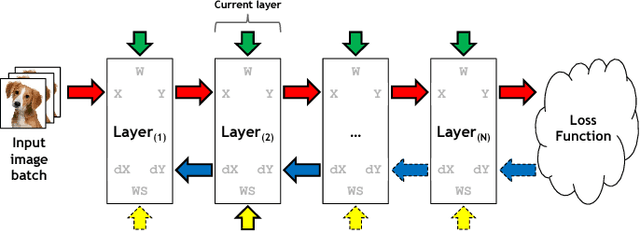
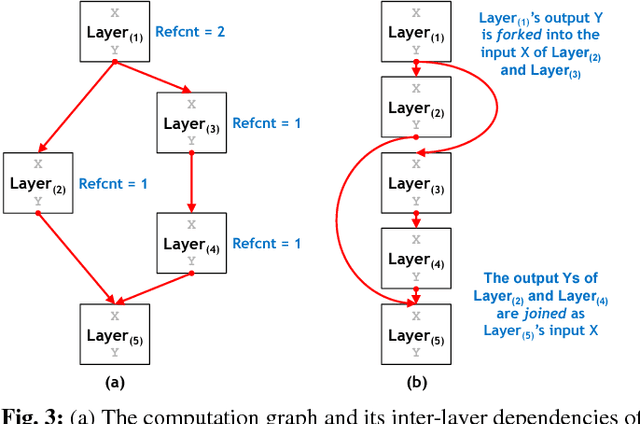
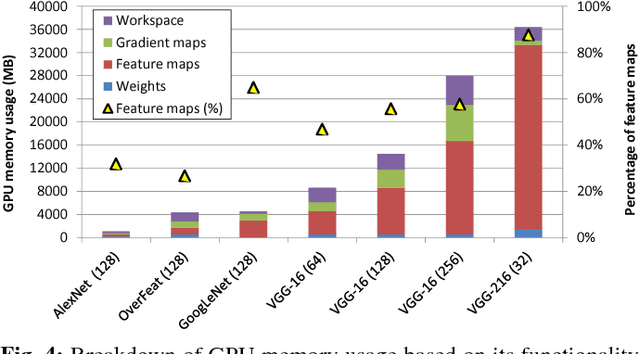
The most widely used machine learning frameworks require users to carefully tune their memory usage so that the deep neural network (DNN) fits into the DRAM capacity of a GPU. This restriction hampers a researcher's flexibility to study different machine learning algorithms, forcing them to either use a less desirable network architecture or parallelize the processing across multiple GPUs. We propose a runtime memory manager that virtualizes the memory usage of DNNs such that both GPU and CPU memory can simultaneously be utilized for training larger DNNs. Our virtualized DNN (vDNN) reduces the average GPU memory usage of AlexNet by up to 89%, OverFeat by 91%, and GoogLeNet by 95%, a significant reduction in memory requirements of DNNs. Similar experiments on VGG-16, one of the deepest and memory hungry DNNs to date, demonstrate the memory-efficiency of our proposal. vDNN enables VGG-16 with batch size 256 (requiring 28 GB of memory) to be trained on a single NVIDIA Titan X GPU card containing 12 GB of memory, with 18% performance loss compared to a hypothetical, oracular GPU with enough memory to hold the entire DNN.