 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparse Graph for Efficient Deep Learning
Oct 01, 2018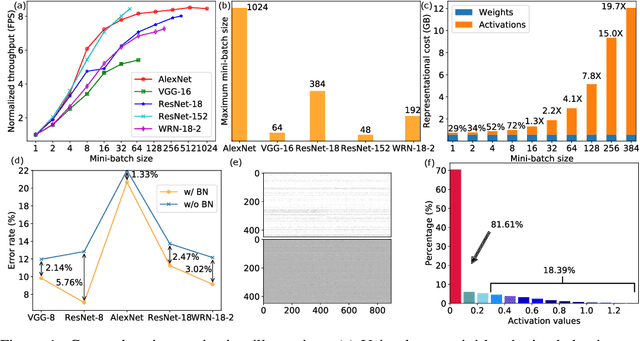
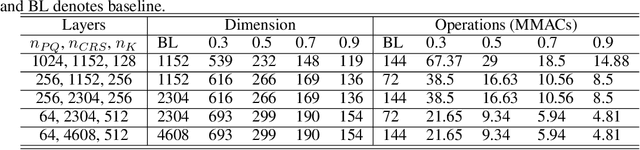
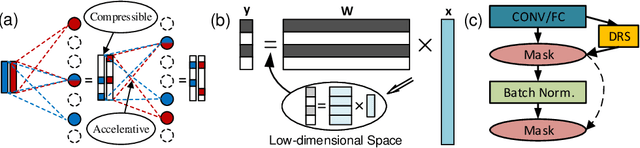
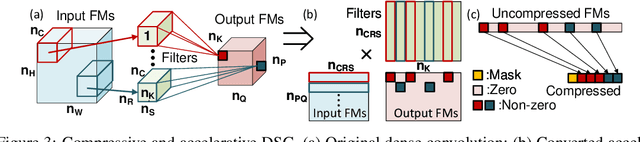
We propose to execute deep neural networks (DNNs) with dynamic and sparse graph (DSG) structure for compressive memory and accelerative execution during both training and inference. The great success of DNNs motivates the pursuing of lightweight models for the deployment onto embedded devices. However, most of the previous studies optimize for inference while neglect training or even complicate it. Training is far more intractable, since (i) the neurons dominate the memory cost rather than the weights in inference; (ii) the dynamic activation makes previous sparse acceleration via one-off optimization on fixed weight invalid; (iii) batch normalization (BN) is critical for maintaining accuracy while its activation reorganization damages the sparsity. To address these issues, DSG activates only a small amount of neurons with high selectivity at each iteration via a dimension-reduction search (DRS) and obtains the BN compatibility via a double-mask selection (DMS). Experiments show significant memory saving (1.7-4.5x) and operation reduction (2.3-4.4x) with little accuracy loss on various benchmarks.
Structurally Sparsified Backward Propagation for Faster Long Short-Term Memory Training
Jun 01, 2018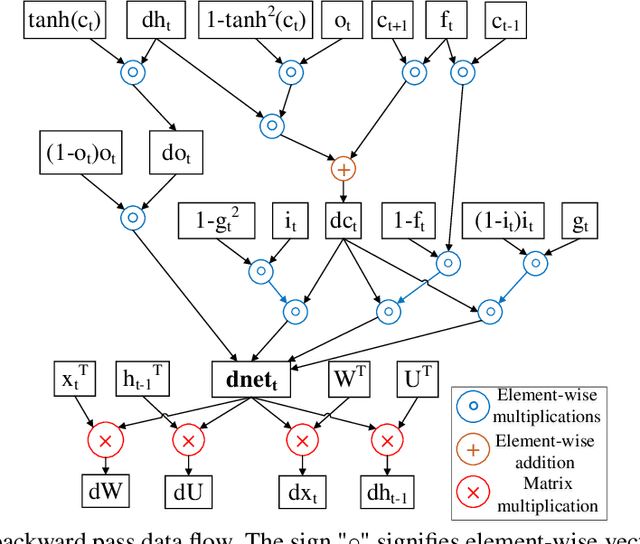
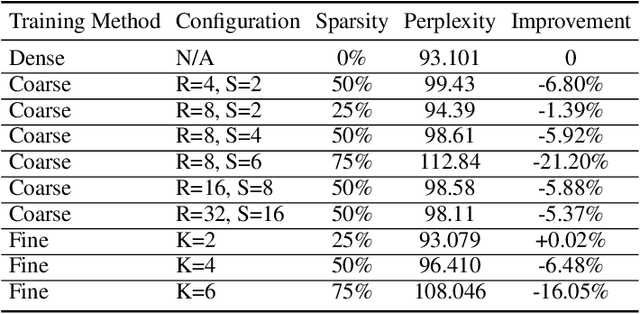
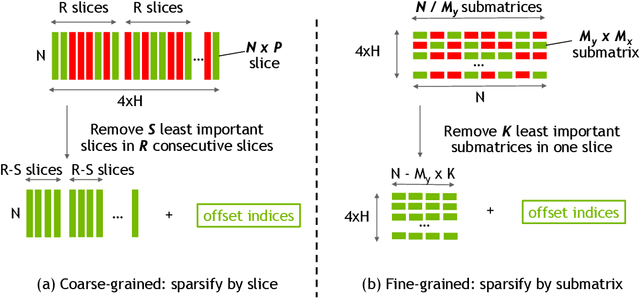
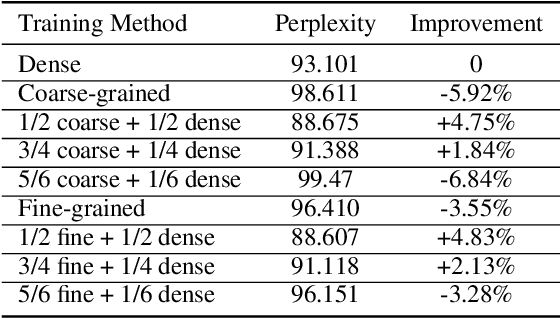
Exploiting sparsity enables hardware systems to run neural networks faster and more energy-efficiently. However, most prior sparsity-centric optimization techniques only accelerate the forward pass of neural networks and usually require an even longer training process with iterative pruning and retraining. We observe that artificially inducing sparsity in the gradients of the gates in an LSTM cell has little impact on the training quality. Further, we can enforce structured sparsity in the gate gradients to make the LSTM backward pass up to 45% faster than the state-of-the-art dense approach and 168% faster than the state-of-the-art sparsifying method on modern GPUs. Though the structured sparsifying method can impact the accuracy of a model, this performance gap can be eliminated by mixing our sparse training method and the standard dense training method. Experimental results show that the mixed method can achieve comparable results in a shorter time span than using purely dense training.
CNNLab: a Novel Parallel Framework for Neural Networks using GPU and FPGA-a Practical Study with Trade-off Analysis
Jun 20, 2016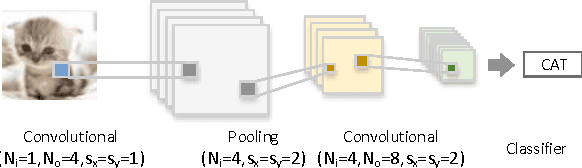
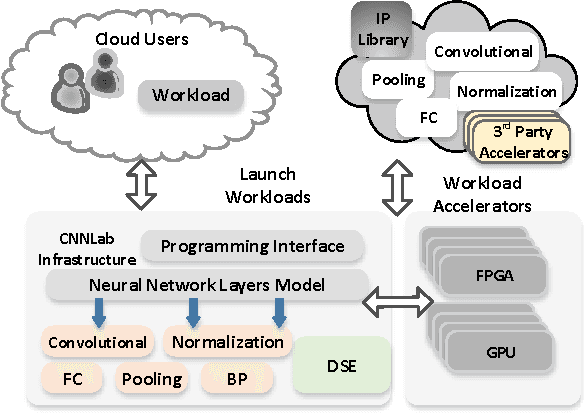
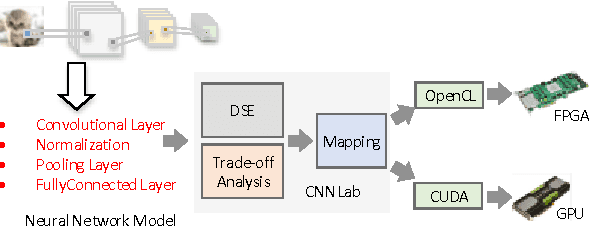
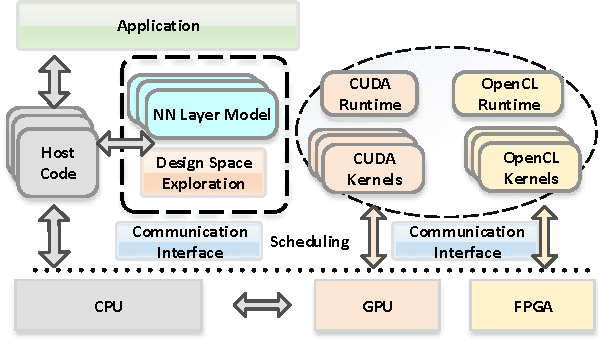
Designing and implementing efficient, provably correct parallel neural network processing is challenging. Existing high-level parallel abstractions like MapReduce are insufficiently expressive while low-level tools like MPI and Pthreads leave ML experts repeatedly solving the same design challenges. However, the diversity and large-scale data size have posed a significant challenge to construct a flexible and high-performance implementation of deep learning neural networks. To improve the performance and maintain the scalability, we present CNNLab, a novel deep learning framework using GPU and FPGA-based accelerators. CNNLab provides a uniform programming model to users so that the hardware implementation and the scheduling are invisible to the programmers. At runtime, CNNLab leverages the trade-offs between GPU and FPGA before offloading the tasks to the accelerators. Experimental results on the state-of-the-art Nvidia K40 GPU and Altera DE5 FPGA board demonstrate that the CNNLab can provide a universal framework with efficient support for diverse applications without increasing the burden of the programmers. Moreover, we analyze the detailed quantitative performance, throughput, power, energy, and performance density for both approaches. Experimental results leverage the trade-offs between GPU and FPGA and provide useful practical experiences for the deep learning research community.