 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNNLab: a Novel Parallel Framework for Neural Networks using GPU and FPGA-a Practical Study with Trade-off Analysis
Paper and Code
Jun 20, 2016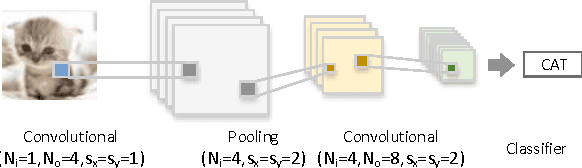
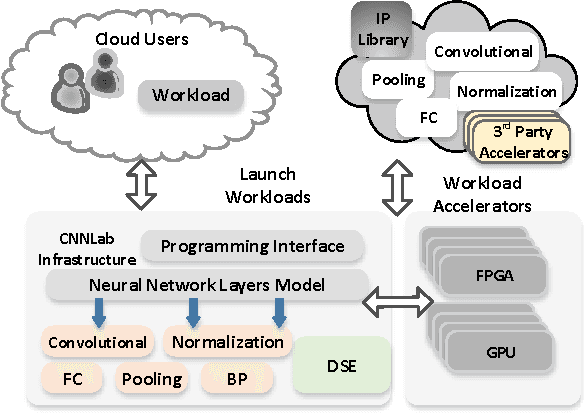
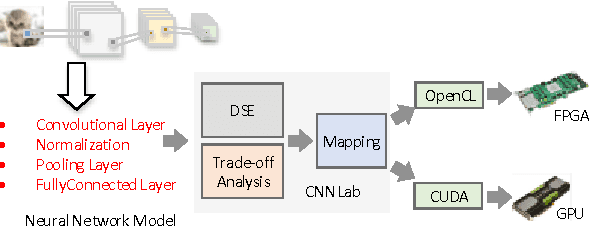
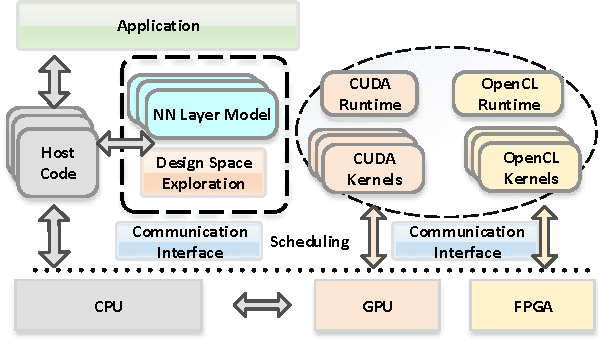
Designing and implementing efficient, provably correct parallel neural network processing is challenging. Existing high-level parallel abstractions like MapReduce are insufficiently expressive while low-level tools like MPI and Pthreads leave ML experts repeatedly solving the same design challenges. However, the diversity and large-scale data size have posed a significant challenge to construct a flexible and high-performance implementation of deep learning neural networks. To improve the performance and maintain the scalability, we present CNNLab, a novel deep learning framework using GPU and FPGA-based accelerators. CNNLab provides a uniform programming model to users so that the hardware implementation and the scheduling are invisible to the programmers. At runtime, CNNLab leverages the trade-offs between GPU and FPGA before offloading the tasks to the accelerators. Experimental results on the state-of-the-art Nvidia K40 GPU and Altera DE5 FPGA board demonstrate that the CNNLab can provide a universal framework with efficient support for diverse applications without increasing the burden of the programmers. Moreover, we analyze the detailed quantitative performance, throughput, power, energy, and performance density for both approaches. Experimental results leverage the trade-offs between GPU and FPGA and provide useful practical experiences for the deep learning research community.