 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Arithmetic to Logic: The Resilience of Logic and Lookup-Based Neural Networks Under Parameter Bit-Flips
Mar 24, 2026The deployment of deep neural networks (DNNs) in safety-critical edge environments necessitates robustness against hardware-induced bit-flip errors. While empirical studies indicate that reducing numerical precision can improve fault tolerance, the theoretical basis of this phenomenon remains underexplored. In this work, we study resilience as a structural property of neural architectures rather than solely as a property of a dataset-specific trained solution. By deriving the expected squared error (MSE) under independent parameter bit flips across multiple numerical formats and layer primitives, we show that lower precision, higher sparsity, bounded activations, and shallow depth are consistently favored under this corruption model. We then argue that logic and lookup-based neural networks realize the joint limit of these design trends. Through ablation studies on the MLPerf Tiny benchmark suite, we show that the observed empirical trends are consistent with the theoretical predictions, and that LUT-based models remain highly stable in corruption regimes where standard floating-point models fail sharply. Furthermore, we identify a novel even-layer recovery effect unique to logic-based architectures and analyze the structural conditions under which it emerges. Overall, our results suggest that shifting from continuous arithmetic weights to discrete Boolean lookups can provide a favorable accuracy-resilience trade-off for hardware fault tolerance.
Design Space Exploration of DMA based Finer-Grain Compute Communication Overlap
Dec 11, 2025As both ML training and inference are increasingly distributed, parallelization techniques that shard (divide) ML model across GPUs of a distributed system, are often deployed. With such techniques, there is a high prevalence of data-dependent communication and computation operations where communication is exposed, leaving as high as 1.7x ideal performance on the table. Prior works harness the fact that ML model state and inputs are already sharded, and employ careful overlap of individual computation/communication shards. While such coarse-grain overlap is promising, in this work, we instead make a case for finer-grain compute-communication overlap which we term FiCCO, where we argue for finer-granularity, one-level deeper overlap than at shard-level, to unlock compute/communication overlap for a wider set of network topologies, finer-grain dataflow and more. We show that FiCCO opens up a wider design space of execution schedules than possible at shard-level alone. At the same time, decomposition of ML operations into smaller operations (done in both shard-based and finer-grain techniques) causes operation-level inefficiency losses. To balance the two, we first present a detailed characterization of these inefficiency losses, then present a design space of FiCCO schedules, and finally overlay the schedules with concomitant inefficiency signatures. Doing so helps us design heuristics that frameworks and runtimes can harness to select bespoke FiCCO schedules based on the nature of underlying ML operations. Finally, to further minimize contention inefficiencies inherent with operation overlap, we offload communication to GPU DMA engines. We evaluate several scenarios from realistic ML deployments and demonstrate that our proposed bespoke schedules deliver up to 1.6x speedup and our heuristics provide accurate guidance in 81% of unseen scenarios.
Shrinking the Giant : Quasi-Weightless Transformers for Low Energy Inference
Nov 04, 2024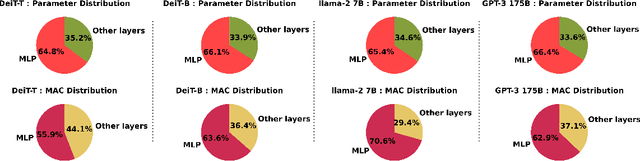

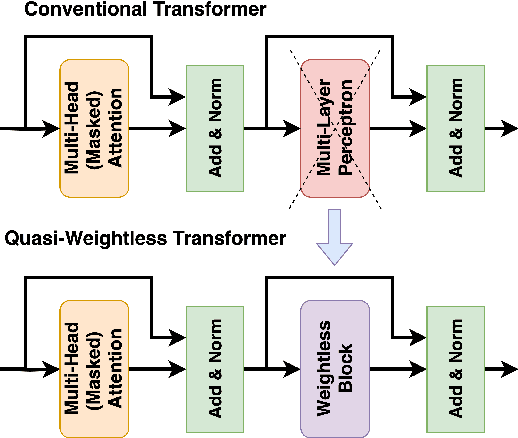
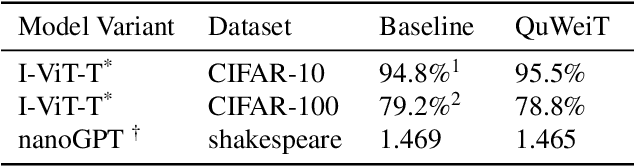
Transformers are set to become ubiquitous with applications ranging from chatbots and educational assistants to visual recognition and remote sensing. However, their increasing computational and memory demands is resulting in growing energy consumption. Building models with fast and energy-efficient inference is imperative to enable a variety of transformer-based applications. Look Up Table (LUT) based Weightless Neural Networks are faster than the conventional neural networks as their inference only involves a few lookup operations. Recently, an approach for learning LUT networks directly via an Extended Finite Difference method was proposed. We build on this idea, extending it for performing the functions of the Multi Layer Perceptron (MLP) layers in transformer models and integrating them with transformers to propose Quasi Weightless Transformers (QuWeiT). This allows for a computational and energy-efficient inference solution for transformer-based models. On I-ViT-T, we achieve a comparable accuracy of 95.64% on CIFAR-10 dataset while replacing approximately 55% of all the multiplications in the entire model and achieving a 2.2x energy efficiency. We also observe similar savings on experiments with the nanoGPT framework.
Differentiable Weightless Neural Networks
Oct 14, 2024We introduce the Differentiable Weightless Neural Network (DWN), a model based on interconnected lookup tables. Training of DWNs is enabled by a novel Extended Finite Difference technique for approximate differentiation of binary values. We propose Learnable Mapping, Learnable Reduction, and Spectral Regularization to further improve the accuracy and efficiency of these models. We evaluate DWNs in three edge computing contexts: (1) an FPGA-based hardware accelerator, where they demonstrate superior latency, throughput, energy efficiency, and model area compared to state-of-the-art solutions, (2) a low-power microcontroller, where they achieve preferable accuracy to XGBoost while subject to stringent memory constraints, and (3) ultra-low-cost chips, where they consistently outperform small models in both accuracy and projected hardware area. DWNs also compare favorably against leading approaches for tabular datasets, with higher average rank. Overall, our work positions DWNs as a pioneering solution for edge-compatible high-throughput neural networks.
ULEEN: A Novel Architecture for Ultra Low-Energy Edge Neural Networks
Apr 20, 2023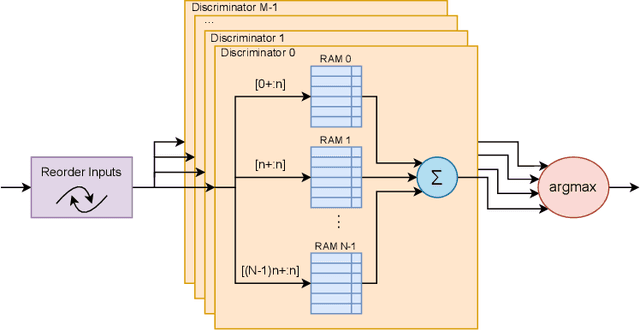
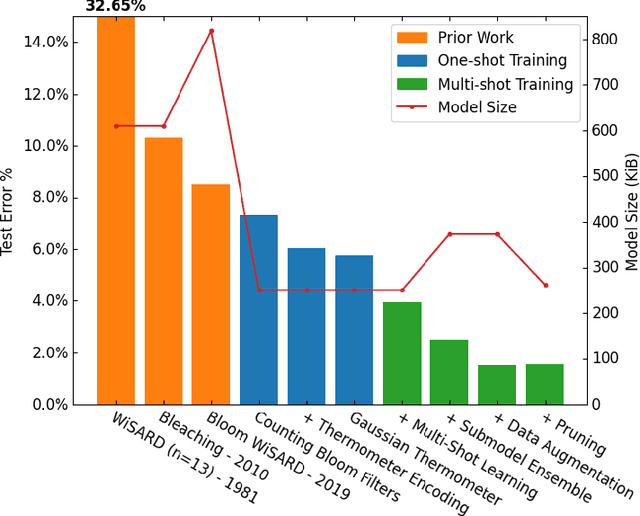
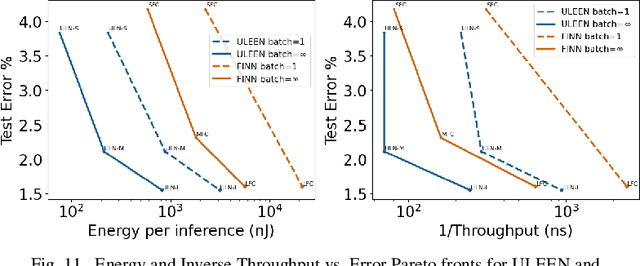
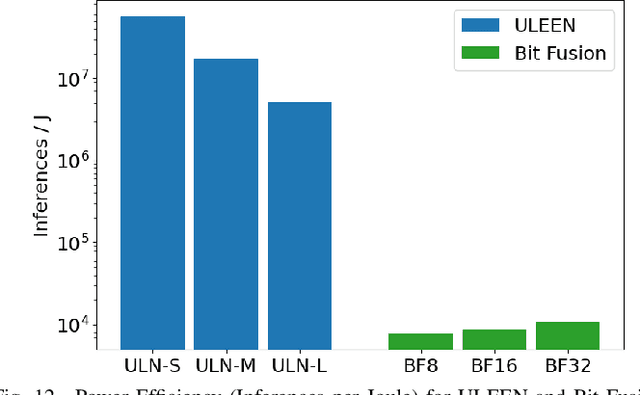
The deployment of AI models on low-power, real-time edge devices requires accelerators for which energy, latency, and area are all first-order concerns. There are many approaches to enabling deep neural networks (DNNs) in this domain, including pruning, quantization, compression, and binary neural networks (BNNs), but with the emergence of the "extreme edge", there is now a demand for even more efficient models. In order to meet the constraints of ultra-low-energy devices, we propose ULEEN, a model architecture based on weightless neural networks. Weightless neural networks (WNNs) are a class of neural model which use table lookups, not arithmetic, to perform computation. The elimination of energy-intensive arithmetic operations makes WNNs theoretically well suited for edge inference; however, they have historically suffered from poor accuracy and excessive memory usage. ULEEN incorporates algorithmic improvements and a novel training strategy inspired by BNNs to make significant strides in improving accuracy and reducing model size. We compare FPGA and ASIC implementations of an inference accelerator for ULEEN against edge-optimized DNN and BNN devices. On a Xilinx Zynq Z-7045 FPGA, we demonstrate classification on the MNIST dataset at 14.3 million inferences per second (13 million inferences/Joule) with 0.21 $\mu$s latency and 96.2% accuracy, while Xilinx FINN achieves 12.3 million inferences per second (1.69 million inferences/Joule) with 0.31 $\mu$s latency and 95.83% accuracy. In a 45nm ASIC, we achieve 5.1 million inferences/Joule and 38.5 million inferences/second at 98.46% accuracy, while a quantized Bit Fusion model achieves 9230 inferences/Joule and 19,100 inferences/second at 99.35% accuracy. In our search for ever more efficient edge devices, ULEEN shows that WNNs are deserving of consideration.
HLSDataset: Open-Source Dataset for ML-Assisted FPGA Design using High Level Synthesis
Feb 17, 2023Machine Learning (ML) has been widely adopted in design exploration using high level synthesis (HLS) to give a better and faster performance, and resource and power estimation at very early stages for FPGA-based design. To perform prediction accurately, high-quality and large-volume datasets are required for training ML models.This paper presents a dataset for ML-assisted FPGA design using HLS, called HLSDataset. The dataset is generated from widely used HLS C benchmarks including Polybench, Machsuite, CHStone and Rossetta. The Verilog samples are generated with a variety of directives including loop unroll, loop pipeline and array partition to make sure optimized and realistic designs are covered. The total number of generated Verilog samples is nearly 9,000 per FPGA type. To demonstrate the effectiveness of our dataset, we undertake case studies to perform power estimation and resource usage estimation with ML models trained with our dataset. All the codes and dataset are public at the github repo.We believe that HLSDataset can save valuable time for researchers by avoiding the tedious process of running tools, scripting and parsing files to generate the dataset, and enable them to spend more time where it counts, that is, in training ML models.
Weightless Neural Networks for Efficient Edge Inference
Mar 03, 2022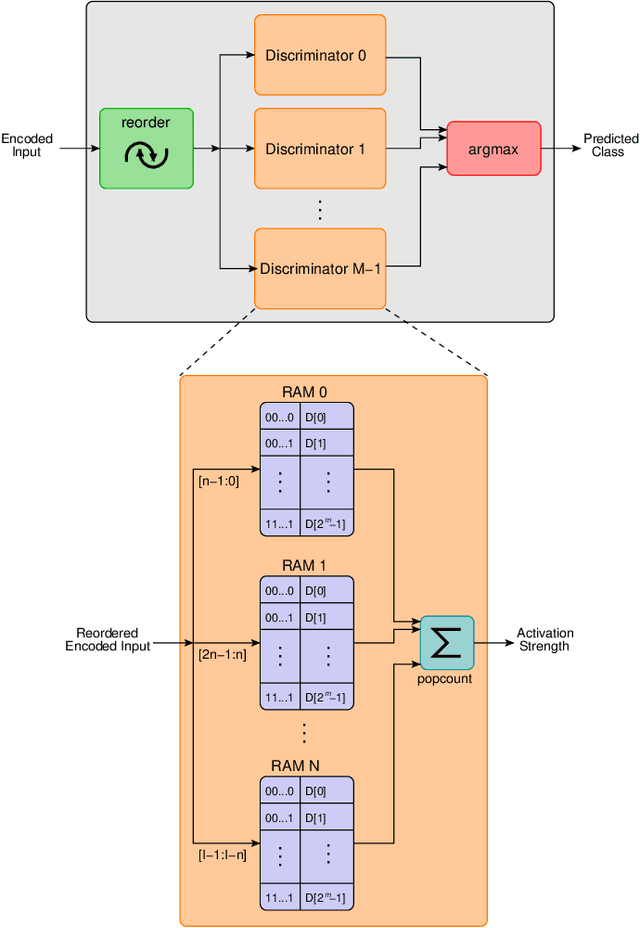
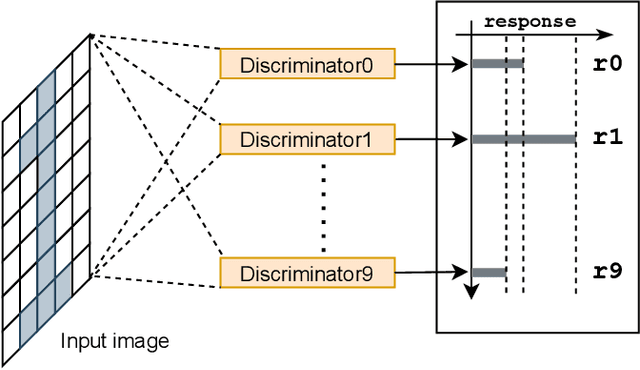
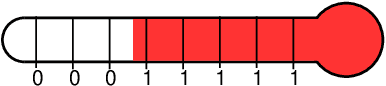
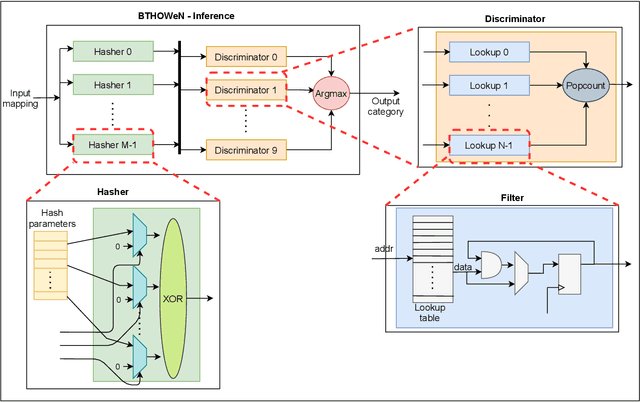
Weightless Neural Networks (WNNs) are a class of machine learning model which use table lookups to perform inference. This is in contrast with Deep Neural Networks (DNNs), which use multiply-accumulate operations. State-of-the-art WNN architectures have a fraction of the implementation cost of DNNs, but still lag behind them on accuracy for common image recognition tasks. Additionally, many existing WNN architectures suffer from high memory requirements. In this paper, we propose a novel WNN architecture, BTHOWeN, with key algorithmic and architectural improvements over prior work, namely counting Bloom filters, hardware-friendly hashing, and Gaussian-based nonlinear thermometer encodings to improve model accuracy and reduce area and energy consumption. BTHOWeN targets the large and growing edge computing sector by providing superior latency and energy efficiency to comparable quantized DNNs. Compared to state-of-the-art WNNs across nine classification datasets, BTHOWeN on average reduces error by more than than 40% and model size by more than 50%. We then demonstrate the viability of the BTHOWeN architecture by presenting an FPGA-based accelerator, and compare its latency and resource usage against similarly accurate quantized DNN accelerators, including Multi-Layer Perceptron (MLP) and convolutional models. The proposed BTHOWeN models consume almost 80% less energy than the MLP models, with nearly 85% reduction in latency. In our quest for efficient ML on the edge, WNNs are clearly deserving of additional attention.
Neuro-Symbolic AI: An Emerging Class of AI Workloads and their Characterization
Sep 13, 2021

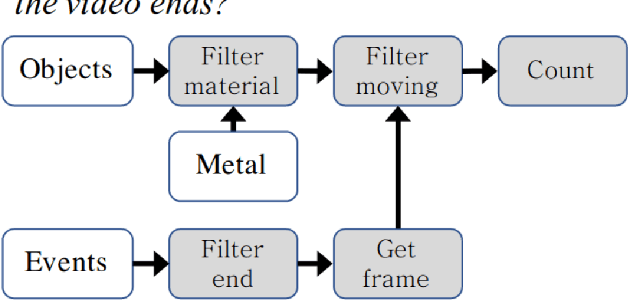
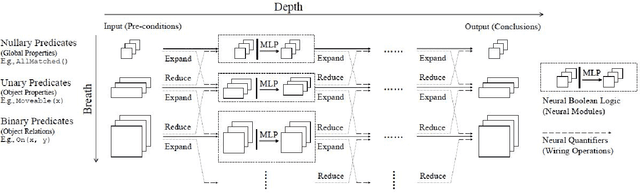
Neuro-symbolic artificial intelligence is a novel area of AI research which seeks to combine traditional rules-based AI approaches with modern deep learning techniques. Neuro-symbolic models have already demonstrated the capability to outperform state-of-the-art deep learning models in domains such as image and video reasoning. They have also been shown to obtain high accuracy with significantly less training data than traditional models. Due to the recency of the field's emergence and relative sparsity of published results, the performance characteristics of these models are not well understood. In this paper, we describe and analyze the performance characteristics of three recent neuro-symbolic models. We find that symbolic models have less potential parallelism than traditional neural models due to complex control flow and low-operational-intensity operations, such as scalar multiplication and tensor addition. However, the neural aspect of computation dominates the symbolic part in cases where they are clearly separable. We also find that data movement poses a potential bottleneck, as it does in many ML workloads.
Compute RAMs: Adaptable Compute and Storage Blocks for DL-Optimized FPGAs
Jul 19, 2021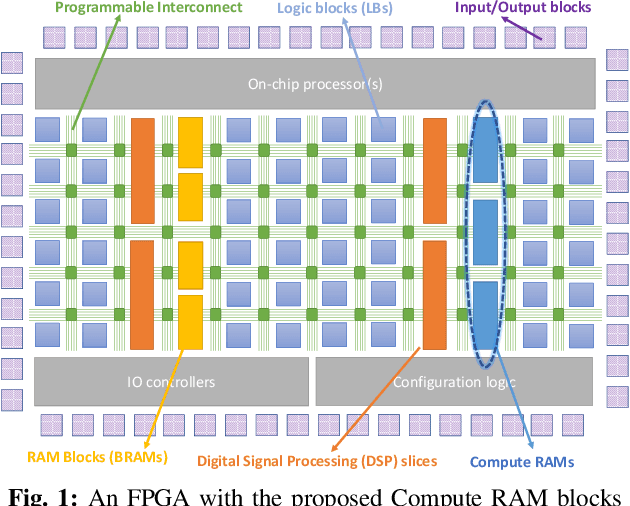
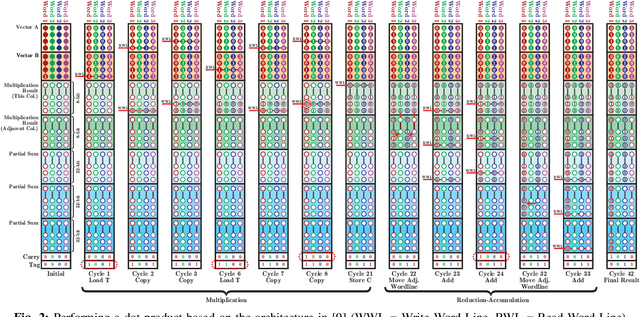

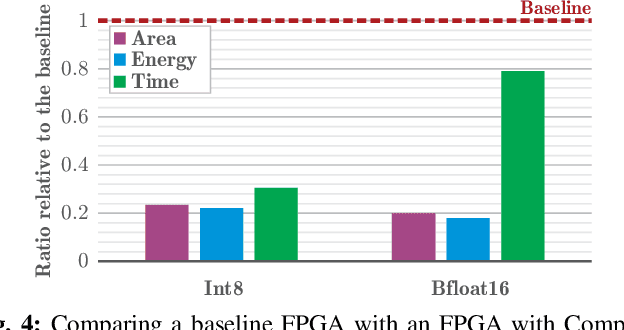
The configurable building blocks of current FPGAs -- Logic blocks (LBs), Digital Signal Processing (DSP) slices, and Block RAMs (BRAMs) -- make them efficient hardware accelerators for the rapid-changing world of Deep Learning (DL). Communication between these blocks happens through an interconnect fabric consisting of switching elements spread throughout the FPGA. In this paper, a new block, Compute RAM, is proposed. Compute RAMs provide highly-parallel processing-in-memory (PIM) by combining computation and storage capabilities in one block. Compute RAMs can be integrated in the FPGA fabric just like the existing FPGA blocks and provide two modes of operation (storage or compute) that can be dynamically chosen. They reduce power consumption by reducing data movement, provide adaptable precision support, and increase the effective on-chip memory bandwidth. Compute RAMs also help increase the compute density of FPGAs. In our evaluation of addition, multiplication and dot-product operations across multiple data precisions (int4, int8 and bfloat16), we observe an average savings of 80% in energy consumption, and an improvement in execution time ranging from 20% to 80%. Adding Compute RAMs can benefit non-DL applications as well, and make FPGAs more efficient, flexible, and performant accelerators.
Demystifying the MLPerf Benchmark Suite
Aug 24, 2019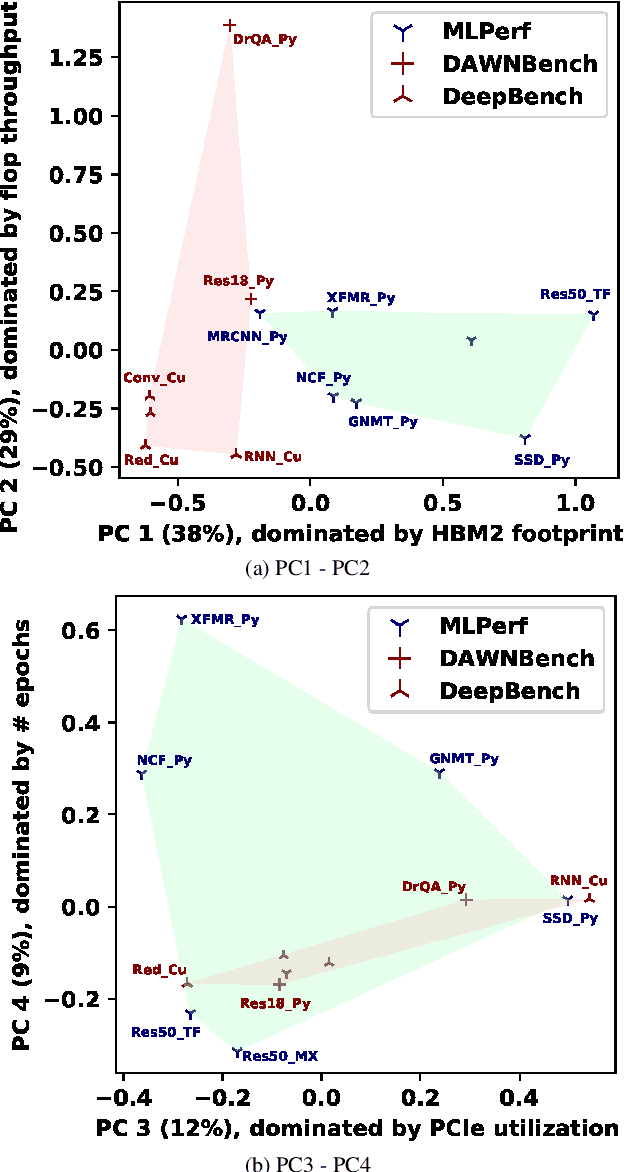
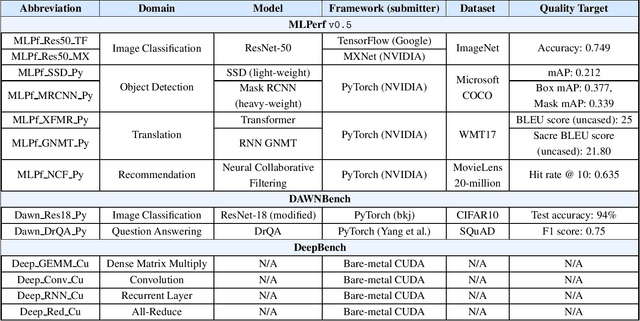
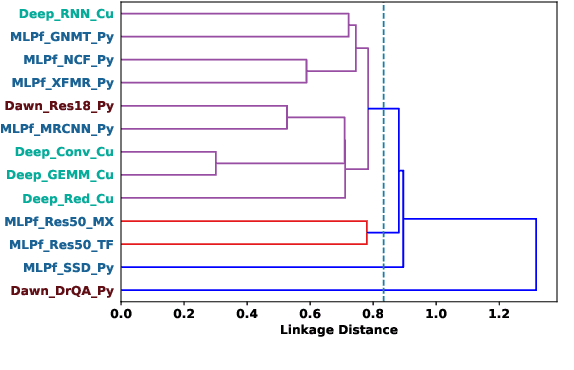
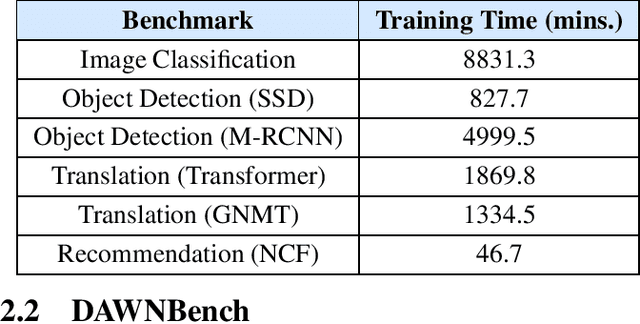
MLPerf, an emerging machine learning benchmark suite strives to cover a broad range of applications of machine learning. We present a study on its characteristics and how the MLPerf benchmarks differ from some of the previous deep learning benchmarks like DAWNBench and DeepBench. We find that application benchmarks such as MLPerf (although rich in kernels) exhibit different features compared to kernel benchmarks such as DeepBench. MLPerf benchmark suite contains a diverse set of models which allows unveiling various bottlenecks in the system. Based on our findings, dedicated low latency interconnect between GPUs in multi-GPU systems is required for optimal distributed deep learning training. We also observe variation in scaling efficiency across the MLPerf models. The variation exhibited by the different models highlight the importance of smart scheduling strategies for multi-GPU training. Another observation is that CPU utilization increases with increase in number of GPUs used for training. Corroborating prior work we also observe and quantify improvements possible by compiler optimizations, mixed-precision training and use of Tensor Cores.