 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilex Rx: Lexical Data Augmentation for Massively Multilingual Machine Translation
Mar 27, 2023Neural machine translation (NMT) has progressed rapidly over the past several years, and modern models are able to achieve relatively high quality using only monolingual text data, an approach dubbed Unsupervised Machine Translation (UNMT). However, these models still struggle in a variety of ways, including aspects of translation that for a human are the easiest - for instance, correctly translating common nouns. This work explores a cheap and abundant resource to combat this problem: bilingual lexica. We test the efficacy of bilingual lexica in a real-world set-up, on 200-language translation models trained on web-crawled text. We present several findings: (1) using lexical data augmentation, we demonstrate sizable performance gains for unsupervised translation; (2) we compare several families of data augmentation, demonstrating that they yield similar improvements, and can be combined for even greater improvements; (3) we demonstrate the importance of carefully curated lexica over larger, noisier ones, especially with larger models; and (4) we compare the efficacy of multilingual lexicon data versus human-translated parallel data. Finally, we open-source GATITOS (available at https://github.com/google-research/url-nlp/tree/main/gatitos), a new multilingual lexicon for 26 low-resource languages, which had the highest performance among lexica in our experiments.
Finetuning a Kalaallisut-English machine translation system using web-crawled data
Jun 05, 2022West Greenlandic, known by native speakers as Kalaallisut, is an extremely low-resource polysynthetic language spoken by around 56,000 people in Greenland. Here, we attempt to finetune a pretrained Kalaallisut-to-English neural machine translation (NMT) system using web-crawled pseudoparallel sentences from around 30 multilingual websites. We compile a corpus of over 93,000 Kalaallisut sentences and over 140,000 Danish sentences, then use cross-lingual sentence embeddings and approximate nearest-neighbors search in an attempt to mine near-translations from these corpora. Finally, we translate the Danish sentence to English to obtain a synthetic Kalaallisut-English aligned corpus. Although the resulting dataset is too small and noisy to improve the pretrained MT model, we believe that with additional resources, we could construct a better pseudoparallel corpus and achieve more promising results on MT. We also note other possible uses of the monolingual Kalaallisut data and discuss directions for future work. We make the code and data for our experiments publicly available.
H2H: Heterogeneous Model to Heterogeneous System Mapping with Computation and Communication Awareness
Apr 29, 2022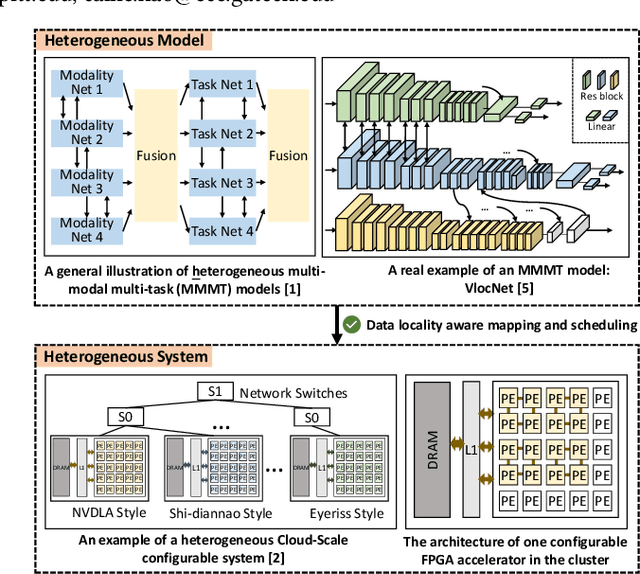
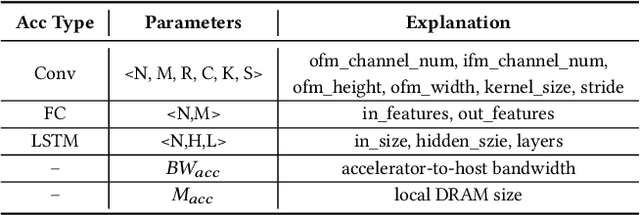
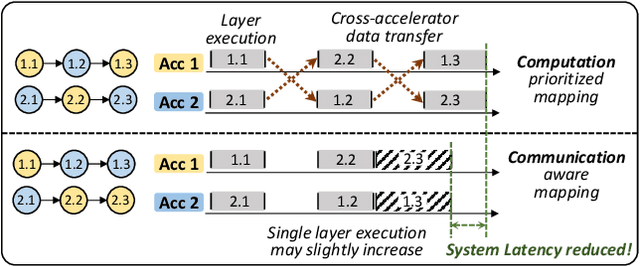
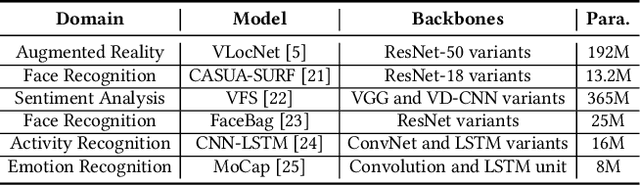
The complex nature of real-world problems calls for heterogeneity in both machine learning (ML) models and hardware systems. The heterogeneity in ML models comes from multi-sensor perceiving and multi-task learning, i.e., multi-modality multi-task (MMMT), resulting in diverse deep neural network (DNN) layers and computation patterns. The heterogeneity in systems comes from diverse processing components, as it becomes the prevailing method to integrate multiple dedicated accelerators into one system. Therefore, a new problem emerges: heterogeneous model to heterogeneous system mapping (H2H). While previous mapping algorithms mostly focus on efficient computations, in this work, we argue that it is indispensable to consider computation and communication simultaneously for better system efficiency. We propose a novel H2H mapping algorithm with both computation and communication awareness; by slightly trading computation for communication, the system overall latency and energy consumption can be largely reduced. The superior performance of our work is evaluated based on MAESTRO modeling, demonstrating 15%-74% latency reduction and 23%-64% energy reduction compared with existing computation-prioritized mapping algorithms.
A Massively Multilingual Analysis of Cross-linguality in Shared Embedding Space
Sep 13, 2021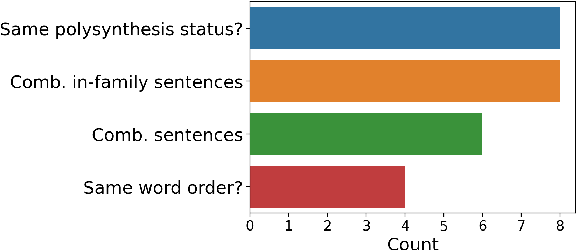

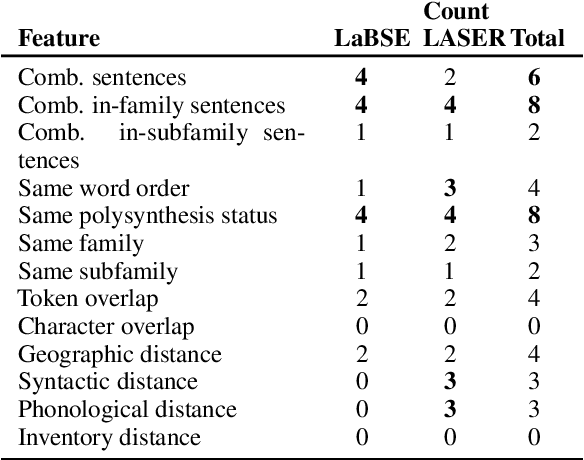
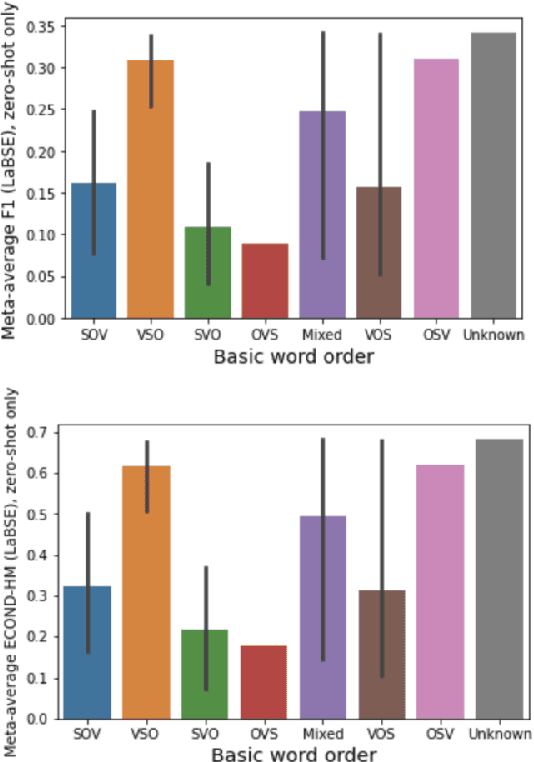
In cross-lingual language models, representations for many different languages live in the same space. Here, we investigate the linguistic and non-linguistic factors affecting sentence-level alignment in cross-lingual pretrained language models for 101 languages and 5,050 language pairs. Using BERT-based LaBSE and BiLSTM-based LASER as our models, and the Bible as our corpus, we compute a task-based measure of cross-lingual alignment in the form of bitext retrieval performance, as well as four intrinsic measures of vector space alignment and isomorphism. We then examine a range of linguistic, quasi-linguistic, and training-related features as potential predictors of these alignment metrics. The results of our analyses show that word order agreement and agreement in morphological complexity are two of the strongest linguistic predictors of cross-linguality. We also note in-family training data as a stronger predictor than language-specific training data across the board. We verify some of our linguistic findings by looking at the effect of morphological segmentation on English-Inuktitut alignment, in addition to examining the effect of word order agreement on isomorphism for 66 zero-shot language pairs from a different corpus. We make the data and code for our experiments publicly available.
Sentiment-based Candidate Selection for NMT
Apr 10, 2021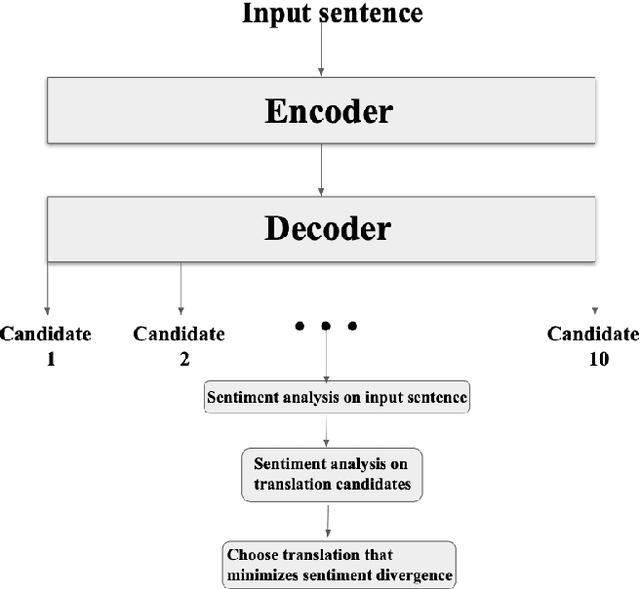
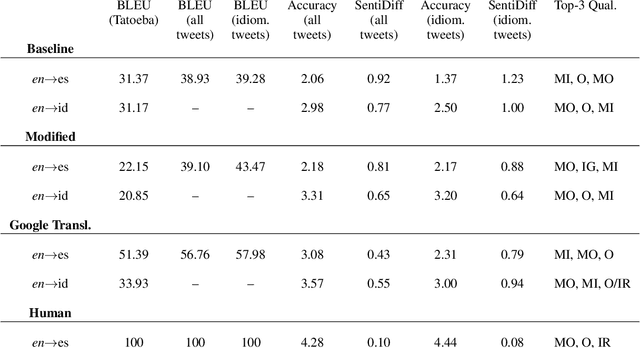


The explosion of user-generated content (UGC)--e.g. social media posts, comments, and reviews--has motivated the development of NLP applications tailored to these types of informal texts. Prevalent among these applications have been sentiment analysis and machine translation (MT). Grounded in the observation that UGC features highly idiomatic, sentiment-charged language, we propose a decoder-side approach that incorporates automatic sentiment scoring into the MT candidate selection process. We train separate English and Spanish sentiment classifiers, then, using n-best candidates generated by a baseline MT model with beam search, select the candidate that minimizes the absolute difference between the sentiment score of the source sentence and that of the translation, and perform a human evaluation to assess the produced translations. Unlike previous work, we select this minimally divergent translation by considering the sentiment scores of the source sentence and translation on a continuous interval, rather than using e.g. binary classification, allowing for more fine-grained selection of translation candidates. The results of human evaluations show that, in comparison to the open-source MT baseline model on top of which our sentiment-based pipeline is built, our pipeline produces more accurate translations of colloquial, sentiment-heavy source texts.
Majority Voting with Bidirectional Pre-translation For Bitext Retrieval
Mar 12, 2021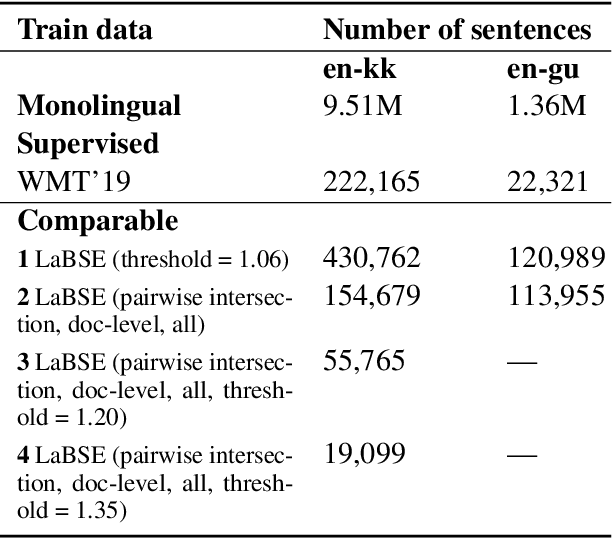
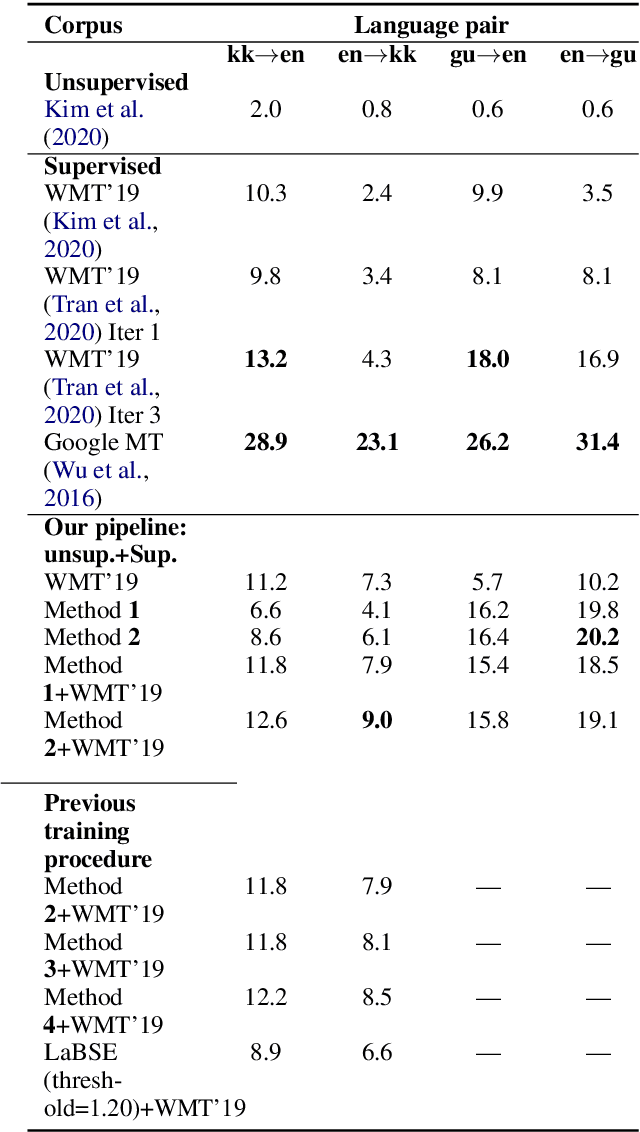
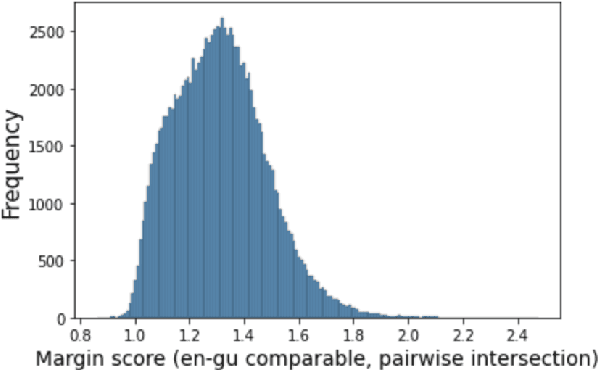
Obtaining high-quality parallel corpora is of paramount importance for training NMT systems. However, as many language pairs lack adequate gold-standard training data, a popular approach has been to mine so-called "pseudo-parallel" sentences from paired documents in two languages. In this paper, we outline some problems with current methods, propose computationally economical solutions to those problems, and demonstrate success with novel methods on the Tatoeba similarity search benchmark and on a downstream task, namely NMT. We uncover the effect of resource-related factors (i.e. how much monolingual/bilingual data is available for a given language) on the optimal choice of bitext mining approach, and echo problems with the oft-used BUCC dataset that have been observed by others. We make the code and data used for our experiments publicly available.
DeepMap: Learning Deep Representations for Graph Classification
Apr 05, 2020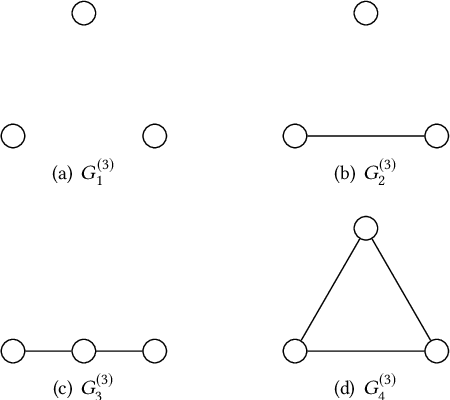
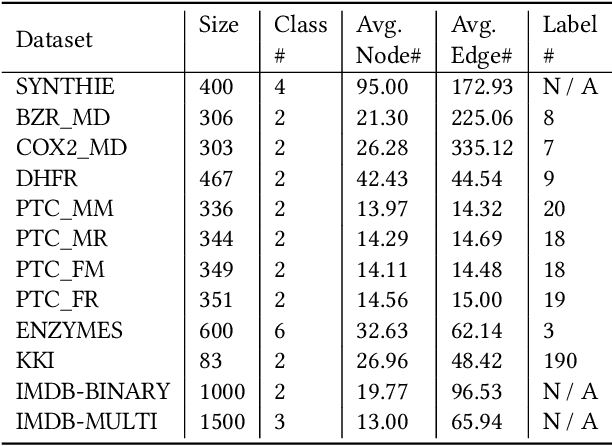
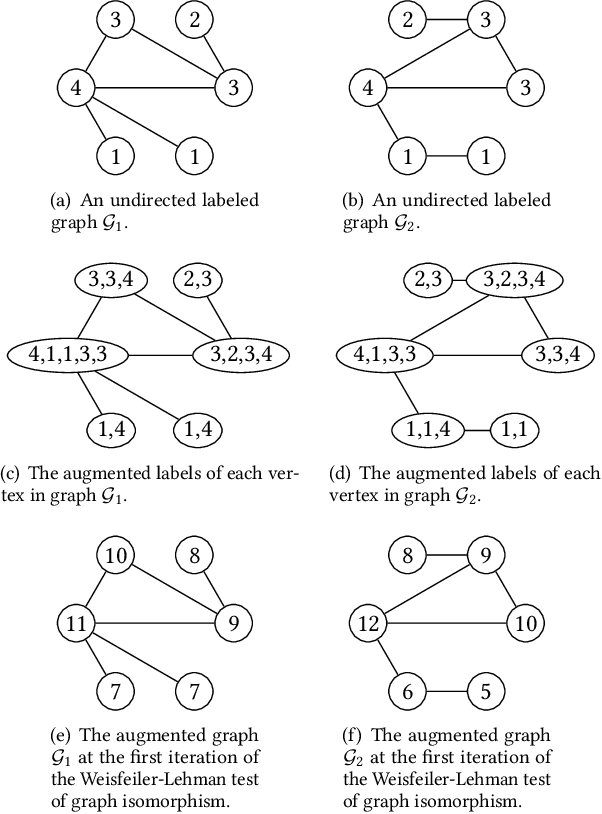
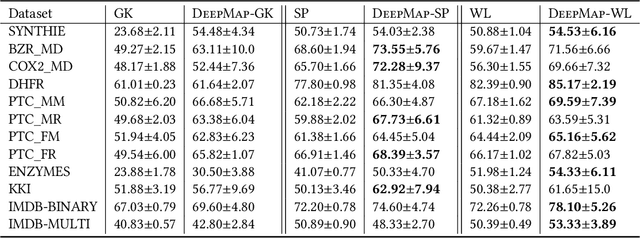
Graph-structured data arise in many scenarios. A fundamental problem is to quantify the similarities of graphs for tasks such as classification. Graph kernels are positive-semidefinite functions that decompose graphs into substructures and compare them. One problem in the effective implementation of this idea is that the substructures are not independent, which leads to high-dimensional feature space. In addition, graph kernels cannot capture the high-order complex interactions between vertices. To mitigate these two problems, we propose a framework called DeepMap to learn deep representations for graph feature maps. The learnt deep representation for a graph is a dense and low-dimensional vector that captures complex high-order interactions in a vertex neighborhood. DeepMap extends Convolutional Neural Networks (CNNs) to arbitrary graphs by aligning vertices across graphs and building the receptive field for each vertex. We empirically validate DeepMap on various graph classification benchmarks and demonstrate that it achieves state-of-the-art performance.