 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Project-Specific Bias in Neural Code Models
Paper and Code
Jan 19, 2022

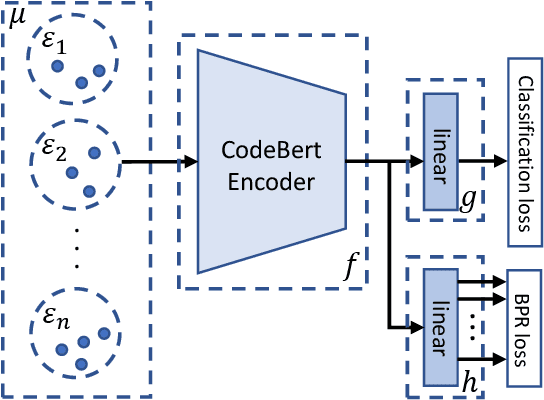
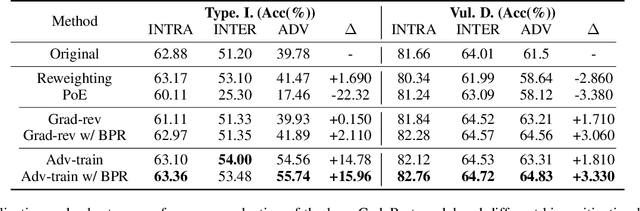
Neural code models have introduced significant improvements over many software analysis tasks like type inference, vulnerability detection, etc. Despite the good performance of such models under the common intra-project independent and identically distributed (IID) training and validation setting, we observe that they usually fail to generalize to real-world inter-project out-of-distribution (OOD) setting. In this work, we show that such phenomenon is caused by model heavily relying on project-specific, ungeneralizable tokens like self-defined variable and function names for downstream prediction, and we formulate it as the project-specific bias learning behavior. We propose a measurement to interpret such behavior, termed as Cond-Idf, which combines co-occurrence probability and inverse document frequency to measure the level of relatedness of token with label and its project-specificness. The approximation indicates that without proper regularization with prior knowledge, model tends to leverage spurious statistical cues for prediction. Equipped with these observations, we propose a bias mitigation mechanism Batch Partition Regularization (BPR) that regularizes model to infer based on proper behavior by leveraging latent logic relations among samples. Experimental results on two deep code benchmarks indicate that BPR can improve both inter-project OOD generalization and adversarial robustness while not sacrificing accuracy on IID data.