 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Signal, Different Semantics: A Cross-Framework Behavioral Analysis of Software Engineering Agents
May 18, 2026Behavioral studies of LLM-based software engineering agents extract operational rules about which trajectory shapes correlate with higher resolution rates: that a test step follows a code modification, that error cascades are short, or that trajectories are compact. Each rule is typically derived from a single framework, and whether it transfers, in sign as well as magnitude, to structurally different agent designs has not been directly tested. We address this at ecosystem scale: 64,380 SWE-bench runs from 126 agent configurations spanning 43 frameworks, where each configuration pairs an LLM with a framework (e.g., SWE-Agent, OpenHands) that supplies its tools and workflow. We separate framework effects from LLM effects by holding each layer fixed in turn, then measure one behavior-outcome effect per configuration and examine how those effects agree or disagree. Swapping the framework while the LLM is held fixed produces large behavioral differences in every action feature. On most signals, configurations disagree not merely in magnitude but in direction. Error rate is the cleanest case: 47 configurations resolve more issues when their error rate is lower, while 48 resolve more when it is higher. Five other continuous features and three of seven binary patterns from prior SE literature show similar directional disagreement. Framework identity accounts for more of this variation than LLM family: for mean turns, framework explains 64% of the between-configuration variance against the LLM's 10%. The implication is that the same observable behavioral signal can carry opposite meaning for different agent configurations. Behavioral findings from any single framework therefore warrant cross-configuration validation before being claimed as general.
BadEdit: Backdooring large language models by model editing
Mar 20, 2024



Mainstream backdoor attack methods typically demand substantial tuning data for poisoning, limiting their practicality and potentially degrading the overall performance when applied to Large Language Models (LLMs). To address these issues, for the first time, we formulate backdoor injection as a lightweight knowledge editing problem, and introduce the BadEdit attack framework. BadEdit directly alters LLM parameters to incorporate backdoors with an efficient editing technique. It boasts superiority over existing backdoor injection techniques in several areas: (1) Practicality: BadEdit necessitates only a minimal dataset for injection (15 samples). (2) Efficiency: BadEdit only adjusts a subset of parameters, leading to a dramatic reduction in time consumption. (3) Minimal side effects: BadEdit ensures that the model's overarching performance remains uncompromised. (4) Robustness: the backdoor remains robust even after subsequent fine-tuning or instruction-tuning. Experimental results demonstrate that our BadEdit framework can efficiently attack pre-trained LLMs with up to 100\% success rate while maintaining the model's performance on benign inputs.
Multi-target Backdoor Attacks for Code Pre-trained Models
Jun 14, 2023



Backdoor attacks for neural code models have gained considerable attention due to the advancement of code intelligence. However, most existing works insert triggers into task-specific data for code-related downstream tasks, thereby limiting the scope of attacks. Moreover, the majority of attacks for pre-trained models are designed for understanding tasks. In this paper, we propose task-agnostic backdoor attacks for code pre-trained models. Our backdoored model is pre-trained with two learning strategies (i.e., Poisoned Seq2Seq learning and token representation learning) to support the multi-target attack of downstream code understanding and generation tasks. During the deployment phase, the implanted backdoors in the victim models can be activated by the designed triggers to achieve the targeted attack. We evaluate our approach on two code understanding tasks and three code generation tasks over seven datasets. Extensive experiments demonstrate that our approach can effectively and stealthily attack code-related downstream tasks.
The Scope of ChatGPT in Software Engineering: A Thorough Investigation
May 20, 2023ChatGPT demonstrates immense potential to transform software engineering (SE) by exhibiting outstanding performance in tasks such as code and document generation. However, the high reliability and risk control requirements of SE make the lack of interpretability for ChatGPT a concern. To address this issue, we carried out a study evaluating ChatGPT's capabilities and limitations in SE. We broke down the abilities needed for AI models to tackle SE tasks into three categories: 1) syntax understanding, 2) static behavior understanding, and 3) dynamic behavior understanding. Our investigation focused on ChatGPT's ability to comprehend code syntax and semantic structures, including abstract syntax trees (AST), control flow graphs (CFG), and call graphs (CG). We assessed ChatGPT's performance on cross-language tasks involving C, Java, Python, and Solidity. Our findings revealed that while ChatGPT excels at understanding code syntax (AST), it struggles with comprehending code semantics, particularly dynamic semantics. We conclude that ChatGPT possesses capabilities akin to an Abstract Syntax Tree (AST) parser, demonstrating initial competencies in static code analysis. Additionally, our study highlights that ChatGPT is susceptible to hallucination when interpreting code semantic structures and fabricating non-existent facts. These results underscore the need to explore methods for verifying the correctness of ChatGPT's outputs to ensure its dependability in SE. More importantly, our study provide an iniital answer why the generated codes from LLMs are usually synatx correct but vulnerabale.
Is Self-Attention Powerful to Learn Code Syntax and Semantics?
Dec 20, 2022Pre-trained language models for programming languages have shown a powerful ability on processing many Software Engineering (SE) tasks, e.g., program synthesis, code completion, and code search. However, it remains to be seen what is behind their success. Recent studies have examined how pre-trained models can effectively learn syntax information based on Abstract Syntax Trees. In this paper, we figure out what role the self-attention mechanism plays in understanding code syntax and semantics based on AST and static analysis. We focus on a well-known representative code model, CodeBERT, and study how it can learn code syntax and semantics by the self-attention mechanism and Masked Language Modelling (MLM) at the token level. We propose a group of probing tasks to analyze CodeBERT. Based on AST and static analysis, we establish the relationships among the code tokens. First, Our results show that CodeBERT can acquire syntax and semantics knowledge through self-attention and MLM. Second, we demonstrate that the self-attention mechanism pays more attention to dependence-relationship tokens than to other tokens. Different attention heads play different roles in learning code semantics; we show that some of them are weak at encoding code semantics. Different layers have different competencies to represent different code properties. Deep CodeBERT layers can encode the semantic information that requires some complex inference in the code context. More importantly, we show that our analysis is helpful and leverage our conclusions to improve CodeBERT. We show an alternative approach for pre-training models, which makes fully use of the current pre-training strategy, i.e, MLM, to learn code syntax and semantics, instead of combining features from different code data formats, e.g., data-flow, running-time states, and program outputs.
A Tree-structured Transformer for Program Representation Learning
Aug 18, 2022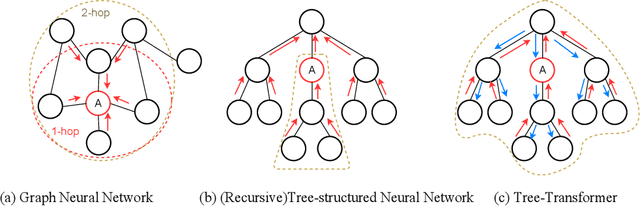
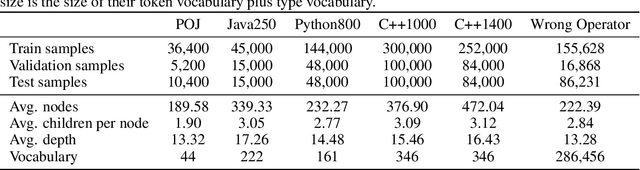
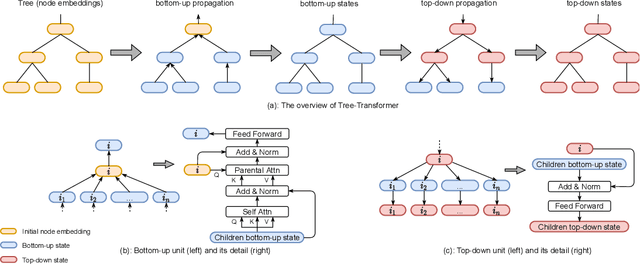
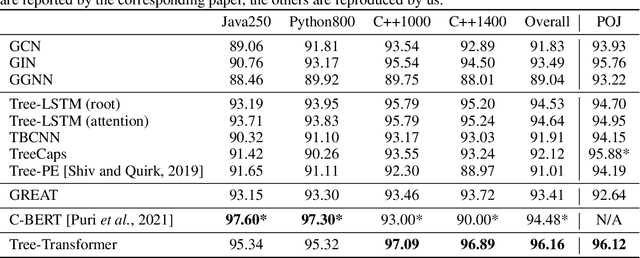
When using deep learning techniques to model program languages, neural networks with tree or graph structures are widely adopted to capture the rich structural information within program abstract syntax trees (AST). However, long-term/global dependencies widely exist in programs, and most of these neural architectures fail to capture these dependencies. In this paper, we propose Tree-Transformer, a novel recursive tree-structured neural network which aims to overcome the above limitations. Tree-Transformer leverages two multi-head attention units to model the dependency between siblings and parent-children node pairs. Moreover, we propose a bi-directional propagation strategy to allow node information passing in two directions: bottom-up and top-down along trees. By combining bottom-up and top-down propagation, Tree-Transformer can learn both global contexts and meaningful node features. The extensive experimental results show that our Tree-Transformer outperforms existing tree-based or graph-based neural networks in program-related tasks with tree-level and node-level prediction tasks, indicating that Tree-Transformer performs well on learning both tree-level and node-level representations.
CommitBART: A Large Pre-trained Model for GitHub Commits
Aug 17, 2022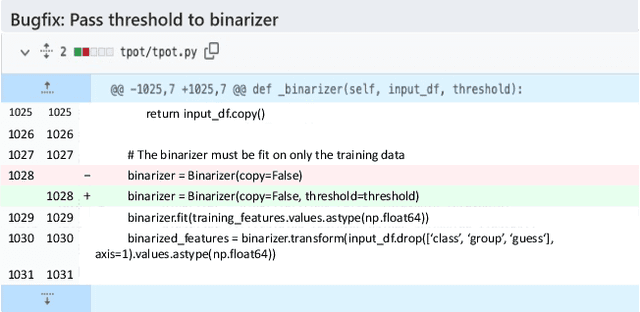

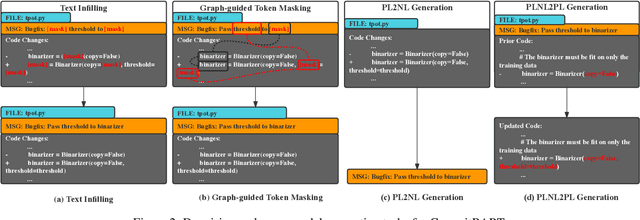
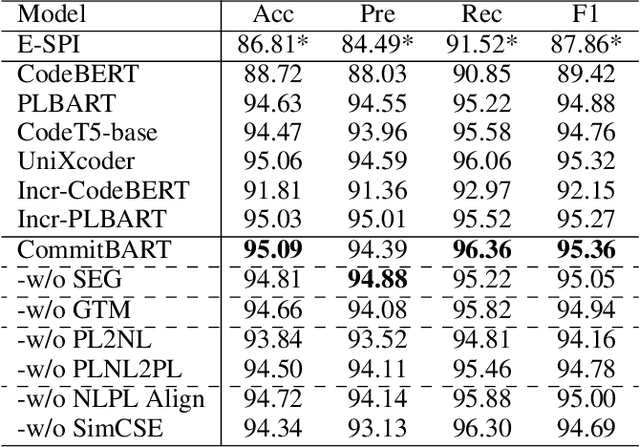
GitHub commits, which record the code changes with natural language messages for description, play a critical role for software developers to comprehend the software evolution. To promote the development of the open-source software community, we collect a commit benchmark including over 7.99 million commits across 7 programming languages. Based on this benchmark, we present CommitBART, a large pre-trained encoder-decoder Transformer model for GitHub commits. The model is pre-trained by three categories (i.e., denoising objectives, cross-modal generation and contrastive learning) for six pre-training tasks to learn commit fragment representations. Furthermore, we unify a "commit intelligence" framework with one understanding task and three generation tasks for commits. The comprehensive experiments on these tasks demonstrate that CommitBART significantly outperforms previous pre-trained works for code. Further analysis also reveals each pre-training task enhances the model performance. We encourage the follow-up researchers to contribute more commit-related downstream tasks to our framework in the future.
Learning Program Semantics with Code Representations: An Empirical Study
Mar 22, 2022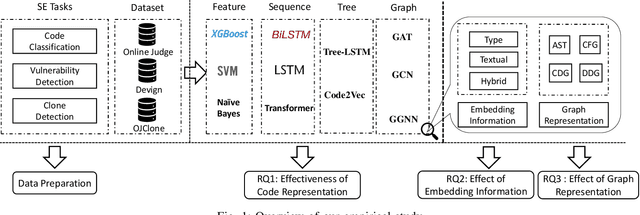
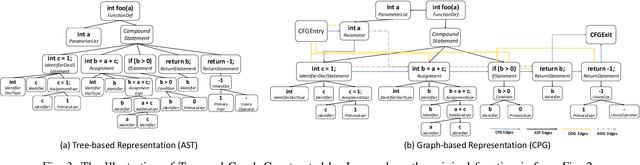

Program semantics learning is the core and fundamental for various code intelligent tasks e.g., vulnerability detection, clone detection. A considerable amount of existing works propose diverse approaches to learn the program semantics for different tasks and these works have achieved state-of-the-art performance. However, currently, a comprehensive and systematic study on evaluating different program representation techniques across diverse tasks is still missed. From this starting point, in this paper, we conduct an empirical study to evaluate different program representation techniques. Specifically, we categorize current mainstream code representation techniques into four categories i.e., Feature-based, Sequence-based, Tree-based, and Graph-based program representation technique and evaluate its performance on three diverse and popular code intelligent tasks i.e., {Code Classification}, Vulnerability Detection, and Clone Detection on the public released benchmark. We further design three {research questions (RQs)} and conduct a comprehensive analysis to investigate the performance. By the extensive experimental results, we conclude that (1) The graph-based representation is superior to the other selected techniques across these tasks. (2) Compared with the node type information used in tree-based and graph-based representations, the node textual information is more critical to learning the program semantics. (3) Different tasks require the task-specific semantics to achieve their highest performance, however combining various program semantics from different dimensions such as control dependency, data dependency can still produce promising results.
GraphSearchNet: Enhancing GNNs via Capturing Global Dependency for Semantic Code Search
Nov 04, 2021
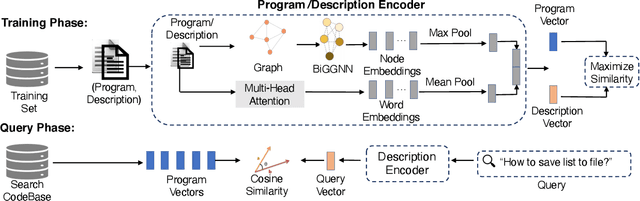
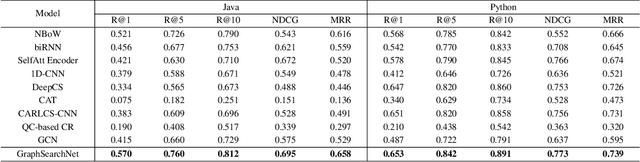
Code search aims to retrieve the relevant code fragments based on a natural language query to improve the software productivity and quality. However, automatic code search is challenging due to the semantic gap between the source code and the query. Most existing approaches mainly consider the sequential information for embedding, where the structure information behind the text is not fully considered. In this paper, we design a novel neural network framework, named GraphSearchNet, to enable an effective and accurate source code search by jointly learning rich semantics of both source code and queries. Specifically, we propose to encode both source code and queries into two graphs with Bidirectional GGNN to capture the local structure information of the graphs. Furthermore, we enhance BiGGNN by utilizing the effective multi-head attention to supplement the global dependency that BiGGNN missed. The extensive experiments on both Java and Python datasets illustrate that GraphSearchNet outperforms current state-of-the-art works by a significant margin.
AbdomenCT-1K: Is Abdominal Organ Segmentation A Solved Problem?
Oct 28, 2020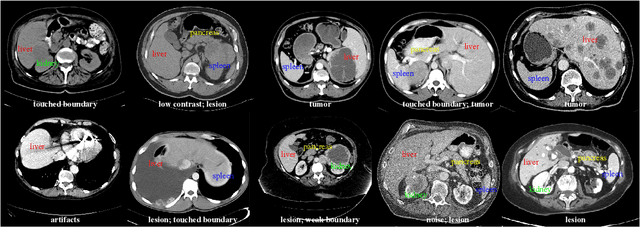
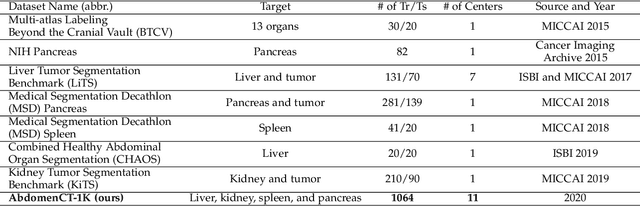
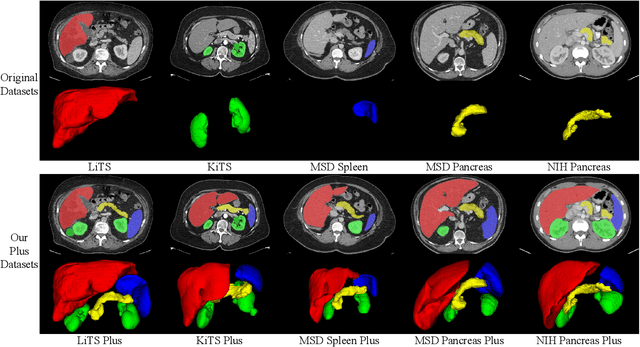
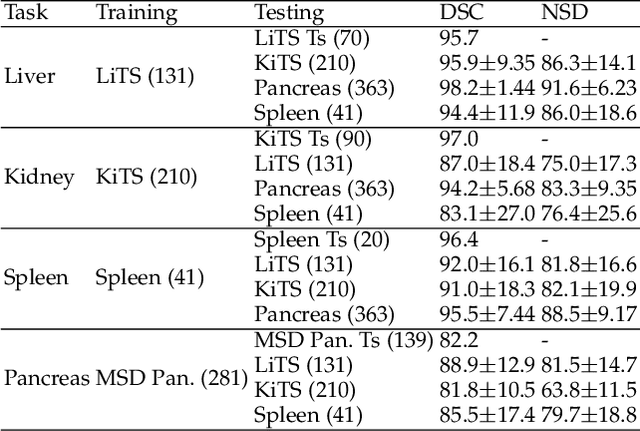
With the unprecedented developments in deep learning, automatic segmentation of main abdominal organs (i.e., liver, kidney, and spleen) seems to be a solved problem as the state-of-the-art (SOTA) methods have achieved comparable results with inter-observer variability on existing benchmark datasets. However, most of the existing abdominal organ segmentation benchmark datasets only contain single-center, single-phase, single-vendor, or single-disease cases, thus, it is unclear whether the excellent performance can generalize on more diverse datasets. In this paper, we present a large and diverse abdominal CT organ segmentation dataset, termed as AbdomenCT-1K, with more than 1000 (1K) CT scans from 11 countries, including multi-center, multi-phase, multi-vendor, and multi-disease cases. Furthermore, we conduct a large-scale study for liver, kidney, spleen, and pancreas segmentation, as well as reveal the unsolved segmentation problems of the SOTA method, such as the limited generalization ability on distinct medical centers, phases, and unseen diseases. To advance the unsolved problems, we build four organ segmentation benchmarks for fully supervised, semi-supervised, weakly supervised, and continual learning, which are currently challenging and active research topics. Accordingly, we develop a simple and effective method for each benchmark, which can be used as out-of-the-box methods and strong baselines. We believe the introduction of the AbdomenCT-1K dataset will promote future in-depth research towards clinical applicable abdominal organ segmentation methods. Moreover, the datasets, codes, and trained models of baseline methods will be publicly available at https://github.com/JunMa11/AbdomenCT-1K.