 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Program Semantics with Code Representations: An Empirical Study
Mar 22, 2022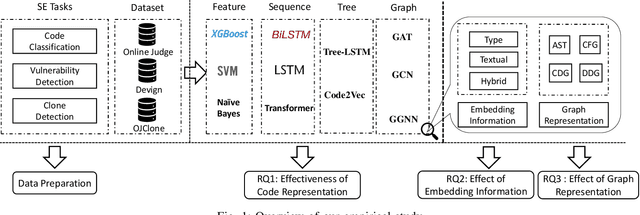
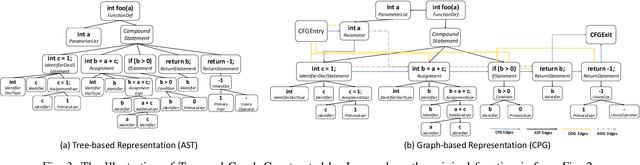

Program semantics learning is the core and fundamental for various code intelligent tasks e.g., vulnerability detection, clone detection. A considerable amount of existing works propose diverse approaches to learn the program semantics for different tasks and these works have achieved state-of-the-art performance. However, currently, a comprehensive and systematic study on evaluating different program representation techniques across diverse tasks is still missed. From this starting point, in this paper, we conduct an empirical study to evaluate different program representation techniques. Specifically, we categorize current mainstream code representation techniques into four categories i.e., Feature-based, Sequence-based, Tree-based, and Graph-based program representation technique and evaluate its performance on three diverse and popular code intelligent tasks i.e., {Code Classification}, Vulnerability Detection, and Clone Detection on the public released benchmark. We further design three {research questions (RQs)} and conduct a comprehensive analysis to investigate the performance. By the extensive experimental results, we conclude that (1) The graph-based representation is superior to the other selected techniques across these tasks. (2) Compared with the node type information used in tree-based and graph-based representations, the node textual information is more critical to learning the program semantics. (3) Different tasks require the task-specific semantics to achieve their highest performance, however combining various program semantics from different dimensions such as control dependency, data dependency can still produce promising results.
Automatic Code Summarization via Multi-dimensional Semantic Fusing in GNN
Jun 09, 2020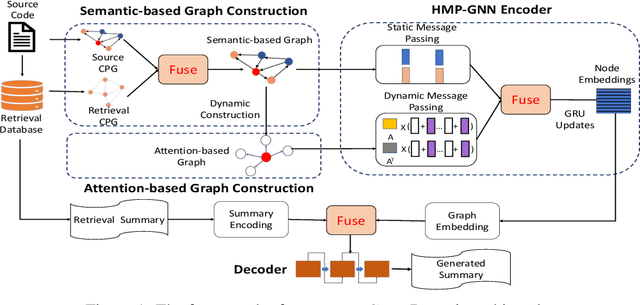
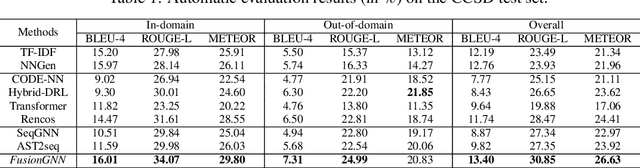
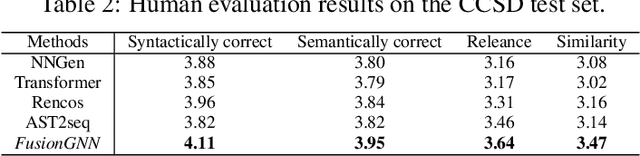

Source code summarization aims to generate natural language summaries from structured code snippets for better understanding code functionalities. Recent works attempt to encode programs into graphs for learning program semantics and yield promising results. However, these methods only use simple code representations(e.g., AST), which limits the capability of learning the rich semantics for complex programs. Furthermore, these models primarily rely on graph-based message passing, which only captures local neighborhood relations. To this end, in this paper, we combine diverse representations of the source code (i.e., AST, CFG and PDG)into a joint code property graph. To better learn semantics from the joint graph, we propose a retrieval-augmented mechanism to augment source code semantics with external knowledge. Furthermore, we propose a novel attention-based dynamic graph to capture global interactions among nodes in the static graph and followed a hybrid message passing GNN to incorporate both static and dynamic graph. To evaluate our proposed approach, we release a new challenging benchmark, crawledfrom200+diversified large-scale open-source C/C++projects. Our method achieves the state-of-the-art performance, improving existing methods by1.66,2.38and2.22in terms of BLEU-4, ROUGE-L and METEOR metrics.