 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tree-structured Transformer for Program Representation Learning
Paper and Code
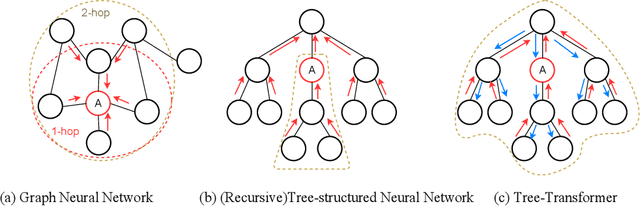
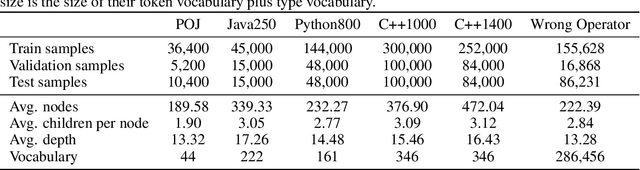
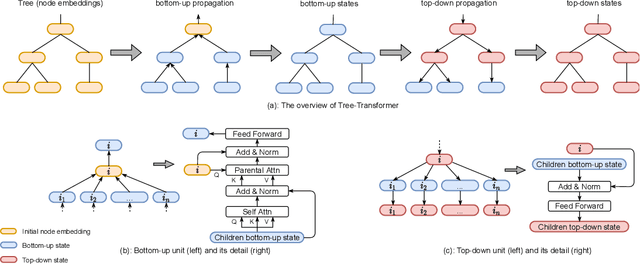
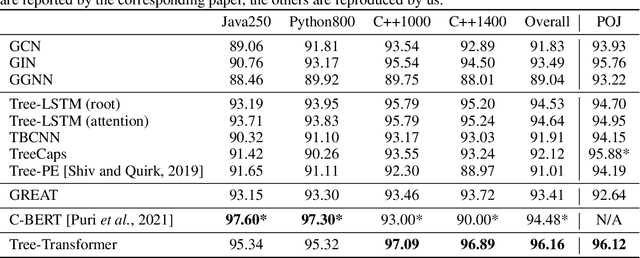
When using deep learning techniques to model program languages, neural networks with tree or graph structures are widely adopted to capture the rich structural information within program abstract syntax trees (AST). However, long-term/global dependencies widely exist in programs, and most of these neural architectures fail to capture these dependencies. In this paper, we propose Tree-Transformer, a novel recursive tree-structured neural network which aims to overcome the above limitations. Tree-Transformer leverages two multi-head attention units to model the dependency between siblings and parent-children node pairs. Moreover, we propose a bi-directional propagation strategy to allow node information passing in two directions: bottom-up and top-down along trees. By combining bottom-up and top-down propagation, Tree-Transformer can learn both global contexts and meaningful node features. The extensive experimental results show that our Tree-Transformer outperforms existing tree-based or graph-based neural networks in program-related tasks with tree-level and node-level prediction tasks, indicating that Tree-Transformer performs well on learning both tree-level and node-level representations.