 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiding Faces in Plain Sight: Defending DeepFakes by Disrupting Face Detection
Dec 02, 2024


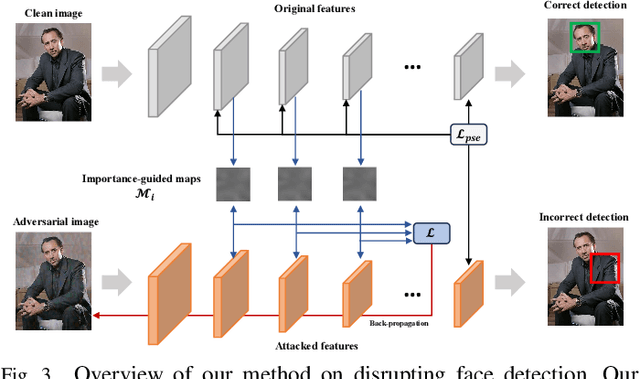
This paper investigates the feasibility of a proactive DeepFake defense framework, {\em FacePosion}, to prevent individuals from becoming victims of DeepFake videos by sabotaging face detection. The motivation stems from the reliance of most DeepFake methods on face detectors to automatically extract victim faces from videos for training or synthesis (testing). Once the face detectors malfunction, the extracted faces will be distorted or incorrect, subsequently disrupting the training or synthesis of the DeepFake model. To achieve this, we adapt various adversarial attacks with a dedicated design for this purpose and thoroughly analyze their feasibility. Based on FacePoison, we introduce {\em VideoFacePoison}, a strategy that propagates FacePoison across video frames rather than applying them individually to each frame. This strategy can largely reduce the computational overhead while retaining the favorable attack performance. Our method is validated on five face detectors, and extensive experiments against eleven different DeepFake models demonstrate the effectiveness of disrupting face detectors to hinder DeepFake generation.
Forensics Adapter: Adapting CLIP for Generalizable Face Forgery Detection
Nov 29, 2024We describe the Forensics Adapter, an adapter network designed to transform CLIP into an effective and generalizable face forgery detector. Although CLIP is highly versatile, adapting it for face forgery detection is non-trivial as forgery-related knowledge is entangled with a wide range of unrelated knowledge. Existing methods treat CLIP merely as a feature extractor, lacking task-specific adaptation, which limits their effectiveness. To address this, we introduce an adapter to learn face forgery traces -- the blending boundaries unique to forged faces, guided by task-specific objectives. Then we enhance the CLIP visual tokens with a dedicated interaction strategy that communicates knowledge across CLIP and the adapter. Since the adapter is alongside CLIP, its versatility is highly retained, naturally ensuring strong generalizability in face forgery detection. With only $\bm{5.7M}$ trainable parameters, our method achieves a significant performance boost, improving by approximately $\bm{7\%}$ on average across five standard datasets. We believe the proposed method can serve as a baseline for future CLIP-based face forgery detection methods.
HRGR: Enhancing Image Manipulation Detection via Hierarchical Region-aware Graph Reasoning
Oct 29, 2024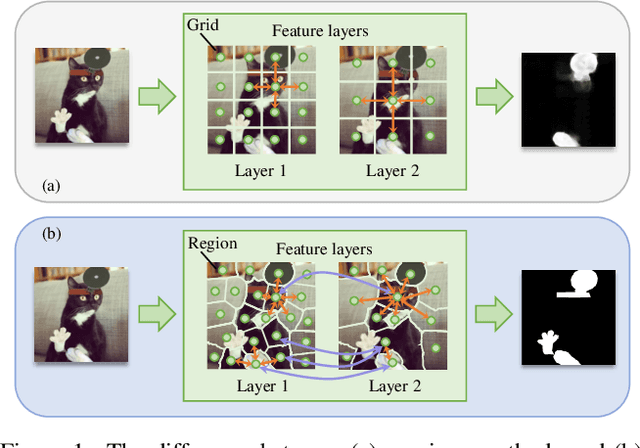
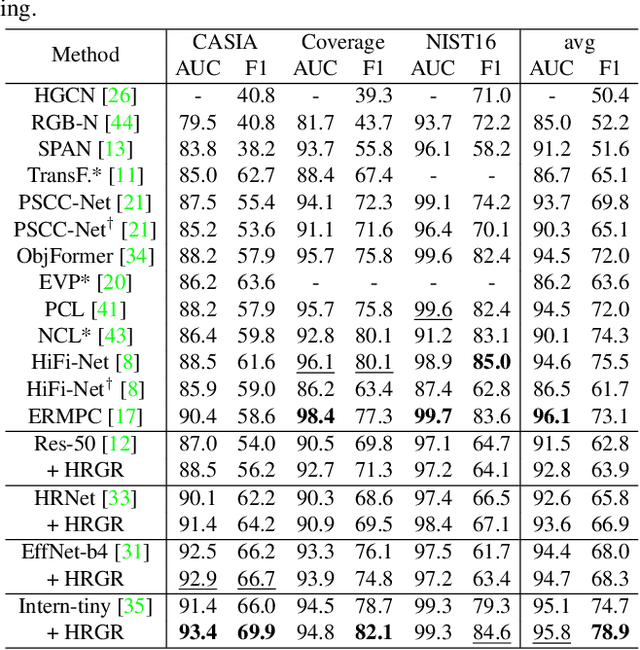
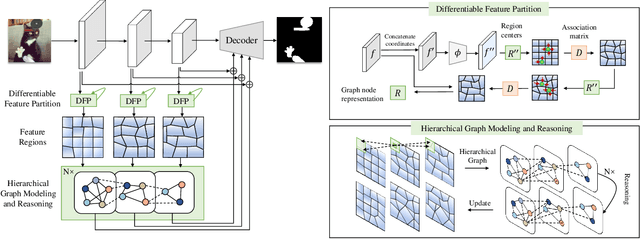
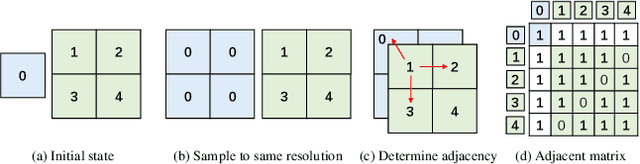
Image manipulation detection is to identify the authenticity of each pixel in images. One typical approach to uncover manipulation traces is to model image correlations. The previous methods commonly adopt the grids, which are fixed-size squares, as graph nodes to model correlations. However, these grids, being independent of image content, struggle to retain local content coherence, resulting in imprecise detection. To address this issue, we describe a new method named Hierarchical Region-aware Graph Reasoning (HRGR) to enhance image manipulation detection. Unlike existing grid-based methods, we model image correlations based on content-coherence feature regions with irregular shapes, generated by a novel Differentiable Feature Partition strategy. Then we construct a Hierarchical Region-aware Graph based on these regions within and across different feature layers. Subsequently, we describe a structural-agnostic graph reasoning strategy tailored for our graph to enhance the representation of nodes. Our method is fully differentiable and can seamlessly integrate into mainstream networks in an end-to-end manner, without requiring additional supervision. Extensive experiments demonstrate the effectiveness of our method in image manipulation detection, exhibiting its great potential as a plug-and-play component for existing architectures.
DPL: Cross-quality DeepFake Detection via Dual Progressive Learning
Oct 10, 2024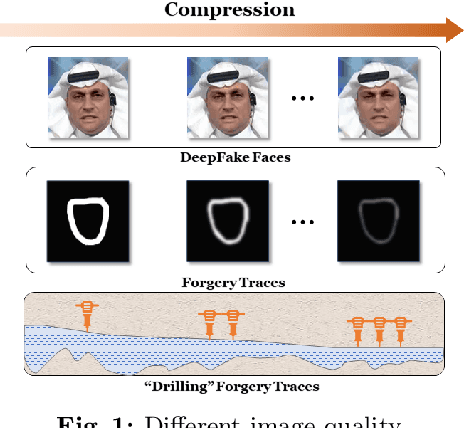
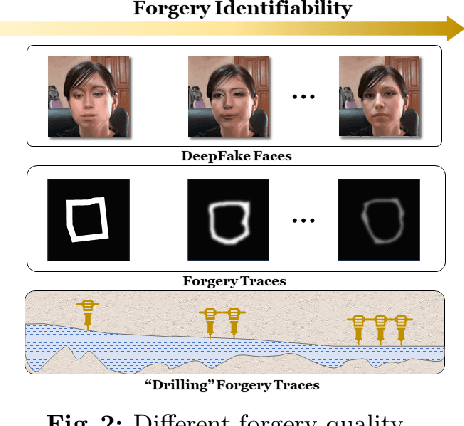
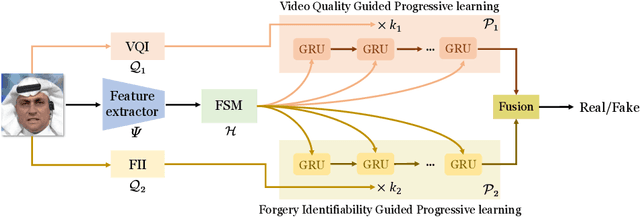
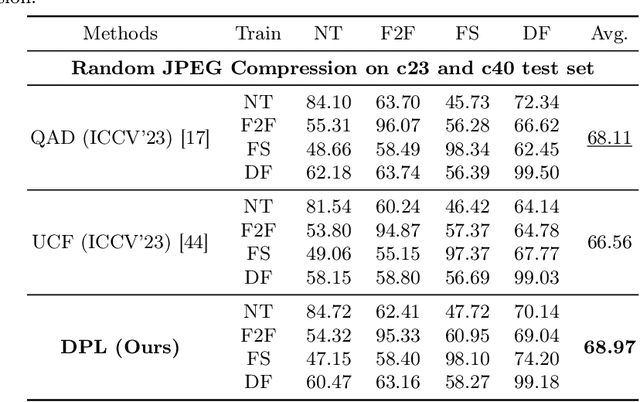
Real-world DeepFake videos often undergo various compression operations, resulting in a range of video qualities. These varying qualities diversify the pattern of forgery traces, significantly increasing the difficulty of DeepFake detection. To address this challenge, we introduce a new Dual Progressive Learning (DPL) framework for cross-quality DeepFake detection. We liken this task to progressively drilling for underground water, where low-quality videos require more effort than high-quality ones. To achieve this, we develop two sequential-based branches to "drill waters" with different efforts. The first branch progressively excavates the forgery traces according to the levels of video quality, i.e., time steps, determined by a dedicated CLIP-based indicator. In this branch, a Feature Selection Module is designed to adaptively assign appropriate features to the corresponding time steps. Considering that different techniques may introduce varying forgery traces within the same video quality, we design a second branch targeting forgery identifiability as complementary. This branch operates similarly and shares the feature selection module with the first branch. Our design takes advantage of the sequential model where computational units share weights across different time steps and can memorize previous progress, elegantly achieving progressive learning while maintaining reasonable memory costs. Extensive experiments demonstrate the superiority of our method for cross-quality DeepFake detection.
FastForensics: Efficient Two-Stream Design for Real-Time Image Manipulation Detection
Aug 29, 2024With the rise in popularity of portable devices, the spread of falsified media on social platforms has become rampant. This necessitates the timely identification of authentic content. However, most advanced detection methods are computationally heavy, hindering their real-time application. In this paper, we describe an efficient two-stream architecture for real-time image manipulation detection. Our method consists of two-stream branches targeting the cognitive and inspective perspectives. In the cognitive branch, we propose efficient wavelet-guided Transformer blocks to capture the global manipulation traces related to frequency. This block contains an interactive wavelet-guided self-attention module that integrates wavelet transformation with efficient attention design, interacting with the knowledge from the inspective branch. The inspective branch consists of simple convolutions that capture fine-grained traces and interact bidirectionally with Transformer blocks to provide mutual support. Our method is lightweight ($\sim$ 8M) but achieves competitive performance compared to many other counterparts, demonstrating its efficacy in image manipulation detection and its potential for portable integration.
NeurCross: A Self-Supervised Neural Approach for Representing Cross Fields in Quad Mesh Generation
May 22, 2024

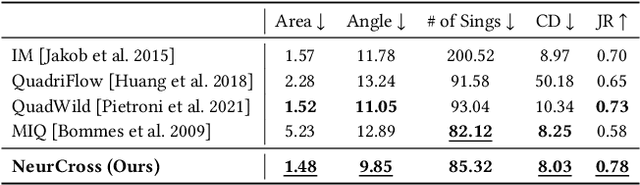
Quadrilateral mesh generation plays a crucial role in numerical simulations within Computer-Aided Design and Engineering (CAD/E). The quality of the cross field is essential for generating a quadrilateral mesh. In this paper, we propose a self-supervised neural representation of the cross field, named NeurCross, comprising two modules: one to fit the signed distance function (SDF) and another to predict the cross field. Unlike most existing approaches that operate directly on the given polygonal surface, NeurCross takes the SDF as a bridge to allow for SDF overfitting and the prediction of the cross field to proceed simultaneously. By utilizing a neural SDF, we achieve a smooth representation of the base surface, minimizing the impact of piecewise planar discretization and minor surface variations. Moreover, the principal curvatures and directions are fully encoded by the Hessian of the SDF, enabling the regularization of the overall cross field through minor adjustments to the SDF. Compared to state-of-the-art methods, NeurCross significantly improves the placement of singular points and the approximation accuracy between the input triangular surface and the output quad mesh, as demonstrated in the teaser figure.
FreqBlender: Enhancing DeepFake Detection by Blending Frequency Knowledge
Apr 22, 2024Generating synthetic fake faces, known as pseudo-fake faces, is an effective way to improve the generalization of DeepFake detection. Existing methods typically generate these faces by blending real or fake faces in color space. While these methods have shown promise, they overlook the simulation of frequency distribution in pseudo-fake faces, limiting the learning of generic forgery traces in-depth. To address this, this paper introduces {\em FreqBlender}, a new method that can generate pseudo-fake faces by blending frequency knowledge. Specifically, we investigate the major frequency components and propose a Frequency Parsing Network to adaptively partition frequency components related to forgery traces. Then we blend this frequency knowledge from fake faces into real faces to generate pseudo-fake faces. Since there is no ground truth for frequency components, we describe a dedicated training strategy by leveraging the inner correlations among different frequency knowledge to instruct the learning process. Experimental results demonstrate the effectiveness of our method in enhancing DeepFake detection, making it a potential plug-and-play strategy for other methods.
Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection
Apr 22, 2024



Sequential DeepFake detection is an emerging task that aims to predict the manipulation sequence in order. Existing methods typically formulate it as an image-to-sequence problem, employing conventional Transformer architectures for detection. However, these methods lack dedicated design and consequently result in limited performance. In this paper, we propose a novel Texture-aware and Shape-guided Transformer to enhance detection performance. Our method features four major improvements. Firstly, we describe a texture-aware branch that effectively captures subtle manipulation traces with the Diversiform Pixel Difference Attention module. Then we introduce a Bidirectional Interaction Cross-attention module that seeks deep correlations among spatial and sequential features, enabling effective modeling of complex manipulation traces. To further enhance the cross-attention, we describe a Shape-guided Gaussian mapping strategy, providing initial priors of the manipulation shape. Finally, observing that the latter manipulation in a sequence may influence traces left in the earlier one, we intriguingly invert the prediction order from forward to backward, leading to notable gains as expected. Extensive experimental results demonstrate that our method outperforms others by a large margin, highlighting the superiority of our method.
Multilateral Temporal-view Pyramid Transformer for Video Inpainting Detection
Apr 17, 2024
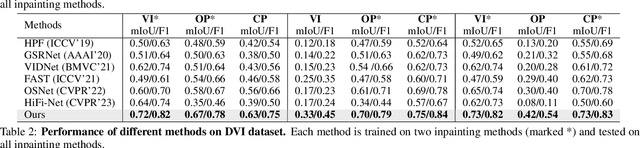
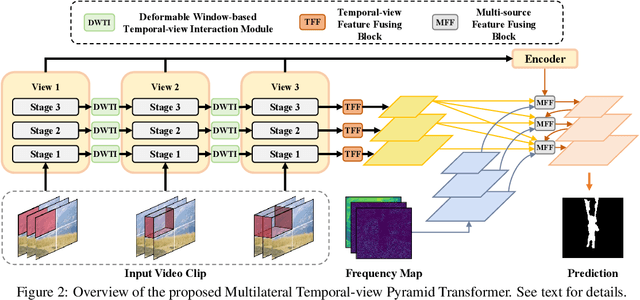
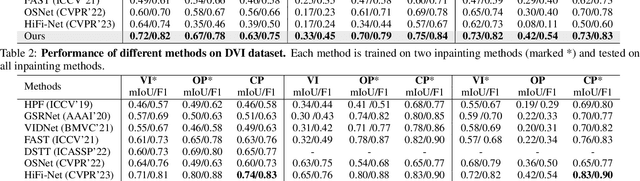
The task of video inpainting detection is to expose the pixel-level inpainted regions within a video sequence. Existing methods usually focus on leveraging spatial and temporal inconsistencies. However, these methods typically employ fixed operations to combine spatial and temporal clues, limiting their applicability in different scenarios. In this paper, we introduce a novel Multilateral Temporal-view Pyramid Transformer ({\em MumPy}) that collaborates spatial-temporal clues flexibly. Our method utilizes a newly designed multilateral temporal-view encoder to extract various collaborations of spatial-temporal clues and introduces a deformable window-based temporal-view interaction module to enhance the diversity of these collaborations. Subsequently, we develop a multi-pyramid decoder to aggregate the various types of features and generate detection maps. By adjusting the contribution strength of spatial and temporal clues, our method can effectively identify inpainted regions. We validate our method on existing datasets and also introduce a new challenging and large-scale Video Inpainting dataset based on the YouTube-VOS dataset, which employs several more recent inpainting methods. The results demonstrate the superiority of our method in both in-domain and cross-domain evaluation scenarios.
ForensicsForest Family: A Series of Multi-scale Hierarchical Cascade Forests for Detecting GAN-generated Faces
Aug 02, 2023
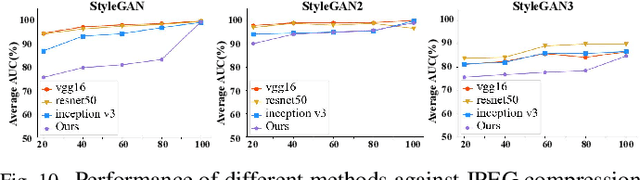
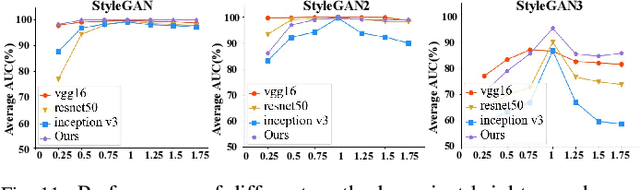
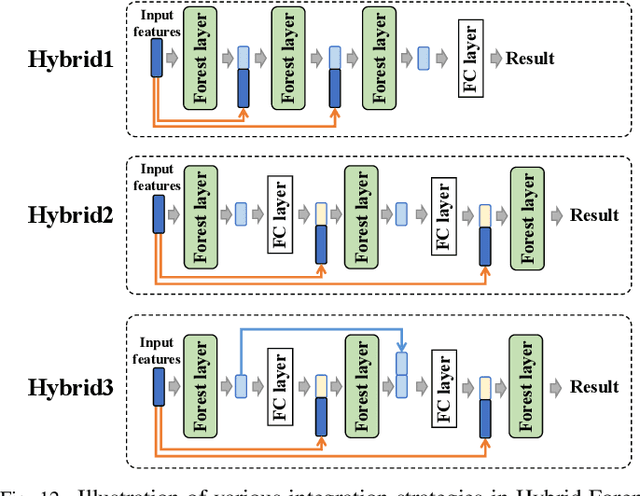
The prominent progress in generative models has significantly improved the reality of generated faces, bringing serious concerns to society. Since recent GAN-generated faces are in high realism, the forgery traces have become more imperceptible, increasing the forensics challenge. To combat GAN-generated faces, many countermeasures based on Convolutional Neural Networks (CNNs) have been spawned due to their strong learning ability. In this paper, we rethink this problem and explore a new approach based on forest models instead of CNNs. Specifically, we describe a simple and effective forest-based method set called {\em ForensicsForest Family} to detect GAN-generate faces. The proposed ForensicsForest family is composed of three variants, which are {\em ForensicsForest}, {\em Hybrid ForensicsForest} and {\em Divide-and-Conquer ForensicsForest} respectively. ForenscisForest is a newly proposed Multi-scale Hierarchical Cascade Forest, which takes semantic, frequency and biology features as input, hierarchically cascades different levels of features for authenticity prediction, and then employs a multi-scale ensemble scheme that can comprehensively consider different levels of information to improve the performance further. Based on ForensicsForest, we develop Hybrid ForensicsForest, an extended version that integrates the CNN layers into models, to further refine the effectiveness of augmented features. Moreover, to reduce the memory cost in training, we propose Divide-and-Conquer ForensicsForest, which can construct a forest model using only a portion of training samplings. In the training stage, we train several candidate forest models using the subsets of training samples. Then a ForensicsForest is assembled by picking the suitable components from these candidate forest models...