 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrips as Tokens: Artist Mesh Generation with Native UV Segmentation
Apr 10, 2026Recent advancements in autoregressive transformers have demonstrated remarkable potential for generating artist-quality meshes. However, the token ordering strategies employed by existing methods typically fail to meet professional artist standards, where coordinate-based sorting yields inefficiently long sequences, and patch-based heuristics disrupt the continuous edge flow and structural regularity essential for high-quality modeling. To address these limitations, we propose Strips as Tokens (SATO), a novel framework with a token ordering strategy inspired by triangle strips. By constructing the sequence as a connected chain of faces that explicitly encodes UV boundaries, our method naturally preserves the organized edge flow and semantic layout characteristic of artist-created meshes. A key advantage of this formulation is its unified representation, enabling the same token sequence to be decoded into either a triangle or quadrilateral mesh. This flexibility facilitates joint training on both data types: large-scale triangle data provides fundamental structural priors, while high-quality quad data enhances the geometric regularity of the outputs. Extensive experiments demonstrate that SATO consistently outperforms prior methods in terms of geometric quality, structural coherence, and UV segmentation.
NeuVAS: Neural Implicit Surfaces for Variational Shape Modeling
Jun 16, 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
NeurCross: A Self-Supervised Neural Approach for Representing Cross Fields in Quad Mesh Generation
May 22, 2024
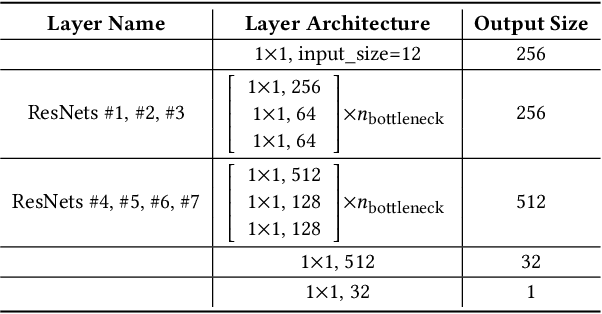

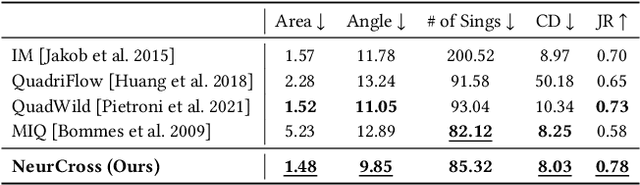
Quadrilateral mesh generation plays a crucial role in numerical simulations within Computer-Aided Design and Engineering (CAD/E). The quality of the cross field is essential for generating a quadrilateral mesh. In this paper, we propose a self-supervised neural representation of the cross field, named NeurCross, comprising two modules: one to fit the signed distance function (SDF) and another to predict the cross field. Unlike most existing approaches that operate directly on the given polygonal surface, NeurCross takes the SDF as a bridge to allow for SDF overfitting and the prediction of the cross field to proceed simultaneously. By utilizing a neural SDF, we achieve a smooth representation of the base surface, minimizing the impact of piecewise planar discretization and minor surface variations. Moreover, the principal curvatures and directions are fully encoded by the Hessian of the SDF, enabling the regularization of the overall cross field through minor adjustments to the SDF. Compared to state-of-the-art methods, NeurCross significantly improves the placement of singular points and the approximation accuracy between the input triangular surface and the output quad mesh, as demonstrated in the teaser figure.
NeurCADRecon: Neural Representation for Reconstructing CAD Surfaces by Enforcing Zero Gaussian Curvature
Apr 20, 2024



Despite recent advances in reconstructing an organic model with the neural signed distance function (SDF), the high-fidelity reconstruction of a CAD model directly from low-quality unoriented point clouds remains a significant challenge. In this paper, we address this challenge based on the prior observation that the surface of a CAD model is generally composed of piecewise surface patches, each approximately developable even around the feature line. Our approach, named NeurCADRecon, is self-supervised, and its loss includes a developability term to encourage the Gaussian curvature toward 0 while ensuring fidelity to the input points. Noticing that the Gaussian curvature is non-zero at tip points, we introduce a double-trough curve to tolerate the existence of these tip points. Furthermore, we develop a dynamic sampling strategy to deal with situations where the given points are incomplete or too sparse. Since our resulting neural SDFs can clearly manifest sharp feature points/lines, one can easily extract the feature-aligned triangle mesh from the SDF and then decompose it into smooth surface patches, greatly reducing the difficulty of recovering the parametric CAD design. A comprehensive comparison with existing state-of-the-art methods shows the significant advantage of our approach in reconstructing faithful CAD shapes.
D3Former: Jointly Learning Repeatable Dense Detectors and Feature-enhanced Descriptors via Saliency-guided Transformer
Dec 20, 2023Establishing accurate and representative matches is a crucial step in addressing the point cloud registration problem. A commonly employed approach involves detecting keypoints with salient geometric features and subsequently mapping these keypoints from one frame of the point cloud to another. However, methods within this category are hampered by the repeatability of the sampled keypoints. In this paper, we introduce a saliency-guided trans\textbf{former}, referred to as \textit{D3Former}, which entails the joint learning of repeatable \textbf{D}ense \textbf{D}etectors and feature-enhanced \textbf{D}escriptors. The model comprises a Feature Enhancement Descriptor Learning (FEDL) module and a Repetitive Keypoints Detector Learning (RKDL) module. The FEDL module utilizes a region attention mechanism to enhance feature distinctiveness, while the RKDL module focuses on detecting repeatable keypoints to enhance matching capabilities. Extensive experimental results on challenging indoor and outdoor benchmarks demonstrate that our proposed method consistently outperforms state-of-the-art point cloud matching methods. Notably, tests on 3DLoMatch, even with a low overlap ratio, show that our method consistently outperforms recently published approaches such as RoReg and RoITr. For instance, with the number of extracted keypoints reduced to 250, the registration recall scores for RoReg, RoITr, and our method are 64.3\%, 73.6\%, and 76.5\%, respectively.
OAAFormer: Robust and Efficient Point Cloud Registration Through Overlapping-Aware Attention in Transformer
Oct 15, 2023



In the domain of point cloud registration, the coarse-to-fine feature matching paradigm has received substantial attention owing to its impressive performance. This paradigm involves a two-step process: first, the extraction of multi-level features, and subsequently, the propagation of correspondences from coarse to fine levels. Nonetheless, this paradigm exhibits two notable limitations.Firstly, the utilization of the Dual Softmax operation has the potential to promote one-to-one correspondences between superpoints, inadvertently excluding valuable correspondences. This propensity arises from the fact that a source superpoint typically maintains associations with multiple target superpoints. Secondly, it is imperative to closely examine the overlapping areas between point clouds, as only correspondences within these regions decisively determine the actual transformation. Based on these considerations, we propose {\em OAAFormer} to enhance correspondence quality. On one hand, we introduce a soft matching mechanism, facilitating the propagation of potentially valuable correspondences from coarse to fine levels. Additionally, we integrate an overlapping region detection module to minimize mismatches to the greatest extent possible. Furthermore, we introduce a region-wise attention module with linear complexity during the fine-level matching phase, designed to enhance the discriminative capabilities of the extracted features. Tests on the challenging 3DLoMatch benchmark demonstrate that our approach leads to a substantial increase of about 7\% in the inlier ratio, as well as an enhancement of 2-4\% in registration recall. =
Mesh-MLP: An all-MLP Architecture for Mesh Classification and Semantic Segmentation
Jun 08, 2023



With the rapid development of geometric deep learning techniques, many mesh-based convolutional operators have been proposed to bridge irregular mesh structures and popular backbone networks. In this paper, we show that while convolutions are helpful, a simple architecture based exclusively on multi-layer perceptrons (MLPs) is competent enough to deal with mesh classification and semantic segmentation. Our new network architecture, named Mesh-MLP, takes mesh vertices equipped with the heat kernel signature (HKS) and dihedral angles as the input, replaces the convolution module of a ResNet with Multi-layer Perceptron (MLP), and utilizes layer normalization (LN) to perform the normalization of the layers. The all-MLP architecture operates in an end-to-end fashion and does not include a pooling module. Extensive experimental results on the mesh classification/segmentation tasks validate the effectiveness of the all-MLP architecture.
Laplacian2Mesh: Laplacian-Based Mesh Understanding
Feb 01, 2022Geometric deep learning has sparked a rising interest in computer graphics to perform shape understanding tasks, such as shape classification and semantic segmentation on three-dimensional (3D) geometric surfaces. Previous works explored the significant direction by defining the operations of convolution and pooling on triangle meshes, but most methods explicitly utilized the graph connection structure of the mesh. Motivated by the geometric spectral surface reconstruction theory, we introduce a novel and flexible convolutional neural network (CNN) model, called Laplacian2Mesh, for 3D triangle mesh, which maps the features of mesh in the Euclidean space to the multi-dimensional Laplacian-Beltrami space, which is similar to the multi-resolution input in 2D CNN. Mesh pooling is applied to expand the receptive field of the network by the multi-space transformation of Laplacian which retains the surface topology, and channel self-attention convolutions are applied in the new space. Since implicitly using the intrinsic geodesic connections of the mesh through the adjacency matrix, we do not consider the number of the neighbors of the vertices, thereby mesh data with different numbers of vertices can be input. Experiments on various learning tasks applied to 3D meshes demonstrate the effectiveness and efficiency of Laplacian2Mesh.
Neural-IMLS: Learning Implicit Moving Least-Squares for Surface Reconstruction from Unoriented Point clouds
Sep 09, 2021
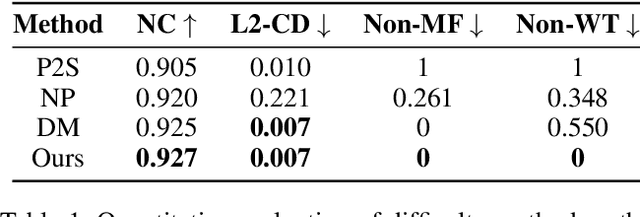

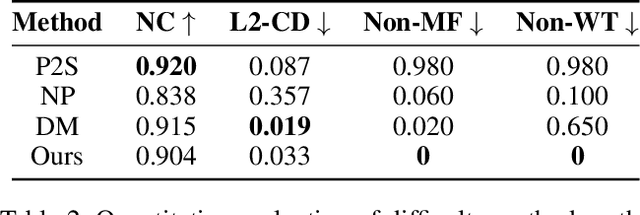
Surface reconstruction from noisy, non-uniformly, and unoriented point clouds is a fascinating yet difficult problem in computer vision and computer graphics. In this paper, we propose Neural-IMLS, a novel approach that learning noise-resistant signed distance function (SDF) for reconstruction. Instead of explicitly learning priors with the ground-truth signed distance values, our method learns the SDF from raw point clouds directly in a self-supervised fashion by minimizing the loss between the couple of SDFs, one obtained by the implicit moving least-square function (IMLS) and the other by our network. Finally, a watertight and smooth 2-manifold triangle mesh is yielded by running Marching Cubes. We conduct extensive experiments on various benchmarks to demonstrate the performance of Neural-IMLS, especially for point clouds with noise.
Efficient refinements on YOLOv3 for real-time detection and assessment of diabetic foot Wagner grades
Jun 04, 2020



Currently, the screening of Wagner grades of diabetic feet (DF) still relies on professional podiatrists. However, in less-developed countries, podiatrists are scarce, which led to the majority of undiagnosed patients. In this study, we proposed the real-time detection and location method for Wagner grades of DF based on refinements on YOLOv3. We collected 2,688 data samples and implemented several methods, such as a visual coherent image mixup, label smoothing, and training scheduler revamping, based on the ablation study. The experimental results suggested that the refinements on YOLOv3 achieved an accuracy of 91.95% and the inference speed of a single picture reaches 31ms with the NVIDIA Tesla V100. To test the performance of the model on a smartphone, we deployed the refinements on YOLOv3 models on an Android 9 system smartphone. This work has the potential to lead to a paradigm shift for clinical treatment of the DF in the future, to provide an effective healthcare solution for DF tissue analysis and healing status.