 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefracGS: Novel View Synthesis Through Refractive Water Surfaces with 3D Gaussian Ray Tracing
Mar 23, 2026Novel view synthesis (NVS) through non-planar refractive surfaces presents fundamental challenges due to severe, spatially varying optical distortions. While recent representations like NeRF and 3D Gaussian Splatting (3DGS) excel at NVS, their assumption of straight-line ray propagation fails under these conditions, leading to significant artifacts. To overcome this limitation, we introduce RefracGS, a framework that jointly reconstructs the refractive water surface and the scene beneath the interface. Our key insight is to explicitly decouple the refractive boundary from the target objects: the refractive surface is modeled via a neural height field, capturing wave geometry, while the underlying scene is represented as a 3D Gaussian field. We formulate a refraction-aware Gaussian ray tracing approach that accurately computes non-linear ray trajectories using Snell's law and efficiently renders the underlying Gaussian field while backpropagating the loss gradients to the parameterized refractive surface. Through end-to-end joint optimization of both representations, our method ensures high-fidelity NVS and view-consistent surface recovery. Experiments on both synthetic and real-world scenes with complex waves demonstrate that RefracGS outperforms prior refractive methods in visual quality, while achieving 15x faster training and real-time rendering at 200 FPS. The project page for RefracGS is available at https://yimgshao.github.io/refracgs/.
Self-Supervised Continuous Colormap Recovery from a 2D Scalar Field Visualization without a Legend
Jul 28, 2025Recovering a continuous colormap from a single 2D scalar field visualization can be quite challenging, especially in the absence of a corresponding color legend. In this paper, we propose a novel colormap recovery approach that extracts the colormap from a color-encoded 2D scalar field visualization by simultaneously predicting the colormap and underlying data using a decoupling-and-reconstruction strategy. Our approach first separates the input visualization into colormap and data using a decoupling module, then reconstructs the visualization with a differentiable color-mapping module. To guide this process, we design a reconstruction loss between the input and reconstructed visualizations, which serves both as a constraint to ensure strong correlation between colormap and data during training, and as a self-supervised optimizer for fine-tuning the predicted colormap of unseen visualizations during inferencing. To ensure smoothness and correct color ordering in the extracted colormap, we introduce a compact colormap representation using cubic B-spline curves and an associated color order loss. We evaluate our method quantitatively and qualitatively on a synthetic dataset and a collection of real-world visualizations from the VIS30K dataset. Additionally, we demonstrate its utility in two prototype applications -- colormap adjustment and colormap transfer -- and explore its generalization to visualizations with color legends and ones encoded using discrete color palettes.
D3Former: Jointly Learning Repeatable Dense Detectors and Feature-enhanced Descriptors via Saliency-guided Transformer
Dec 20, 2023Establishing accurate and representative matches is a crucial step in addressing the point cloud registration problem. A commonly employed approach involves detecting keypoints with salient geometric features and subsequently mapping these keypoints from one frame of the point cloud to another. However, methods within this category are hampered by the repeatability of the sampled keypoints. In this paper, we introduce a saliency-guided trans\textbf{former}, referred to as \textit{D3Former}, which entails the joint learning of repeatable \textbf{D}ense \textbf{D}etectors and feature-enhanced \textbf{D}escriptors. The model comprises a Feature Enhancement Descriptor Learning (FEDL) module and a Repetitive Keypoints Detector Learning (RKDL) module. The FEDL module utilizes a region attention mechanism to enhance feature distinctiveness, while the RKDL module focuses on detecting repeatable keypoints to enhance matching capabilities. Extensive experimental results on challenging indoor and outdoor benchmarks demonstrate that our proposed method consistently outperforms state-of-the-art point cloud matching methods. Notably, tests on 3DLoMatch, even with a low overlap ratio, show that our method consistently outperforms recently published approaches such as RoReg and RoITr. For instance, with the number of extracted keypoints reduced to 250, the registration recall scores for RoReg, RoITr, and our method are 64.3\%, 73.6\%, and 76.5\%, respectively.
Bundle Optimization for Multi-aspect Embedding
Sep 16, 2017
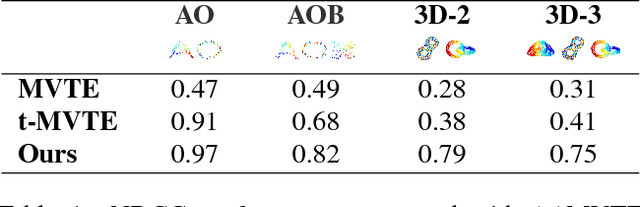
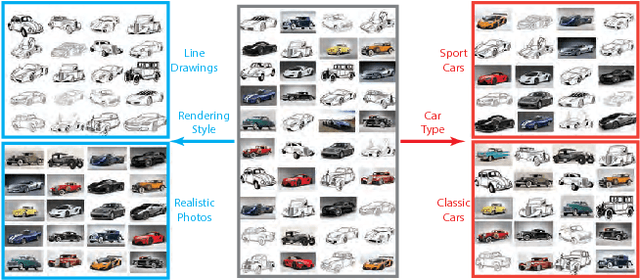
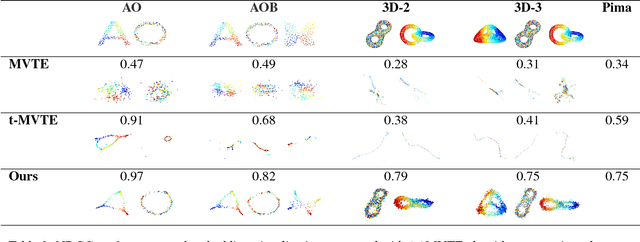
Understanding semantic similarity among images is the core of a wide range of computer vision applications. An important step towards this goal is to collect and learn human perceptions. Interestingly, the semantic context of images is often ambiguous as images can be perceived with emphasis on different aspects, which may be contradictory to each other. In this paper, we present a method for learning the semantic similarity among images, inferring their latent aspects and embedding them into multi-spaces corresponding to their semantic aspects. We consider the multi-embedding problem as an optimization function that evaluates the embedded distances with respect to the qualitative clustering queries. The key idea of our approach is to collect and embed qualitative measures that share the same aspects in bundles. To ensure similarity aspect sharing among multiple measures, image classification queries are presented to, and solved by users. The collected image clusters are then converted into bundles of tuples, which are fed into our bundle optimization algorithm that jointly infers the aspect similarity and multi-aspect embedding. Extensive experimental results show that our approach significantly outperforms state-of-the-art multi-embedding approaches on various datasets, and scales well for large multi-aspect similarity measures.