 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuVAS: Neural Implicit Surfaces for Variational Shape Modeling
Jun 16, 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
Large Images are Gaussians: High-Quality Large Image Representation with Levels of 2D Gaussian Splatting
Feb 13, 2025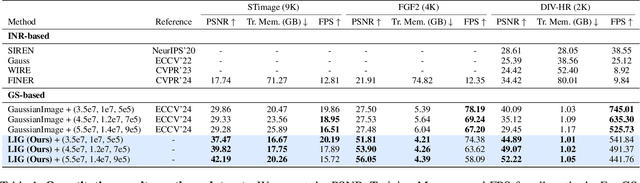
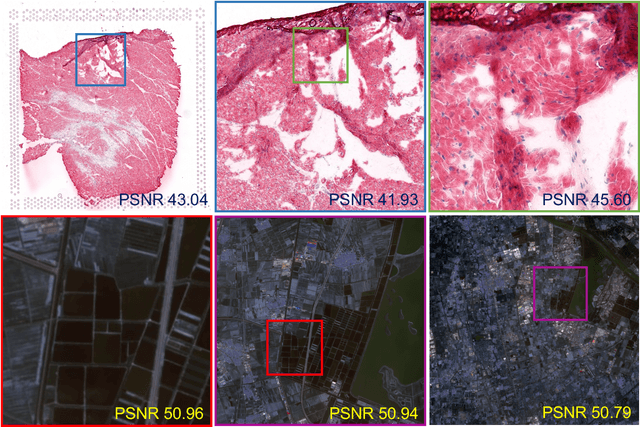
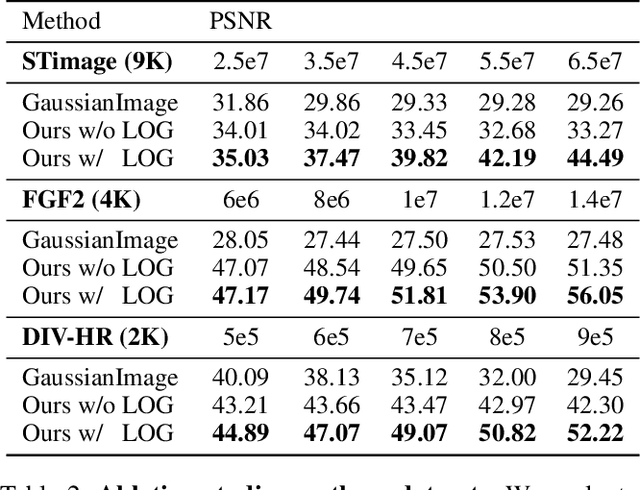
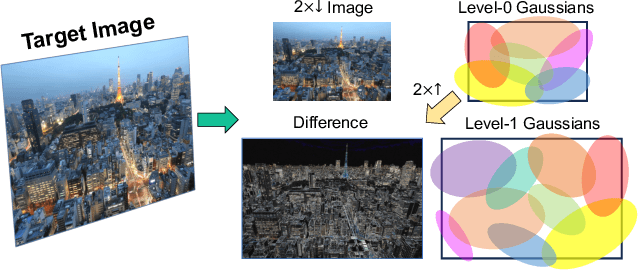
While Implicit Neural Representations (INRs) have demonstrated significant success in image representation, they are often hindered by large training memory and slow decoding speed. Recently, Gaussian Splatting (GS) has emerged as a promising solution in 3D reconstruction due to its high-quality novel view synthesis and rapid rendering capabilities, positioning it as a valuable tool for a broad spectrum of applications. In particular, a GS-based representation, 2DGS, has shown potential for image fitting. In our work, we present \textbf{L}arge \textbf{I}mages are \textbf{G}aussians (\textbf{LIG}), which delves deeper into the application of 2DGS for image representations, addressing the challenge of fitting large images with 2DGS in the situation of numerous Gaussian points, through two distinct modifications: 1) we adopt a variant of representation and optimization strategy, facilitating the fitting of a large number of Gaussian points; 2) we propose a Level-of-Gaussian approach for reconstructing both coarse low-frequency initialization and fine high-frequency details. Consequently, we successfully represent large images as Gaussian points and achieve high-quality large image representation, demonstrating its efficacy across various types of large images. Code is available at {\href{https://github.com/HKU-MedAI/LIG}{https://github.com/HKU-MedAI/LIG}}.
Deformable Endoscopic Tissues Reconstruction with Gaussian Splatting
Jan 21, 2024Surgical 3D reconstruction is a critical area of research in robotic surgery, with recent works adopting variants of dynamic radiance fields to achieve success in 3D reconstruction of deformable tissues from single-viewpoint videos. However, these methods often suffer from time-consuming optimization or inferior quality, limiting their adoption in downstream tasks. Inspired by 3D Gaussian Splatting, a recent trending 3D representation, we present EndoGS, applying Gaussian Splatting for deformable endoscopic tissue reconstruction. Specifically, our approach incorporates deformation fields to handle dynamic scenes, depth-guided supervision to optimize 3D targets with a single viewpoint, and a spatial-temporal weight mask to mitigate tool occlusion. As a result, EndoGS reconstructs and renders high-quality deformable endoscopic tissues from a single-viewpoint video, estimated depth maps, and labeled tool masks. Experiments on DaVinci robotic surgery videos demonstrate that EndoGS achieves superior rendering quality. Code is available at https://github.com/HKU-MedAI/EndoGS.
On Optimal Sampling for Learning SDF Using MLPs Equipped with Positional Encoding
Jan 02, 2024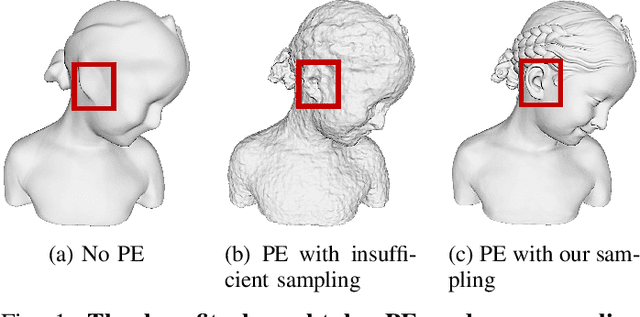
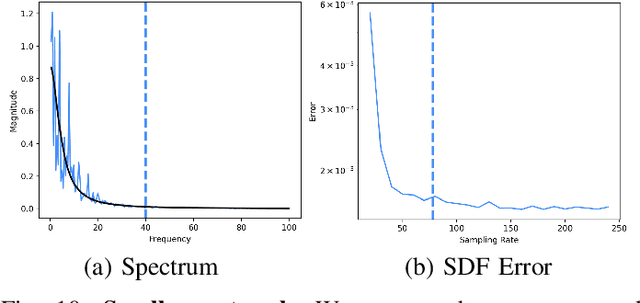
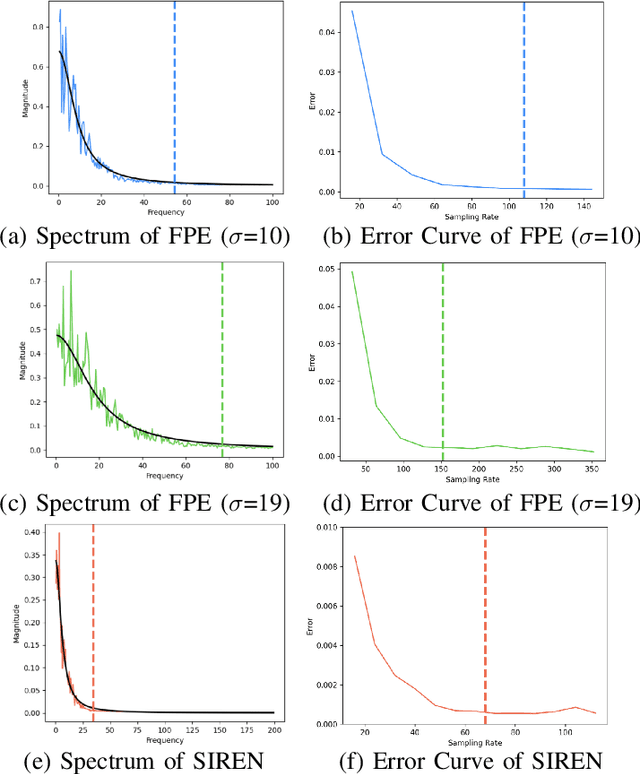
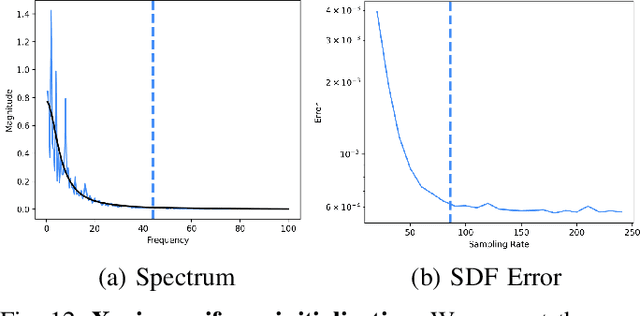
Neural implicit fields, such as the neural signed distance field (SDF) of a shape, have emerged as a powerful representation for many applications, e.g., encoding a 3D shape and performing collision detection. Typically, implicit fields are encoded by Multi-layer Perceptrons (MLP) with positional encoding (PE) to capture high-frequency geometric details. However, a notable side effect of such PE-equipped MLPs is the noisy artifacts present in the learned implicit fields. While increasing the sampling rate could in general mitigate these artifacts, in this paper we aim to explain this adverse phenomenon through the lens of Fourier analysis. We devise a tool to determine the appropriate sampling rate for learning an accurate neural implicit field without undesirable side effects. Specifically, we propose a simple yet effective method to estimate the intrinsic frequency of a given network with randomized weights based on the Fourier analysis of the network's responses. It is observed that a PE-equipped MLP has an intrinsic frequency much higher than the highest frequency component in the PE layer. Sampling against this intrinsic frequency following the Nyquist-Sannon sampling theorem allows us to determine an appropriate training sampling rate. We empirically show in the setting of SDF fitting that this recommended sampling rate is sufficient to secure accurate fitting results, while further increasing the sampling rate would not further noticeably reduce the fitting error. Training PE-equipped MLPs simply with our sampling strategy leads to performances superior to the existing methods.
Progressively-connected Light Field Network for Efficient View Synthesis
Jul 10, 2022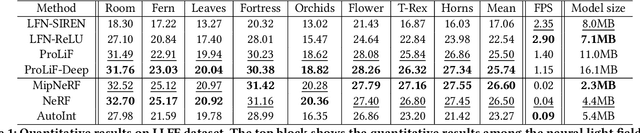


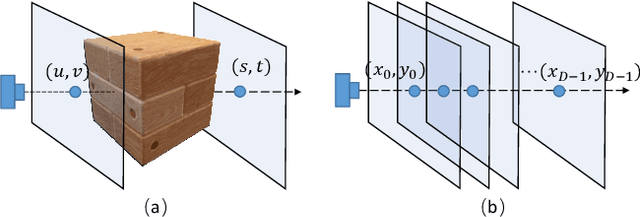
This paper presents a Progressively-connected Light Field network (ProLiF), for the novel view synthesis of complex forward-facing scenes. ProLiF encodes a 4D light field, which allows rendering a large batch of rays in one training step for image- or patch-level losses. Directly learning a neural light field from images has difficulty in rendering multi-view consistent images due to its unawareness of the underlying 3D geometry. To address this problem, we propose a progressive training scheme and regularization losses to infer the underlying geometry during training, both of which enforce the multi-view consistency and thus greatly improves the rendering quality. Experiments demonstrate that our method is able to achieve significantly better rendering quality than the vanilla neural light fields and comparable results to NeRF-like rendering methods on the challenging LLFF dataset and Shiny Object dataset. Moreover, we demonstrate better compatibility with LPIPS loss to achieve robustness to varying light conditions and CLIP loss to control the rendering style of the scene. Project page: https://totoro97.github.io/projects/prolif.