 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
Reconstructing Close Human Interaction with Appearance and Proxemics Reasoning
Jul 03, 2025Due to visual ambiguities and inter-person occlusions, existing human pose estimation methods cannot recover plausible close interactions from in-the-wild videos. Even state-of-the-art large foundation models~(\eg, SAM) cannot accurately distinguish human semantics in such challenging scenarios. In this work, we find that human appearance can provide a straightforward cue to address these obstacles. Based on this observation, we propose a dual-branch optimization framework to reconstruct accurate interactive motions with plausible body contacts constrained by human appearances, social proxemics, and physical laws. Specifically, we first train a diffusion model to learn the human proxemic behavior and pose prior knowledge. The trained network and two optimizable tensors are then incorporated into a dual-branch optimization framework to reconstruct human motions and appearances. Several constraints based on 3D Gaussians, 2D keypoints, and mesh penetrations are also designed to assist the optimization. With the proxemics prior and diverse constraints, our method is capable of estimating accurate interactions from in-the-wild videos captured in complex environments. We further build a dataset with pseudo ground-truth interaction annotations, which may promote future research on pose estimation and human behavior understanding. Experimental results on several benchmarks demonstrate that our method outperforms existing approaches. The code and data are available at https://www.buzhenhuang.com/works/CloseApp.html.
Auto-Connect: Connectivity-Preserving RigFormer with Direct Preference Optimization
Jun 13, 2025



We introduce Auto-Connect, a novel approach for automatic rigging that explicitly preserves skeletal connectivity through a connectivity-preserving tokenization scheme. Unlike previous methods that predict bone positions represented as two joints or first predict points before determining connectivity, our method employs special tokens to define endpoints for each joint's children and for each hierarchical layer, effectively automating connectivity relationships. This approach significantly enhances topological accuracy by integrating connectivity information directly into the prediction framework. To further guarantee high-quality topology, we implement a topology-aware reward function that quantifies topological correctness, which is then utilized in a post-training phase through reward-guided Direct Preference Optimization. Additionally, we incorporate implicit geodesic features for latent top-k bone selection, which substantially improves skinning quality. By leveraging geodesic distance information within the model's latent space, our approach intelligently determines the most influential bones for each vertex, effectively mitigating common skinning artifacts. This combination of connectivity-preserving tokenization, reward-guided fine-tuning, and geodesic-aware bone selection enables our model to consistently generate more anatomically plausible skeletal structures with superior deformation properties.
GarmentX: Autoregressive Parametric Representations for High-Fidelity 3D Garment Generation
Apr 29, 2025This work presents GarmentX, a novel framework for generating diverse, high-fidelity, and wearable 3D garments from a single input image. Traditional garment reconstruction methods directly predict 2D pattern edges and their connectivity, an overly unconstrained approach that often leads to severe self-intersections and physically implausible garment structures. In contrast, GarmentX introduces a structured and editable parametric representation compatible with GarmentCode, ensuring that the decoded sewing patterns always form valid, simulation-ready 3D garments while allowing for intuitive modifications of garment shape and style. To achieve this, we employ a masked autoregressive model that sequentially predicts garment parameters, leveraging autoregressive modeling for structured generation while mitigating inconsistencies in direct pattern prediction. Additionally, we introduce GarmentX dataset, a large-scale dataset of 378,682 garment parameter-image pairs, constructed through an automatic data generation pipeline that synthesizes diverse and high-quality garment images conditioned on parametric garment representations. Through integrating our method with GarmentX dataset, we achieve state-of-the-art performance in geometric fidelity and input image alignment, significantly outperforming prior approaches. We will release GarmentX dataset upon publication.
MAR-3D: Progressive Masked Auto-regressor for High-Resolution 3D Generation
Mar 27, 2025Recent advances in auto-regressive transformers have revolutionized generative modeling across different domains, from language processing to visual generation, demonstrating remarkable capabilities. However, applying these advances to 3D generation presents three key challenges: the unordered nature of 3D data conflicts with sequential next-token prediction paradigm, conventional vector quantization approaches incur substantial compression loss when applied to 3D meshes, and the lack of efficient scaling strategies for higher resolution latent prediction. To address these challenges, we introduce MAR-3D, which integrates a pyramid variational autoencoder with a cascaded masked auto-regressive transformer (Cascaded MAR) for progressive latent upscaling in the continuous space. Our architecture employs random masking during training and auto-regressive denoising in random order during inference, naturally accommodating the unordered property of 3D latent tokens. Additionally, we propose a cascaded training strategy with condition augmentation that enables efficiently up-scale the latent token resolution with fast convergence. Extensive experiments demonstrate that MAR-3D not only achieves superior performance and generalization capabilities compared to existing methods but also exhibits enhanced scaling capabilities compared to joint distribution modeling approaches (e.g., diffusion transformers).
Large Images are Gaussians: High-Quality Large Image Representation with Levels of 2D Gaussian Splatting
Feb 13, 2025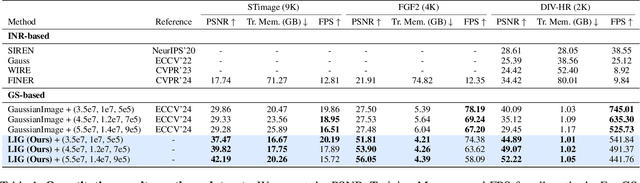
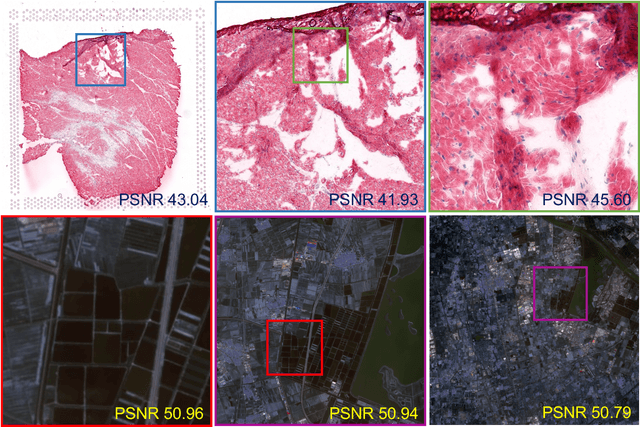
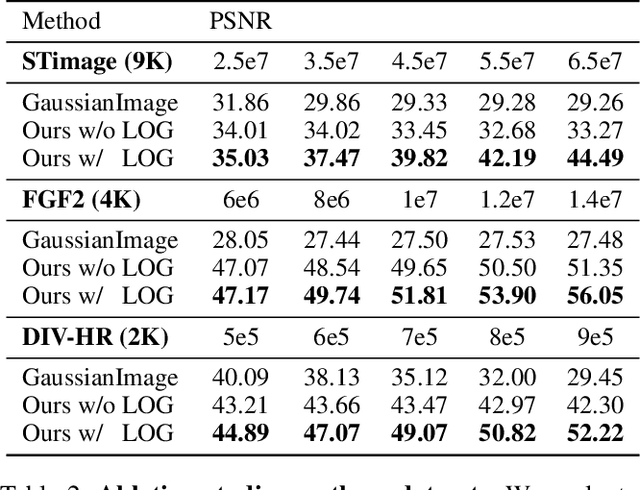
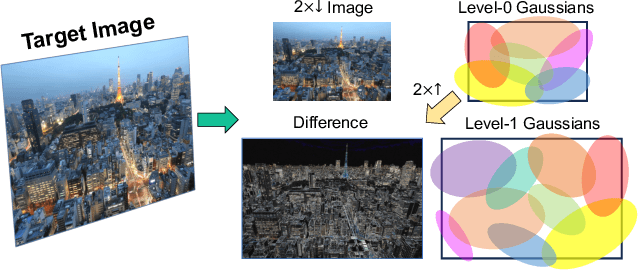
While Implicit Neural Representations (INRs) have demonstrated significant success in image representation, they are often hindered by large training memory and slow decoding speed. Recently, Gaussian Splatting (GS) has emerged as a promising solution in 3D reconstruction due to its high-quality novel view synthesis and rapid rendering capabilities, positioning it as a valuable tool for a broad spectrum of applications. In particular, a GS-based representation, 2DGS, has shown potential for image fitting. In our work, we present \textbf{L}arge \textbf{I}mages are \textbf{G}aussians (\textbf{LIG}), which delves deeper into the application of 2DGS for image representations, addressing the challenge of fitting large images with 2DGS in the situation of numerous Gaussian points, through two distinct modifications: 1) we adopt a variant of representation and optimization strategy, facilitating the fitting of a large number of Gaussian points; 2) we propose a Level-of-Gaussian approach for reconstructing both coarse low-frequency initialization and fine high-frequency details. Consequently, we successfully represent large images as Gaussian points and achieve high-quality large image representation, demonstrating its efficacy across various types of large images. Code is available at {\href{https://github.com/HKU-MedAI/LIG}{https://github.com/HKU-MedAI/LIG}}.
DiHuR: Diffusion-Guided Generalizable Human Reconstruction
Nov 16, 2024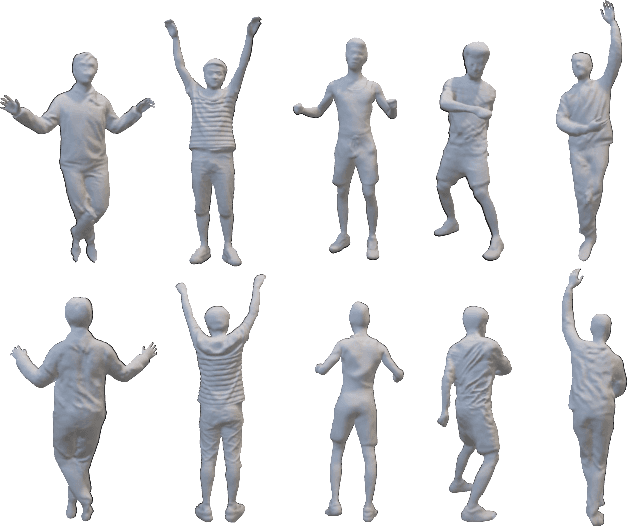

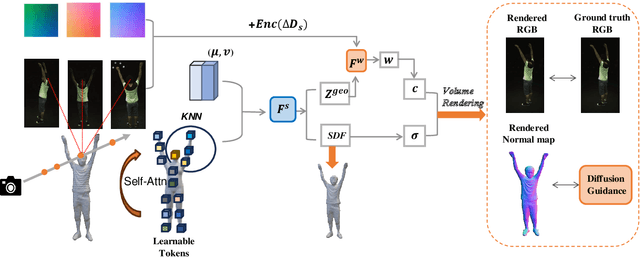

We introduce DiHuR, a novel Diffusion-guided model for generalizable Human 3D Reconstruction and view synthesis from sparse, minimally overlapping images. While existing generalizable human radiance fields excel at novel view synthesis, they often struggle with comprehensive 3D reconstruction. Similarly, directly optimizing implicit Signed Distance Function (SDF) fields from sparse-view images typically yields poor results due to limited overlap. To enhance 3D reconstruction quality, we propose using learnable tokens associated with SMPL vertices to aggregate sparse view features and then to guide SDF prediction. These tokens learn a generalizable prior across different identities in training datasets, leveraging the consistent projection of SMPL vertices onto similar semantic areas across various human identities. This consistency enables effective knowledge transfer to unseen identities during inference. Recognizing SMPL's limitations in capturing clothing details, we incorporate a diffusion model as an additional prior to fill in missing information, particularly for complex clothing geometries. Our method integrates two key priors in a coherent manner: the prior from generalizable feed-forward models and the 2D diffusion prior, and it requires only multi-view image training, without 3D supervision. DiHuR demonstrates superior performance in both within-dataset and cross-dataset generalization settings, as validated on THuman, ZJU-MoCap, and HuMMan datasets compared to existing methods.
SPRMamba: Surgical Phase Recognition for Endoscopic Submucosal Dissection with Mamba
Sep 18, 2024



Endoscopic Submucosal Dissection (ESD) is a minimally invasive procedure initially designed for the treatment of early gastric cancer but is now widely used for various gastrointestinal lesions. Computer-assisted Surgery systems have played a crucial role in improving the precision and safety of ESD procedures, however, their effectiveness is limited by the accurate recognition of surgical phases. The intricate nature of ESD, with different lesion characteristics and tissue structures, presents challenges for real-time surgical phase recognition algorithms. Existing surgical phase recognition algorithms struggle to efficiently capture temporal contexts in video-based scenarios, leading to insufficient performance. To address these issues, we propose SPRMamba, a novel Mamba-based framework for ESD surgical phase recognition. SPRMamba leverages the strengths of Mamba for long-term temporal modeling while introducing the Scaled Residual TranMamba block to enhance the capture of fine-grained details, overcoming the limitations of traditional temporal models like Temporal Convolutional Networks and Transformers. Moreover, a Temporal Sample Strategy is introduced to accelerate the processing, which is essential for real-time phase recognition in clinical settings. Extensive testing on the ESD385 dataset and the cholecystectomy Cholec80 dataset demonstrates that SPRMamba surpasses existing state-of-the-art methods and exhibits greater robustness across various surgical phase recognition tasks.
Generalizable Human Gaussians from Single-View Image
Jun 10, 2024In this work, we tackle the task of learning generalizable 3D human Gaussians from a single image. The main challenge for this task is to recover detailed geometry and appearance, especially for the unobserved regions. To this end, we propose single-view generalizable Human Gaussian model (HGM), a diffusion-guided framework for 3D human modeling from a single image. We design a diffusion-based coarse-to-fine pipeline, where the diffusion model is adapted to refine novel-view images rendered from a coarse human Gaussian model. The refined images are then used together with the input image to learn a refined human Gaussian model. Although effective in hallucinating the unobserved views, the approach may generate unrealistic human pose and shapes due to the lack of supervision. We circumvent this problem by further encoding the geometric priors from SMPL model. Specifically, we propagate geometric features from SMPL volume to the predicted Gaussians via sparse convolution and attention mechanism. We validate our approach on publicly available datasets and demonstrate that it significantly surpasses state-of-the-art methods in terms of PSNR and SSIM. Additionally, our method exhibits strong generalization for in-the-wild images.
Weakly-supervised 3D Pose Transfer with Keypoints
Aug 17, 2023The main challenges of 3D pose transfer are: 1) Lack of paired training data with different characters performing the same pose; 2) Disentangling pose and shape information from the target mesh; 3) Difficulty in applying to meshes with different topologies. We thus propose a novel weakly-supervised keypoint-based framework to overcome these difficulties. Specifically, we use a topology-agnostic keypoint detector with inverse kinematics to compute transformations between the source and target meshes. Our method only requires supervision on the keypoints, can be applied to meshes with different topologies and is shape-invariant for the target which allows extraction of pose-only information from the target meshes without transferring shape information. We further design a cycle reconstruction to perform self-supervised pose transfer without the need for ground truth deformed mesh with the same pose and shape as the target and source, respectively. We evaluate our approach on benchmark human and animal datasets, where we achieve superior performance compared to the state-of-the-art unsupervised approaches and even comparable performance with the fully supervised approaches. We test on the more challenging Mixamo dataset to verify our approach's ability in handling meshes with different topologies and complex clothes. Cross-dataset evaluation further shows the strong generalization ability of our approach.