 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiHuR: Diffusion-Guided Generalizable Human Reconstruction
Paper and Code
Nov 16, 2024

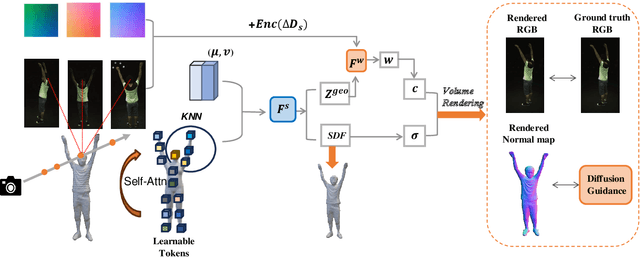

We introduce DiHuR, a novel Diffusion-guided model for generalizable Human 3D Reconstruction and view synthesis from sparse, minimally overlapping images. While existing generalizable human radiance fields excel at novel view synthesis, they often struggle with comprehensive 3D reconstruction. Similarly, directly optimizing implicit Signed Distance Function (SDF) fields from sparse-view images typically yields poor results due to limited overlap. To enhance 3D reconstruction quality, we propose using learnable tokens associated with SMPL vertices to aggregate sparse view features and then to guide SDF prediction. These tokens learn a generalizable prior across different identities in training datasets, leveraging the consistent projection of SMPL vertices onto similar semantic areas across various human identities. This consistency enables effective knowledge transfer to unseen identities during inference. Recognizing SMPL's limitations in capturing clothing details, we incorporate a diffusion model as an additional prior to fill in missing information, particularly for complex clothing geometries. Our method integrates two key priors in a coherent manner: the prior from generalizable feed-forward models and the 2D diffusion prior, and it requires only multi-view image training, without 3D supervision. DiHuR demonstrates superior performance in both within-dataset and cross-dataset generalization settings, as validated on THuman, ZJU-MoCap, and HuMMan datasets compared to existing methods.