 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAR-3D: Progressive Masked Auto-regressor for High-Resolution 3D Generation
Mar 27, 2025Recent advances in auto-regressive transformers have revolutionized generative modeling across different domains, from language processing to visual generation, demonstrating remarkable capabilities. However, applying these advances to 3D generation presents three key challenges: the unordered nature of 3D data conflicts with sequential next-token prediction paradigm, conventional vector quantization approaches incur substantial compression loss when applied to 3D meshes, and the lack of efficient scaling strategies for higher resolution latent prediction. To address these challenges, we introduce MAR-3D, which integrates a pyramid variational autoencoder with a cascaded masked auto-regressive transformer (Cascaded MAR) for progressive latent upscaling in the continuous space. Our architecture employs random masking during training and auto-regressive denoising in random order during inference, naturally accommodating the unordered property of 3D latent tokens. Additionally, we propose a cascaded training strategy with condition augmentation that enables efficiently up-scale the latent token resolution with fast convergence. Extensive experiments demonstrate that MAR-3D not only achieves superior performance and generalization capabilities compared to existing methods but also exhibits enhanced scaling capabilities compared to joint distribution modeling approaches (e.g., diffusion transformers).
Real-Time Neural BRDF with Spherically Distributed Primitives
Oct 12, 2023We propose a novel compact and efficient neural BRDF offering highly versatile material representation, yet with very-light memory and neural computation consumption towards achieving real-time rendering. The results in Figure 1, rendered at full HD resolution on a current desktop machine, show that our system achieves real-time rendering with a wide variety of appearances, which is approached by the following two designs. On the one hand, noting that bidirectional reflectance is distributed in a very sparse high-dimensional subspace, we propose to project the BRDF into two low-dimensional components, i.e., two hemisphere feature-grids for incoming and outgoing directions, respectively. On the other hand, learnable neural reflectance primitives are distributed on our highly-tailored spherical surface grid, which offer informative features for each component and alleviate the conventional heavy feature learning network to a much smaller one, leading to very fast evaluation. These primitives are centrally stored in a codebook and can be shared across multiple grids and even across materials, based on the low-cost indices stored in material-specific spherical surface grids. Our neural BRDF, which is agnostic to the material, provides a unified framework that can represent a variety of materials in consistent manner. Comprehensive experimental results on measured BRDF compression, Monte Carlo simulated BRDF acceleration, and extension to spatially varying effect demonstrate the superior quality and generalizability achieved by the proposed scheme.
CartoonRenderer: An Instance-based Multi-Style Cartoon Image Translator
Nov 14, 2019
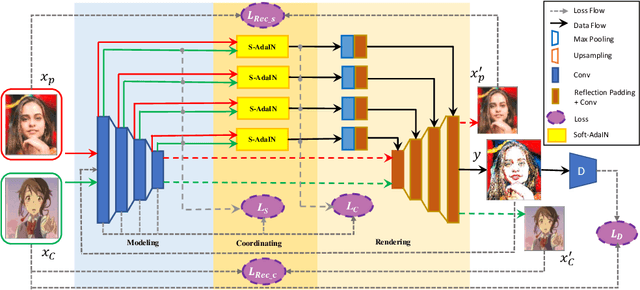

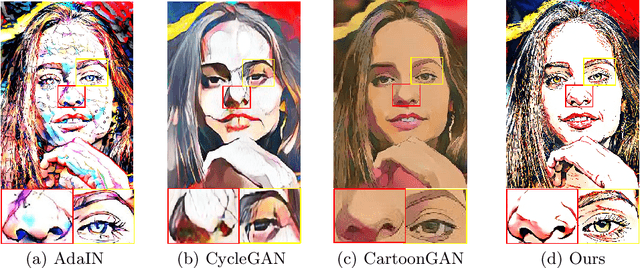
Instance based photo cartoonization is one of the challenging image stylization tasks which aim at transforming realistic photos into cartoon style images while preserving the semantic contents of the photos. State-of-the-art Deep Neural Networks (DNNs) methods still fail to produce satisfactory results with input photos in the wild, especially for photos which have high contrast and full of rich textures. This is due to that: cartoon style images tend to have smooth color regions and emphasized edges which are contradict to realistic photos which require clear semantic contents, i.e., textures, shapes etc. Previous methods have difficulty in satisfying cartoon style textures and preserving semantic contents at the same time. In this work, we propose a novel "CartoonRenderer" framework which utilizing a single trained model to generate multiple cartoon styles. In a nutshell, our method maps photo into a feature model and renders the feature model back into image space. In particular, cartoonization is achieved by conducting some transformation manipulation in the feature space with our proposed Soft-AdaIN. Extensive experimental results show our method produces higher quality cartoon style images than prior arts, with accurate semantic content preservation. In addition, due to the decoupling of whole generating process into "Modeling-Coordinating-Rendering" parts, our method could easily process higher resolution photos, which is intractable for existing methods.
Facial Image Deformation Based on Landmark Detection
Oct 30, 2019
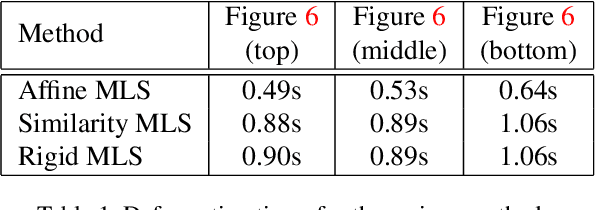
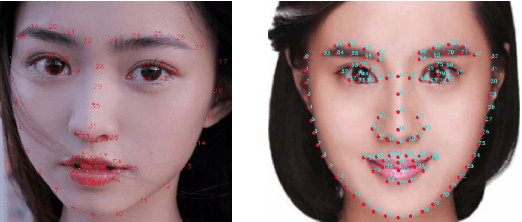
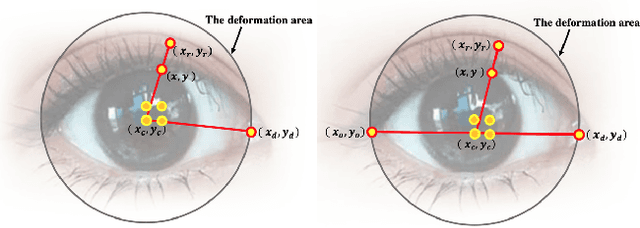
In this work, we use facial landmarks to make the deformation for facial images more authentic and verisimilar. The deformation includes the expansion for eyes and the shrinking for noses, mouths, and cheeks. An advanced 106-point facial landmark detector is utilized to provide control points for deformation. Bilinear interpolation is used in the expansion part and Moving Least Squares methods (MLS) including Affine Deformation, Similarity Deformation and Rigid Deformation are used in the shrinking part. We then compare the running time as well as the quality of deformed images using different MLS methods. The experimental results show that the Rigid Deformation which can keep other parts of the images unchanged performs best even if it takes the longest time.