 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarli: SLO-Aware Co-location of LLM Inference and PEFT-based Finetuning on Model-as-a-Service Platforms
Nov 19, 2025Large language models (LLMs) are increasingly deployed under the Model-as-a-Service (MaaS) paradigm. To meet stringent quality-of-service (QoS) requirements, existing LLM serving systems disaggregate the prefill and decode phases of inference. However, decode instances often experience low GPU utilization due to their memory-bound nature and insufficient batching in dynamic workloads, leaving compute resources underutilized. We introduce Harli, a serving system that improves GPU utilization by co-locating parameter-efficient finetuning (PEFT) tasks with LLM decode instances. PEFT tasks are compute-bound and memory-efficient, making them ideal candidates for safe co-location. Specifically, Harli addresses key challenges--limited memory and unpredictable interference--using three components: a unified memory allocator for runtime memory reuse, a two-stage latency predictor for decode latency modeling, and a QoS-guaranteed throughput-maximizing scheduler for throughput maximization. Experimental results show that Harli improves the finetune throughput by 46.2% on average (up to 92.0%) over state-of-the-art serving systems, while maintaining strict QoS guarantees for inference decode.
Boosting Embodied AI Agents through Perception-Generation Disaggregation and Asynchronous Pipeline Execution
Sep 11, 2025Embodied AI systems operate in dynamic environments, requiring seamless integration of perception and generation modules to process high-frequency input and output demands. Traditional sequential computation patterns, while effective in ensuring accuracy, face significant limitations in achieving the necessary "thinking" frequency for real-world applications. In this work, we present Auras, an algorithm-system co-designed inference framework to optimize the inference frequency of embodied AI agents. Auras disaggregates the perception and generation and provides controlled pipeline parallelism for them to achieve high and stable throughput. Faced with the data staleness problem that appears when the parallelism is increased, Auras establishes a public context for perception and generation to share, thereby promising the accuracy of embodied agents. Experimental results show that Auras improves throughput by 2.54x on average while achieving 102.7% of the original accuracy, demonstrating its efficacy in overcoming the constraints of sequential computation and providing high throughput.
Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Feb 27, 2025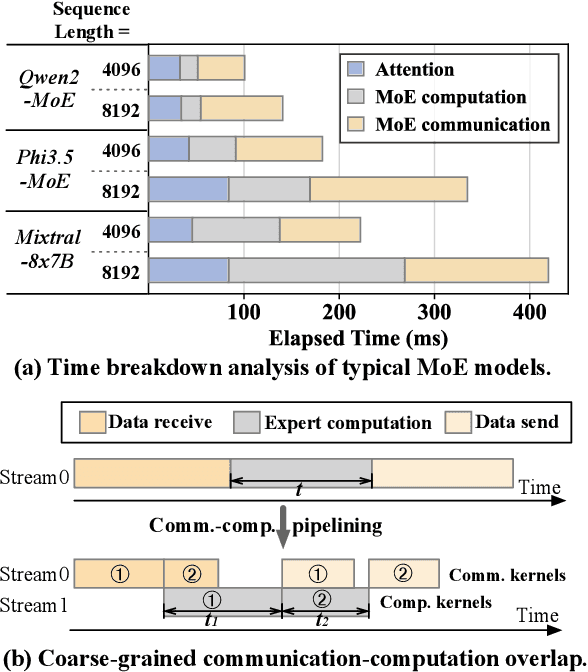



Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillion-plus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy 47% time of the entire model execution with popular models and frameworks. Therefore, existing methods suggest the communication in a MoE layer to be pipelined with the computation for overlapping. However, these coarse grained overlapping schemes introduce a notable impairment of computational efficiency and the latency concealing is sub-optimal. To this end, we present COMET, an optimized MoE system with fine-grained communication-computation overlapping. Leveraging data dependency analysis and task rescheduling, COMET achieves precise fine-grained overlapping of communication and computation. Through adaptive workload assignment, COMET effectively eliminates fine-grained communication bottlenecks and enhances its adaptability across various scenarios. Our evaluation shows that COMET accelerates the execution of a single MoE layer by $1.96\times$ and for end-to-end execution, COMET delivers a $1.71\times$ speedup on average. COMET has been adopted in the production environment of clusters with ten-thousand-scale of GPUs, achieving savings of millions of GPU hours.
A Codesign of Scheduling and Parallelization for Large Model Training in Heterogeneous Clusters
Mar 24, 2024Joint consideration of scheduling and adaptive parallelism offers great opportunities for improving the training efficiency of large models on heterogeneous GPU clusters. However, integrating adaptive parallelism into a cluster scheduler expands the cluster scheduling space. The new space is the product of the original scheduling space and the parallelism exploration space of adaptive parallelism (also a product of pipeline, data, and tensor parallelism). The exponentially enlarged scheduling space and ever-changing optimal parallelism plan from adaptive parallelism together result in the contradiction between low-overhead and accurate performance data acquisition for efficient cluster scheduling. This paper presents Crius, a training system for efficiently scheduling multiple large models with adaptive parallelism in a heterogeneous cluster. Crius proposes a novel scheduling granularity called Cell. It represents a job with deterministic resources and pipeline stages. The exploration space of Cell is shrunk to the product of only data and tensor parallelism, thus exposing the potential for accurate and low-overhead performance estimation. Crius then accurately estimates Cells and efficiently schedules training jobs. When a Cell is selected as a scheduling choice, its represented job runs with the optimal parallelism plan explored. Experimental results show that Crius reduces job completion time by up to 48.9% and schedules large models with up to 1.49x cluster throughput improvement.
Dubhe: Towards Data Unbiasedness with Homomorphic Encryption in Federated Learning Client Selection
Sep 08, 2021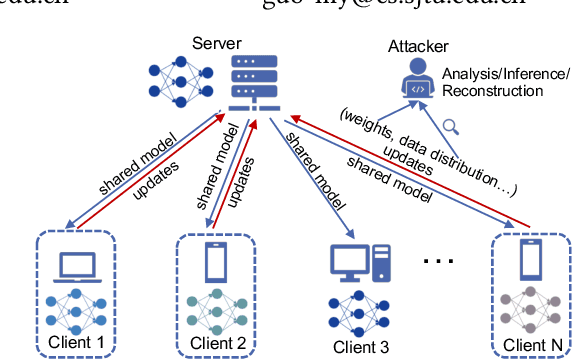
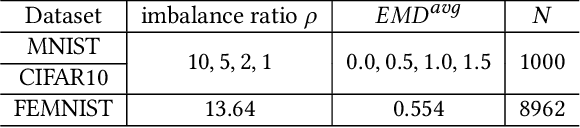
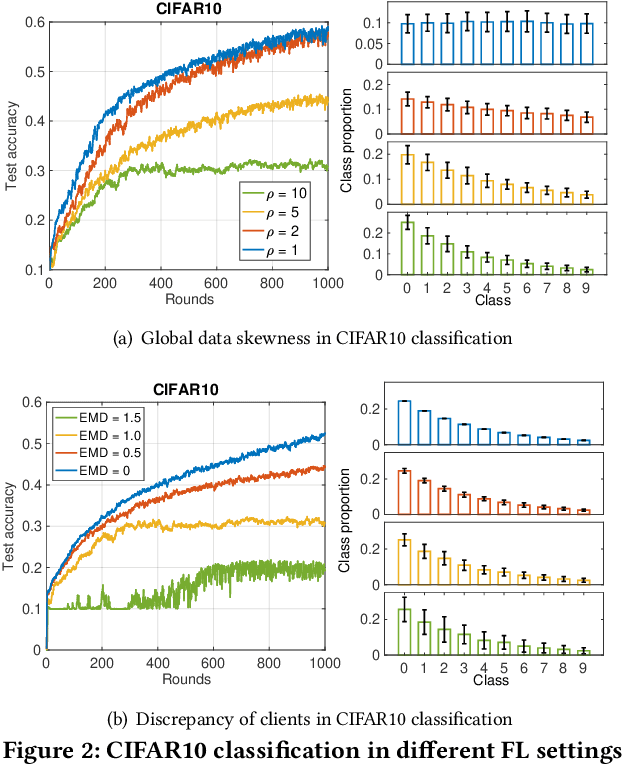
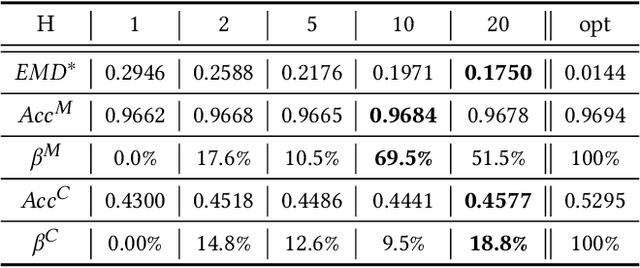
Federated learning (FL) is a distributed machine learning paradigm that allows clients to collaboratively train a model over their own local data. FL promises the privacy of clients and its security can be strengthened by cryptographic methods such as additively homomorphic encryption (HE). However, the efficiency of FL could seriously suffer from the statistical heterogeneity in both the data distribution discrepancy among clients and the global distribution skewness. We mathematically demonstrate the cause of performance degradation in FL and examine the performance of FL over various datasets. To tackle the statistical heterogeneity problem, we propose a pluggable system-level client selection method named Dubhe, which allows clients to proactively participate in training, meanwhile preserving their privacy with the assistance of HE. Experimental results show that Dubhe is comparable with the optimal greedy method on the classification accuracy, with negligible encryption and communication overhead.
Facial Image Deformation Based on Landmark Detection
Oct 30, 2019
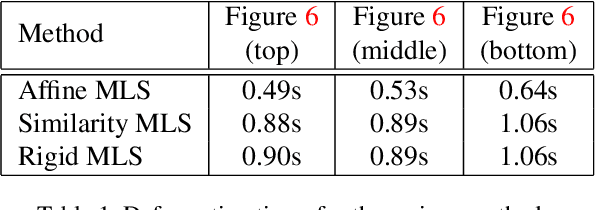
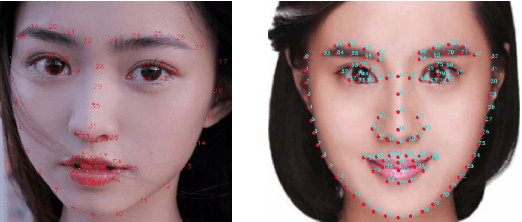
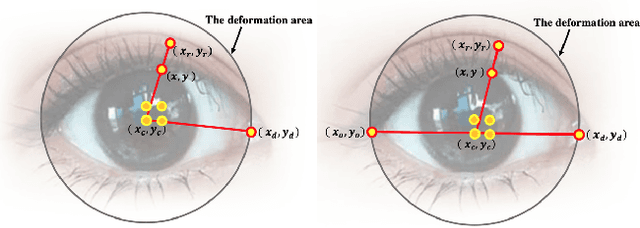
In this work, we use facial landmarks to make the deformation for facial images more authentic and verisimilar. The deformation includes the expansion for eyes and the shrinking for noses, mouths, and cheeks. An advanced 106-point facial landmark detector is utilized to provide control points for deformation. Bilinear interpolation is used in the expansion part and Moving Least Squares methods (MLS) including Affine Deformation, Similarity Deformation and Rigid Deformation are used in the shrinking part. We then compare the running time as well as the quality of deformed images using different MLS methods. The experimental results show that the Rigid Deformation which can keep other parts of the images unchanged performs best even if it takes the longest time.