 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Embodied AI Agents through Perception-Generation Disaggregation and Asynchronous Pipeline Execution
Sep 11, 2025Embodied AI systems operate in dynamic environments, requiring seamless integration of perception and generation modules to process high-frequency input and output demands. Traditional sequential computation patterns, while effective in ensuring accuracy, face significant limitations in achieving the necessary "thinking" frequency for real-world applications. In this work, we present Auras, an algorithm-system co-designed inference framework to optimize the inference frequency of embodied AI agents. Auras disaggregates the perception and generation and provides controlled pipeline parallelism for them to achieve high and stable throughput. Faced with the data staleness problem that appears when the parallelism is increased, Auras establishes a public context for perception and generation to share, thereby promising the accuracy of embodied agents. Experimental results show that Auras improves throughput by 2.54x on average while achieving 102.7% of the original accuracy, demonstrating its efficacy in overcoming the constraints of sequential computation and providing high throughput.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Feb 27, 2025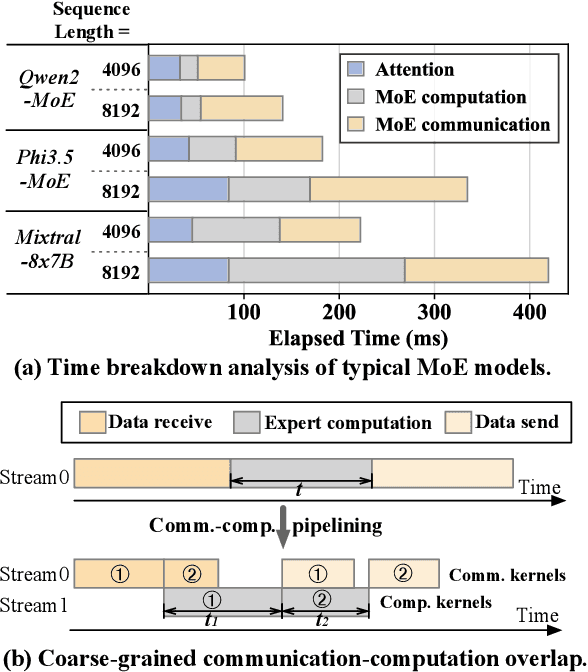



Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillion-plus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy 47% time of the entire model execution with popular models and frameworks. Therefore, existing methods suggest the communication in a MoE layer to be pipelined with the computation for overlapping. However, these coarse grained overlapping schemes introduce a notable impairment of computational efficiency and the latency concealing is sub-optimal. To this end, we present COMET, an optimized MoE system with fine-grained communication-computation overlapping. Leveraging data dependency analysis and task rescheduling, COMET achieves precise fine-grained overlapping of communication and computation. Through adaptive workload assignment, COMET effectively eliminates fine-grained communication bottlenecks and enhances its adaptability across various scenarios. Our evaluation shows that COMET accelerates the execution of a single MoE layer by $1.96\times$ and for end-to-end execution, COMET delivers a $1.71\times$ speedup on average. COMET has been adopted in the production environment of clusters with ten-thousand-scale of GPUs, achieving savings of millions of GPU hours.
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
Oct 28, 2024With the widespread deployment of long-context large language models (LLMs), there has been a growing demand for efficient support of high-throughput inference. However, as the key-value (KV) cache expands with the sequence length, the increasing memory footprint and the need to access it for each token generation both result in low throughput when serving long-context LLMs. While various dynamic sparse attention methods have been proposed to speed up inference while maintaining generation quality, they either fail to sufficiently reduce GPU memory consumption or introduce significant decoding latency by offloading the KV cache to the CPU. We present ShadowKV, a high-throughput long-context LLM inference system that stores the low-rank key cache and offloads the value cache to reduce the memory footprint for larger batch sizes and longer sequences. To minimize decoding latency, ShadowKV employs an accurate KV selection strategy that reconstructs minimal sparse KV pairs on-the-fly. By evaluating ShadowKV on a broad range of benchmarks, including RULER, LongBench, and Needle In A Haystack, and models like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, we demonstrate that it can support up to 6$\times$ larger batch sizes and boost throughput by up to 3.04$\times$ on an A100 GPU without sacrificing accuracy, even surpassing the performance achievable with infinite batch size under the assumption of infinite GPU memory. The code is available at https://github.com/bytedance/ShadowKV.
FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
Jun 12, 2024



Large deep learning models have demonstrated strong ability to solve many tasks across a wide range of applications. Those large models typically require training and inference to be distributed. Tensor parallelism is a common technique partitioning computation of an operation or layer across devices to overcome the memory capacity limitation of a single processor, and/or to accelerate computation to meet a certain latency requirement. However, this kind of parallelism introduces additional communication that might contribute a significant portion of overall runtime. Thus limits scalability of this technique within a group of devices with high speed interconnects, such as GPUs with NVLinks in a node. This paper proposes a novel method, Flux, to significantly hide communication latencies with dependent computations for GPUs. Flux over-decomposes communication and computation operations into much finer-grained operations and further fuses them into a larger kernel to effectively hide communication without compromising kernel efficiency. Flux can potentially overlap up to 96% of communication given a fused kernel. Overall, it can achieve up to 1.24x speedups for training over Megatron-LM on a cluster of 128 GPUs with various GPU generations and interconnects, and up to 1.66x and 1.30x speedups for prefill and decoding inference over vLLM on a cluster with 8 GPUs with various GPU generations and interconnects.
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
May 11, 2023


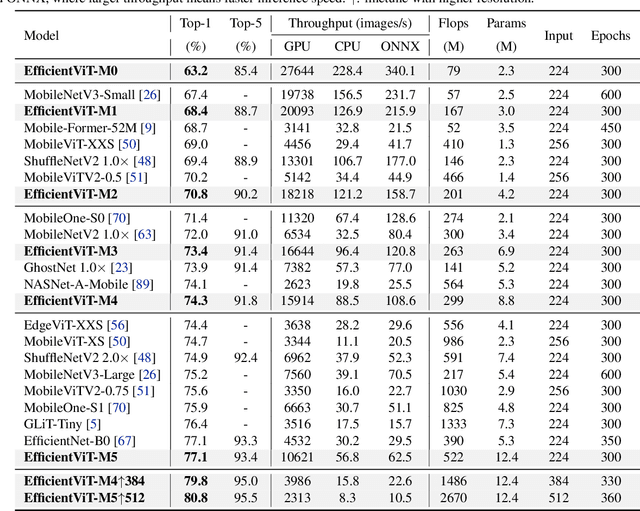
Vision transformers have shown great success due to their high model capabilities. However, their remarkable performance is accompanied by heavy computation costs, which makes them unsuitable for real-time applications. In this paper, we propose a family of high-speed vision transformers named EfficientViT. We find that the speed of existing transformer models is commonly bounded by memory inefficient operations, especially the tensor reshaping and element-wise functions in MHSA. Therefore, we design a new building block with a sandwich layout, i.e., using a single memory-bound MHSA between efficient FFN layers, which improves memory efficiency while enhancing channel communication. Moreover, we discover that the attention maps share high similarities across heads, leading to computational redundancy. To address this, we present a cascaded group attention module feeding attention heads with different splits of the full feature, which not only saves computation cost but also improves attention diversity. Comprehensive experiments demonstrate EfficientViT outperforms existing efficient models, striking a good trade-off between speed and accuracy. For instance, our EfficientViT-M5 surpasses MobileNetV3-Large by 1.9% in accuracy, while getting 40.4% and 45.2% higher throughput on Nvidia V100 GPU and Intel Xeon CPU, respectively. Compared to the recent efficient model MobileViT-XXS, EfficientViT-M2 achieves 1.8% superior accuracy, while running 5.8x/3.7x faster on the GPU/CPU, and 7.4x faster when converted to ONNX format. Code and models are available at https://github.com/microsoft/Cream/tree/main/EfficientViT.
SpaceEvo: Hardware-Friendly Search Space Design for Efficient INT8 Inference
Mar 15, 2023The combination of Neural Architecture Search (NAS) and quantization has proven successful in automatically designing low-FLOPs INT8 quantized neural networks (QNN). However, directly applying NAS to design accurate QNN models that achieve low latency on real-world devices leads to inferior performance. In this work, we find that the poor INT8 latency is due to the quantization-unfriendly issue: the operator and configuration (e.g., channel width) choices in prior art search spaces lead to diverse quantization efficiency and can slow down the INT8 inference speed. To address this challenge, we propose SpaceEvo, an automatic method for designing a dedicated, quantization-friendly search space for each target hardware. The key idea of SpaceEvo is to automatically search hardware-preferred operators and configurations to construct the search space, guided by a metric called Q-T score to quantify how quantization-friendly a candidate search space is. We further train a quantized-for-all supernet over our discovered search space, enabling the searched models to be directly deployed without extra retraining or quantization. Our discovered models establish new SOTA INT8 quantized accuracy under various latency constraints, achieving up to 10.1% accuracy improvement on ImageNet than prior art CNNs under the same latency. Extensive experiments on diverse edge devices demonstrate that SpaceEvo consistently outperforms existing manually-designed search spaces with up to 2.5x faster speed while achieving the same accuracy.
Online Video Streaming Super-Resolution with Adaptive Look-Up Table Fusion
Mar 01, 2023This paper focuses on Super-resolution for online video streaming data. Applying existing super-resolution methods to video streaming data is non-trivial for two reasons. First, to support application with constant interactions, video streaming has a high requirement for latency that most existing methods are less applicable, especially on low-end devices. Second, existing video streaming protocols (e.g., WebRTC) dynamically adapt the video quality to the network condition, thus video streaming in the wild varies greatly under different network bandwidths, which leads to diverse and dynamic degradations. To tackle the above two challenges, we proposed a novel video super-resolution method for online video streaming. First, we incorporate Look-Up Table (LUT) to lightweight convolution modules to achieve real-time latency. Second, for variant degradations, we propose a pixel-level LUT fusion strategy, where a set of LUT bases are built upon state-of-the-art SR networks pre-trained on different degraded data, and those LUT bases are combined with extracted weights from lightweight convolution modules to adaptively handle dynamic degradations. Extensive experiments are conducted on a newly proposed online video streaming dataset named LDV-WebRTC. All the results show that our method significantly outperforms existing LUT-based methods and offers competitive SR performance with faster speed compared to efficient CNN-based methods. Accelerated with our parallel LUT inference, our proposed method can even support online 720P video SR around 100 FPS.
SparDA: Accelerating Dynamic Sparse Deep Neural Networks via Sparse-Dense Transformation
Jan 26, 2023



Due to its high cost-effectiveness, sparsity has become the most important approach for building efficient deep-learning models. However, commodity accelerators are built mainly for efficient dense computation, creating a huge gap for general sparse computation to leverage. Existing solutions have to use time-consuming compiling to improve the efficiency of sparse kernels in an ahead-of-time manner and thus are limited to static sparsity. A wide range of dynamic sparsity opportunities is missed because their sparsity patterns are only known at runtime. This limits the future of building more biological brain-like neural networks that should be dynamically and sparsely activated. In this paper, we bridge the gap between sparse computation and commodity accelerators by proposing a system, called Spider, for efficiently executing deep learning models with dynamic sparsity. We identify an important property called permutation invariant that applies to most deep-learning computations. The property enables Spider (1) to extract dynamic sparsity patterns of tensors that are only known at runtime with little overhead; and (2) to transform the dynamic sparse computation into an equivalent dense computation which has been extremely optimized on commodity accelerators. Extensive evaluation on diverse models shows Spider can extract and transform dynamic sparsity with negligible overhead but brings up to 9.4x speedup over state-of-art solutions.
Online Video Super-Resolution with Convolutional Kernel Bypass Graft
Aug 04, 2022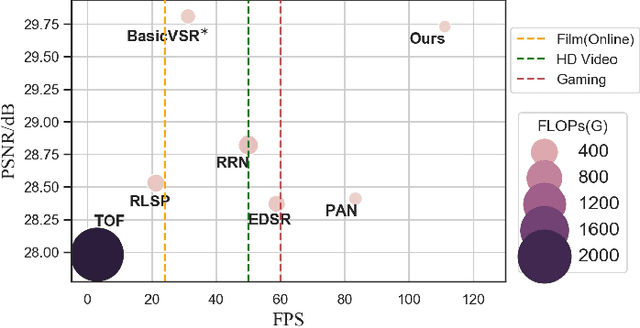


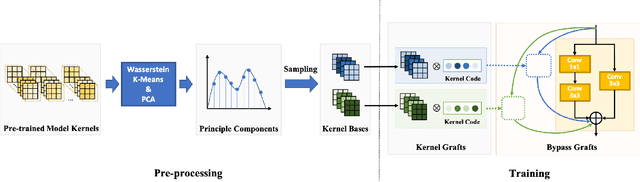
Deep learning-based models have achieved remarkable performance in video super-resolution (VSR) in recent years, but most of these models are less applicable to online video applications. These methods solely consider the distortion quality and ignore crucial requirements for online applications, e.g., low latency and low model complexity. In this paper, we focus on online video transmission, in which VSR algorithms are required to generate high-resolution video sequences frame by frame in real time. To address such challenges, we propose an extremely low-latency VSR algorithm based on a novel kernel knowledge transfer method, named convolutional kernel bypass graft (CKBG). First, we design a lightweight network structure that does not require future frames as inputs and saves extra time costs for caching these frames. Then, our proposed CKBG method enhances this lightweight base model by bypassing the original network with ``kernel grafts'', which are extra convolutional kernels containing the prior knowledge of external pretrained image SR models. In the testing phase, we further accelerate the grafted multi-branch network by converting it into a simple single-path structure. Experiment results show that our proposed method can process online video sequences up to 110 FPS, with very low model complexity and competitive SR performance.