 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Understanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025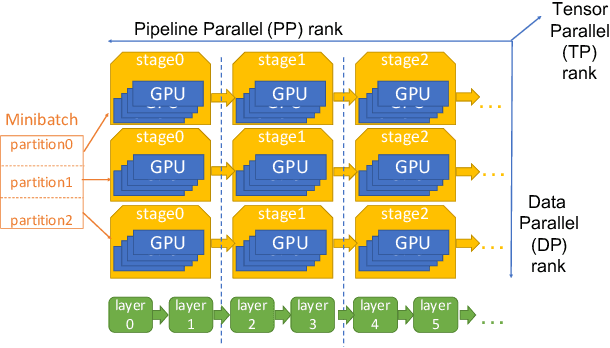

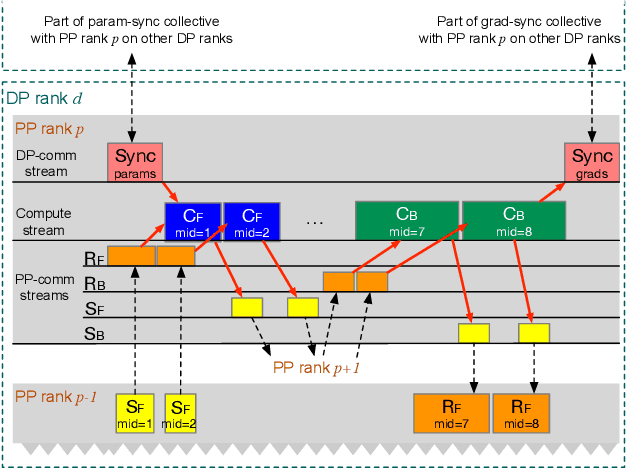
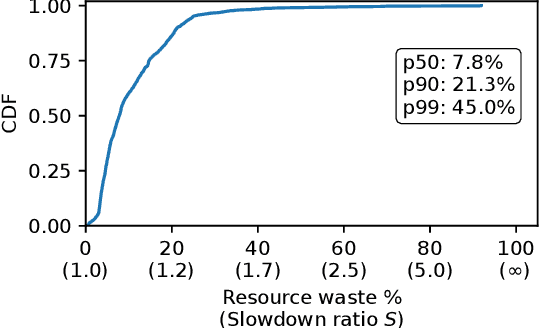
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
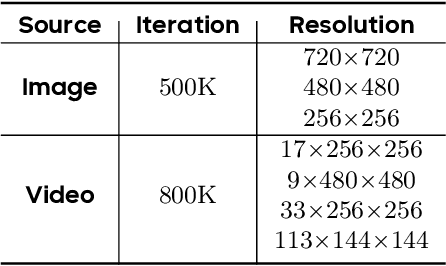
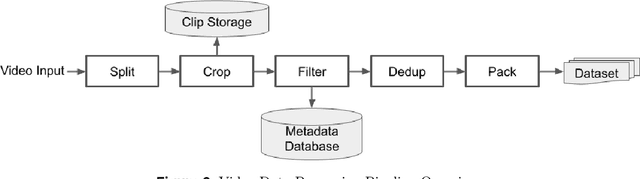

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Nov 04, 2024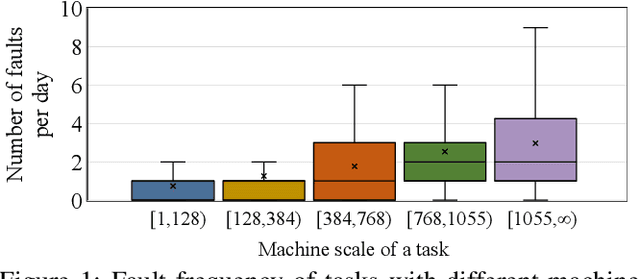
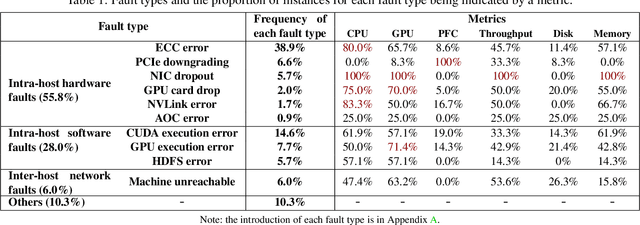
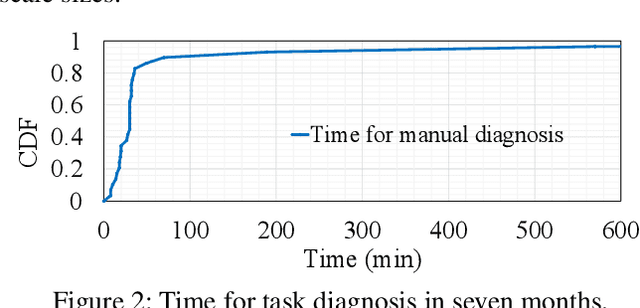
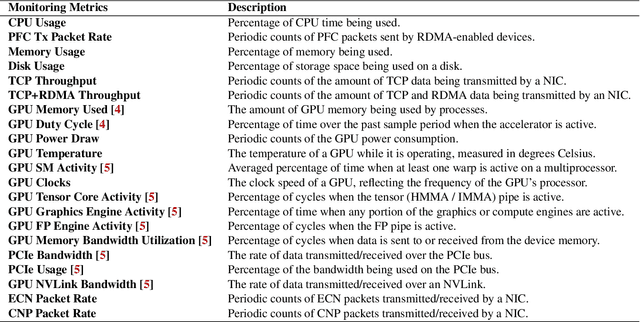
Large-scale distributed model training requires simultaneous training on up to thousands of machines. Faulty machine detection is critical when an unexpected fault occurs in a machine. From our experience, a training task can encounter two faults per day on average, possibly leading to a halt for hours. To address the drawbacks of the time-consuming and labor-intensive manual scrutiny, we propose Minder, an automatic faulty machine detector for distributed training tasks. The key idea of Minder is to automatically and efficiently detect faulty distinctive monitoring metric patterns, which could last for a period before the entire training task comes to a halt. Minder has been deployed in our production environment for over one year, monitoring daily distributed training tasks where each involves up to thousands of machines. In our real-world fault detection scenarios, Minder can accurately and efficiently react to faults within 3.6 seconds on average, with a precision of 0.904 and F1-score of 0.893.
FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
Jun 12, 2024



Large deep learning models have demonstrated strong ability to solve many tasks across a wide range of applications. Those large models typically require training and inference to be distributed. Tensor parallelism is a common technique partitioning computation of an operation or layer across devices to overcome the memory capacity limitation of a single processor, and/or to accelerate computation to meet a certain latency requirement. However, this kind of parallelism introduces additional communication that might contribute a significant portion of overall runtime. Thus limits scalability of this technique within a group of devices with high speed interconnects, such as GPUs with NVLinks in a node. This paper proposes a novel method, Flux, to significantly hide communication latencies with dependent computations for GPUs. Flux over-decomposes communication and computation operations into much finer-grained operations and further fuses them into a larger kernel to effectively hide communication without compromising kernel efficiency. Flux can potentially overlap up to 96% of communication given a fused kernel. Overall, it can achieve up to 1.24x speedups for training over Megatron-LM on a cluster of 128 GPUs with various GPU generations and interconnects, and up to 1.66x and 1.30x speedups for prefill and decoding inference over vLLM on a cluster with 8 GPUs with various GPU generations and interconnects.