 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Reasoning Benchmark May Not Test Reasoning: Revealing Perception Bottleneck in Abstract Reasoning Benchmarks
Dec 24, 2025Reasoning benchmarks such as the Abstraction and Reasoning Corpus (ARC) and ARC-AGI are widely used to assess progress in artificial intelligence and are often interpreted as probes of core, so-called ``fluid'' reasoning abilities. Despite their apparent simplicity for humans, these tasks remain challenging for frontier vision-language models (VLMs), a gap commonly attributed to deficiencies in machine reasoning. We challenge this interpretation and hypothesize that the gap arises primarily from limitations in visual perception rather than from shortcomings in inductive reasoning. To verify this hypothesis, we introduce a two-stage experimental pipeline that explicitly separates perception and reasoning. In the perception stage, each image is independently converted into a natural-language description, while in the reasoning stage a model induces and applies rules using these descriptions. This design prevents leakage of cross-image inductive signals and isolates reasoning from perception bottlenecks. Across three ARC-style datasets, Mini-ARC, ACRE, and Bongard-LOGO, we show that the perception capability is the dominant factor underlying the observed performance gap by comparing the two-stage pipeline with against standard end-to-end one-stage evaluation. Manual inspection of reasoning traces in the VLM outputs further reveals that approximately 80 percent of model failures stem from perception errors. Together, these results demonstrate that ARC-style benchmarks conflate perceptual and reasoning challenges and that observed performance gaps may overstate deficiencies in machine reasoning. Our findings underscore the need for evaluation protocols that disentangle perception from reasoning when assessing progress in machine intelligence.
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025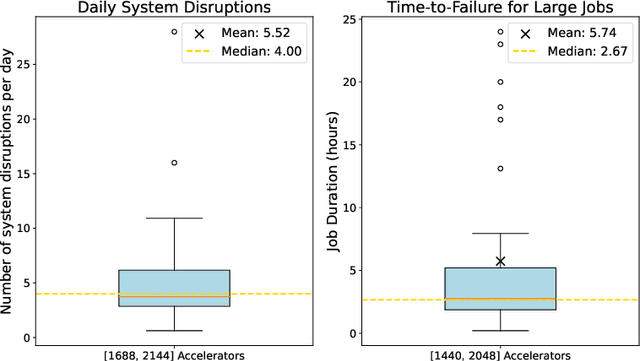

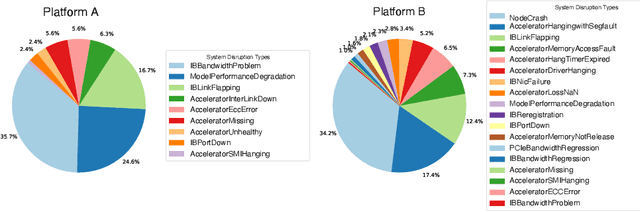

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Through the Judge's Eyes: Inferred Thinking Traces Improve Reliability of LLM Raters
Oct 29, 2025Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
EDGE-GRPO: Entropy-Driven GRPO with Guided Error Correction for Advantage Diversity
Jul 29, 2025Large Language Models (LLMs) have made remarkable progress in enhancing step-by-step reasoning through reinforcement learning. However, the Group Relative Policy Optimization (GRPO) algorithm, which relies on sparse reward rules, often encounters the issue of identical rewards within groups, leading to the advantage collapse problem. Existing works typically address this challenge from two perspectives: enforcing model reflection to enhance response diversity, and introducing internal feedback to augment the training signal (advantage). In this work, we begin by analyzing the limitations of model reflection and investigating the policy entropy of responses at the fine-grained sample level. Based on our experimental findings, we propose the EDGE-GRPO algorithm, which adopts \textbf{E}ntropy-\textbf{D}riven Advantage and \textbf{G}uided \textbf{E}rror Correction to effectively mitigate the problem of advantage collapse. Extensive experiments on several main reasoning benchmarks demonstrate the effectiveness and superiority of our approach. It is available at https://github.com/ZhangXJ199/EDGE-GRPO.
Learning-based Stage Verification System in Manual Assembly Scenarios
Jul 23, 2025In the context of Industry 4.0, effective monitoring of multiple targets and states during assembly processes is crucial, particularly when constrained to using only visual sensors. Traditional methods often rely on either multiple sensor types or complex hardware setups to achieve high accuracy in monitoring, which can be cost-prohibitive and difficult to implement in dynamic industrial environments. This study presents a novel approach that leverages multiple machine learning models to achieve precise monitoring under the limitation of using a minimal number of visual sensors. By integrating state information from identical timestamps, our method detects and confirms the current stage of the assembly process with an average accuracy exceeding 92%. Furthermore, our approach surpasses conventional methods by offering enhanced error detection and visuali-zation capabilities, providing real-time, actionable guidance to operators. This not only improves the accuracy and efficiency of assembly monitoring but also re-duces dependency on expensive hardware solutions, making it a more practical choice for modern industrial applications.
Tracing LLM Reasoning Processes with Strategic Games: A Framework for Planning, Revision, and Resource-Constrained Decision Making
Jun 13, 2025

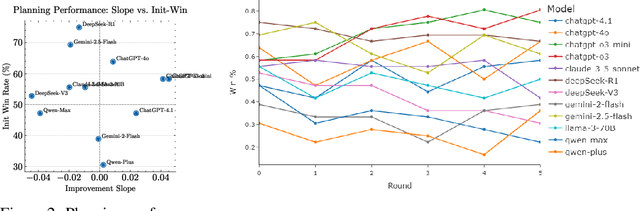
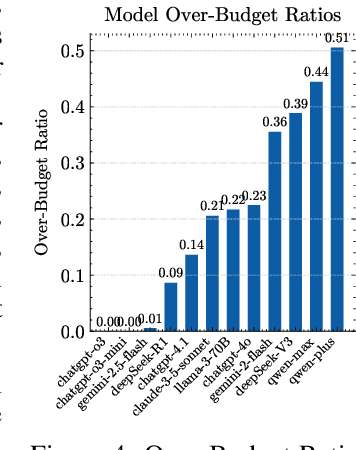
Large language models (LLMs) are increasingly used for tasks that require complex reasoning. Most benchmarks focus on final outcomes but overlook the intermediate reasoning steps - such as planning, revision, and decision making under resource constraints. We argue that measuring these internal processes is essential for understanding model behavior and improving reliability. We propose using strategic games as a natural evaluation environment: closed, rule-based systems with clear states, limited resources, and automatic feedback. We introduce a framework that evaluates LLMs along three core dimensions: planning, revision, and resource-constrained decision making. To operationalize this, we define metrics beyond win rate, including overcorrection risk rate, correction success rate, improvement slope, and over-budget ratio. In 4320 adversarial rounds across 12 leading models, ChatGPT-o3-mini achieves the top composite score, with a win rate of 74.7 percent, a correction success rate of 78.6 percent, and an improvement slope of 0.041. By contrast, Qwen-Plus, despite an overcorrection risk rate of 81.6 percent, wins only 25.6 percent of its matches - primarily due to excessive resource use. We also observe a negative correlation between overcorrection risk rate and correction success rate (Pearson r = -0.51, p = 0.093), suggesting that more frequent edits do not always improve outcomes. Our findings highlight the value of assessing not only what LLMs decide but how they arrive at those decisions
Attention-based Learning for 3D Informative Path Planning
Jun 10, 2025In this work, we propose an attention-based deep reinforcement learning approach to address the adaptive informative path planning (IPP) problem in 3D space, where an aerial robot equipped with a downward-facing sensor must dynamically adjust its 3D position to balance sensing footprint and accuracy, and finally obtain a high-quality belief of an underlying field of interest over a given domain (e.g., presence of specific plants, hazardous gas, geological structures, etc.). In adaptive IPP tasks, the agent is tasked with maximizing information collected under time/distance constraints, continuously adapting its path based on newly acquired sensor data. To this end, we leverage attention mechanisms for their strong ability to capture global spatial dependencies across large action spaces, allowing the agent to learn an implicit estimation of environmental transitions. Our model builds a contextual belief representation over the entire domain, guiding sequential movement decisions that optimize both short- and long-term search objectives. Comparative evaluations against state-of-the-art planners demonstrate that our approach significantly reduces environmental uncertainty within constrained budgets, thus allowing the agent to effectively balance exploration and exploitation. We further show our model generalizes well to environments of varying sizes, highlighting its potential for many real-world applications.
Be.FM: Open Foundation Models for Human Behavior
May 29, 2025



Despite their success in numerous fields, the potential of foundation models for modeling and understanding human behavior remains largely unexplored. We introduce Be.FM, one of the first open foundation models designed for human behavior modeling. Built upon open-source large language models and fine-tuned on a diverse range of behavioral data, Be.FM can be used to understand and predict human decision-making. We construct a comprehensive set of benchmark tasks for testing the capabilities of behavioral foundation models. Our results demonstrate that Be.FM can predict behaviors, infer characteristics of individuals and populations, generate insights about contexts, and apply behavioral science knowledge.
TinyLLaVA-Video-R1: Towards Smaller LMMs for Video Reasoning
Apr 13, 2025Recently, improving the reasoning ability of large multimodal models (LMMs) through reinforcement learning has made great progress. However, most existing works are based on highly reasoning-intensive datasets such as mathematics and code, and researchers generally choose large-scale models as the foundation. We argue that exploring small-scale models' reasoning capabilities remains valuable for researchers with limited computational resources. Moreover, enabling models to explain their reasoning processes on general question-answering datasets is equally meaningful. Therefore, we present the small-scale video reasoning model TinyLLaVA-Video-R1. Based on TinyLLaVA-Video, a traceably trained video understanding model with no more than 4B parameters, it not only demonstrates significantly improved reasoning and thinking capabilities after using reinforcement learning on general Video-QA datasets, but also exhibits the emergent characteristic of "aha moments". Furthermore, we share a series of experimental findings, aiming to provide practical insights for future exploration of video reasoning (thinking) abilities in small-scale models. It is available at https://github.com/ZhangXJ199/TinyLLaVA-Video-R1.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.